
1 信息檢索概述 1.1 傳統檢索方式的缺點 • 文件檢索 操作系統常見的是硬碟文件檢索 文檔檢索:整個文檔打開時已經載入到記憶體了; 缺點:全盤遍歷,慢,記憶體的海量數據 • 資料庫檢索 like "%三星%" 全表遍歷; like "三星%" 最左特性 不會全表遍歷; 無法滿足海量數據下準確迅速的定 ...
1 信息檢索概述
1.1 傳統檢索方式的缺點
• 文件檢索
操作系統常見的是硬碟文件檢索
文檔檢索:整個文檔打開時已經載入到記憶體了;
缺點:全盤遍歷,慢,記憶體的海量數據
• 資料庫檢索
like "%三星%" 全表遍歷;
like "三星%" 最左特性 不會全表遍歷;
無法滿足海量數據下準確迅速的定位
mysql 單表數據量---千萬級
oracle 單表數據量---億級
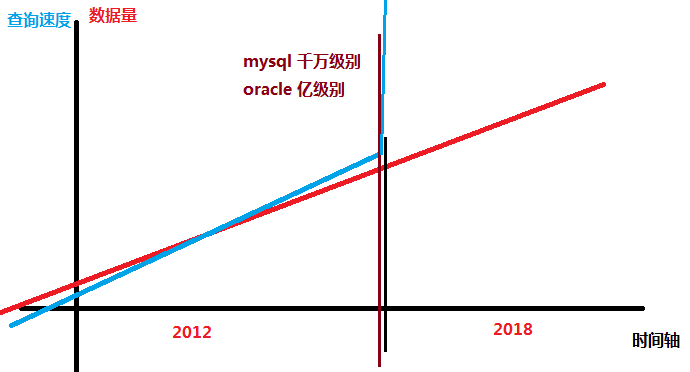
總結:傳統的方式無法滿足檢索的需求(迅速,準確,海量)
2 全文檢索技術(大型互聯網公司的搜索功能都是全文檢索)
2.1 定義:
- 在海量的信息中,通過固定的數據結構引入索引文件,利用對索引文件的處理實現對應數據的快速定位等功能的技術;
- 信息檢索系統(全文檢索技術的應用,搜索引擎百度,google)
- 信息採集:通過爬蟲技術,將公網的海量非結構化數據爬去到本地的分散式存儲系統進行存儲
- 信息整理:非結構化數據無法直接提供使用,需要整理,整理成索引文件
- 信息查詢:通過建立一個搜索的應用,提供用戶的入口進行查詢操作,利用查詢條件搜索索引文件中的有效數據;
2.2結構
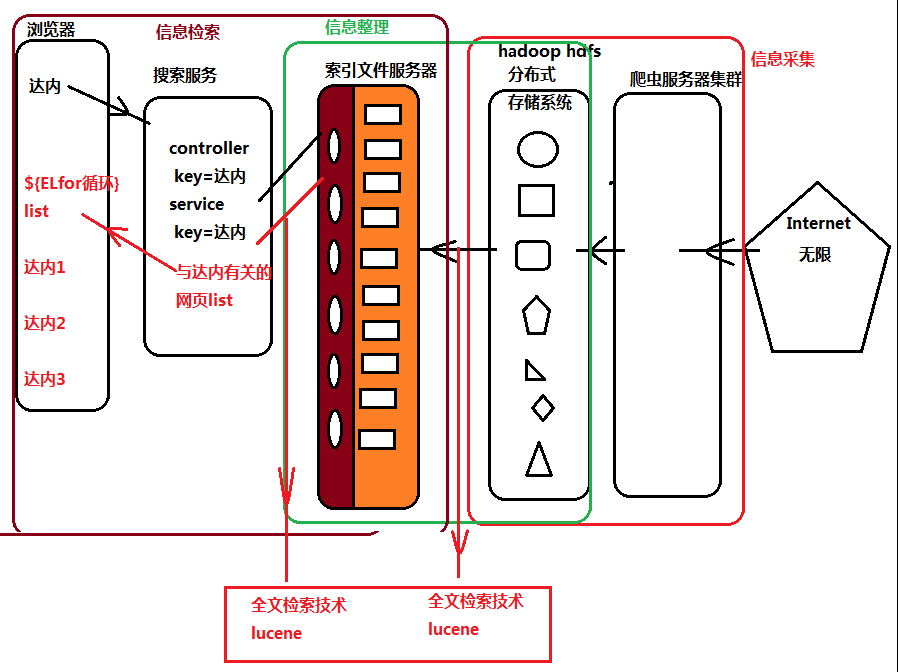
問題:非結構化數據,海量數據如何整理成有結構的索引文件(索引文件到底什麼結構)?
2.3 倒排索引
索引文件,是全文檢索技術的核心內容,創建索引,搜索索引也是核心,搜索在創建之後的;
如何將海量數據計算輸出成有結構的索引文件,需要嚴格規範的計算邏輯-----倒排索引的計算
以網頁為例:
假設爬蟲系統爬去公網海量網頁(2條);利用倒排索引的計算邏輯,將這2個非結構化的網頁信息數據整理成索引文件;
源數據: 標題,時間,作者,留言,內容
網頁1(id=1): 王思聰的IG戰隊獲得LOL世界冠軍,結束長達8年的遺憾
網頁2(id=2): 王思聰又換女朋友了嗎?嗯,天天換.
倒排索引的第一步:計算分詞(數據內容)
分詞:將數據字元串進行切分,形成最小意義的詞語 (不同語言底層實現是不一樣的)
並且每個分詞計算的詞語都會攜帶計算過程中的一些參數
詞語(來源的網頁id,當前網頁中該詞語出現的頻率,出現的位置)
網頁1: 王思聰(1,1,1),IG(1,1,2),戰隊(1,1,3), LOL(1,1,4) 世界(1,1,5)
網頁2: 王思聰(2,1,1),女朋友(2,1,1),天天(2,1,1);
倒排索引第二步:合併分詞結果
合併結果:王思聰([1,2],[1,1],[1,1]),IG(1,1,2),戰隊(1,1,3), LOL(1,1,4) 世界(1,1,5),女朋友(2,1,1),天天(2,1,1);
合併邏輯:所有的網頁的分詞計算結果一定有重覆的分詞辭彙,合併後所有參數也一起合併,結果形成了一批索引結構的數據;
倒排索引第三步:源數據整理document對象
document是索引文件中的文檔對象,最小的數據單位(資料庫中的一行數據)每個document對應一個網頁
倒排索引第四步:形成索引文件
將網頁的數據對象(document)和分詞合併結果(index)一起存儲到存儲位置,形成整體的索引文件
索引文件結構:
數據對象
合併分詞結果

對索引文件中的分詞合併後的數據進行複雜的計算處理,獲取我們想要的數據集合(document的集合)
3 Lucene
3.1介紹
是一個全文檢索引擎工具包,hadoop的創始人Doug Cutting開發,2000年開始,每周花費2天,完成了lucene的第一個版本;引起搜索界的巨大轟動; java開發的工具包;
3.2 特點
- 穩定,索引性能高 (創建和搜索的性能)
- 現代磁碟每小時能索引150G數據(讀寫中)
- 對記憶體要求1MB棧記憶體
- 增量索引和批量索引速度一樣快
- 索引的數據占整體索引文件20%
- 支持多種主流搜索功能.
3.3分詞代碼測試
準備依賴的jar包(lucene6.0)
<!-- lucene查詢擴展轉化器 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>6.0.0</version>
</dependency>
<!-- lucene自帶的智能中文分詞器 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-smartcn</artifactId>
<version>6.0.0</version>
</dependency>
<!-- lucene核心功能包 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>6.0.0</version>
</dependency>
lucene分詞測試
索引的查詢都是基於分詞的計算結果完成的,這種計算分詞的過程叫做詞條化,得到的每一個辭彙稱之為詞項,lucene提供抽象類Analyzer表示分詞器對象,不同的實現類來自不同的開發團隊,實現這個Analyzer完成各自分詞的計算;lucene也提供了多種分詞器計算
- StandardAnalyzer 標準分詞器,分詞英文
- WhitespaceAnalyzer 空格分詞器
- SimpleAnalyzer 簡單分詞器
- SmartChineseAnalyzer 智能中文分詞器
1 package com.jt.test.lucene; 2 3 import java.io.StringReader; 4 5 import org.apache.lucene.analysis.Analyzer; 6 import org.apache.lucene.analysis.TokenStream; 7 import org.apache.lucene.analysis.cn.smart.SmartChineseAnalyzer; 8 import org.apache.lucene.analysis.core.SimpleAnalyzer; 9 import org.apache.lucene.analysis.core.WhitespaceAnalyzer; 10 import org.apache.lucene.analysis.standard.StandardAnalyzer; 11 import org.apache.lucene.analysis.tokenattributes.CharTermAttribute; 12 import org.junit.Test; 13 14 /** 15 *測試不同分詞器對同一個字元串的分詞結果 16 */ 17 public class AnalyzerTest { 18 19 //編寫一個靜態方法, String str,Analayzer a 20 //實現傳入的字元串進行不同分詞器的計算詞項結果 21 public static void printA(Analyzer analyzer,String str) throws Exception{ 22 //org.apache.lucene 23 //獲取str的劉對象 24 StringReader reader=new StringReader(str); 25 //通過字元串流獲取分詞詞項流,每個不同的analyzer實現對象 26 //詞項流的底層計算時不一樣的; 27 //fieldName是當前字元串 代表的document的功能變數名稱/屬性名 28 TokenStream tokenStream = analyzer.tokenStream("name", reader); 29 //對流進行參數的重置reset,才能獲取詞項信息 30 tokenStream.reset(); 31 //獲取詞項的列印結果 32 CharTermAttribute attribute 33 = tokenStream.getAttribute(CharTermAttribute.class); 34 while(tokenStream.incrementToken()){ 35 System.out.println(attribute.toString()); 36 } 37 } 38 @Test 39 public void test() throws Exception{ 40 String str="近日,有網友偶遇諸葛亮王思聰和網紅焦可然一起共進晚餐," 41 + "照片中,焦可然任由王思聰點菜,自己則專註玩手機,"; 42 //創建不同的分詞計算器 43 Analyzer a1=new StandardAnalyzer(); 44 Analyzer a2=new SmartChineseAnalyzer(); 45 Analyzer a3=new SimpleAnalyzer(); 46 Analyzer a4=new WhitespaceAnalyzer(); 47 //調用方法測試不同分詞器的分詞效果 48 System.out.println("*******標準分詞器*******"); 49 AnalyzerTest.printA(a1, str); 50 System.out.println("*******智能中文分詞器*******"); 51 AnalyzerTest.printA(a2, str); 52 System.out.println("*******簡單分詞器*******"); 53 AnalyzerTest.printA(a3, str); 54 System.out.println("*******空格分詞器*******"); 55 AnalyzerTest.printA(a4, str); 56 } 57 }
3.4中文分詞器常用IKAnalyzer
可以實現中文的只能分詞,並且支持擴展,隨著語言的各種發展,可以利用ext.dic文檔補充詞項,也支持停用,stop.dic;
- 實現類的編寫(IKAnalyzer需要自定義實現一些類)
1 package com.jt.lucene.IK; 2 3 import java.io.IOException; 4 5 import org.apache.lucene.analysis.Tokenizer; 6 import org.apache.lucene.analysis.tokenattributes.CharTermAttribute; 7 import org.apache.lucene.analysis.tokenattributes.OffsetAttribute; 8 import org.apache.lucene.analysis.tokenattributes.TypeAttribute; 9 import org.wltea.analyzer.core.IKSegmenter; 10 import org.wltea.analyzer.core.Lexeme; 11 12 public class IKTokenizer6x extends Tokenizer{ 13 //ik分詞器實現 14 private IKSegmenter _IKImplement; 15 //詞元文本屬性 16 private final CharTermAttribute termAtt; 17 //詞元位移屬性 18 private final OffsetAttribute offsetAtt; 19 //詞元分類屬性 20 private final TypeAttribute typeAtt; 21 //記錄最後一個詞元的結束位置 22 private int endPosition; 23 //構造函數,實現最新的Tokenizer 24 public IKTokenizer6x(boolean useSmart){ 25 super(); 26 offsetAtt=addAttribute(OffsetAttribute.class); 27 termAtt=addAttribute(CharTermAttribute.class); 28 typeAtt=addAttribute(TypeAttribute.class); 29 _IKImplement=new IKSegmenter(input, useSmart); 30 } 31 32 @Override 33 public final boolean incrementToken() throws IOException { 34 //清除所有的詞元屬性 35 clearAttributes(); 36 Lexeme nextLexeme=_IKImplement.next(); 37 if(nextLexeme!=null){ 38 //將lexeme轉成attributes 39 termAtt.append(nextLexeme.getLexemeText()); 40 termAtt.setLength(nextLexeme.getLength()); 41 offsetAtt.setOffset(nextLexeme.getBeginPosition(), 42 nextLexeme.getEndPosition()); 43 //記錄分詞的最後位置 44 endPosition=nextLexeme.getEndPosition(); 45 typeAtt.setType(nextLexeme.getLexemeText()); 46 return true;//告知還有下個詞元 47 } 48 return false;//告知詞元輸出完畢 49 } 50 51 @Override 52 public void reset() throws IOException { 53 super.reset(); 54 _IKImplement.reset(input); 55 } 56 57 @Override 58 public final void end(){ 59 int finalOffset = correctOffset(this.endPosition); 60 offsetAtt.setOffset(finalOffset, finalOffset); 61 } 62 63 }
1 package com.jt.lucene.IK; 2 3 import org.apache.lucene.analysis.Analyzer; 4 import org.apache.lucene.analysis.Tokenizer; 5 6 public class IKAnalyzer6x extends Analyzer{ 7 private boolean useSmart; 8 public boolean useSmart(){ 9 return useSmart; 10 } 11 public void setUseSmart(boolean useSmart){ 12 this.useSmart=useSmart; 13 } 14 public IKAnalyzer6x(){ 15 this(false);//IK分詞器lucene analyzer介面實現類,預設細粒度切分演算法 16 } 17 //重寫最新版本createComponents;重載analyzer介面,構造分片語件 18 @Override 19 protected TokenStreamComponents createComponents(String filedName) { 20 Tokenizer _IKTokenizer=new IKTokenizer6x(this.useSmart); 21 return new TokenStreamComponents(_IKTokenizer); 22 } 23 public IKAnalyzer6x(boolean useSmart){ 24 super(); 25 this.useSmart=useSmart; 26 } 27 28 }
- 手動導包 build-path添加依賴的jar包到當前工程 IKAnalyzer2012_u6.jar
- 擴展詞典和停用詞典的使用
<entry key="ext_dict">ext.dic;</entry> <!--用戶可以在這裡配置自己的擴展停止詞字典--> <entry key="ext_stopwords">stopword.dic;</entry> 和配置文件同目錄下準備2個詞典; 確定分詞器使用的代碼編碼字元集與詞典編碼是同一個
4 Lucene創建索引
4.1概念
查詢(Query):對於全文檢索,最終都是使用詞項指向一批document文檔對象的集合,利用對詞項的邏輯計算可以實現不同的查詢功能;查詢時構建的對象就是Query;
文檔(document):是索引文件中的一個最小的數據單位,例如非結構化數據中的網頁將會封裝成一個document存儲在索引文件中,而封裝過程中寫在對象里的所有數據都會根據邏輯進行分詞計算,不同的結構數據源會對應創建具有不同屬性的document對象
文檔的域(Field):每個文檔對象根據不同的數據來源封裝Field的名稱,個數和數據,導致document的結構可能各不相同
詞條化(tokenization):計算分詞過程
詞項(Term):計算分詞的結果每一個詞語都是一個項
4.2 創建一個空的索引文件
- 指向一個索引文件位置
- 生成輸出對象,進行輸出
1 @Test 2 public void emptyIndex() throws Exception{ 3 //指向一個文件夾位置 4 Path path = Paths.get("./index01"); 5 Directory dir=FSDirectory.open(path); 6 //生成一個輸出對象 writer 需要分詞計算器,配置對象 7 Analyzer analyzer=new IKAnalyzer6x(); 8 IndexWriterConfig config=new IndexWriterConfig(analyzer); 9 IndexWriter writer=new IndexWriter(dir,config); 10 //寫出到磁碟,如果沒有攜帶document,生成一個空的index文件 11 writer.commit(); 12 13 }
在索引中創建數據
- 將源數據讀取封裝成document對象,根據源數據的結構定義document的各種field;
1 @Test 2 public void createData() throws Exception{ 3 /* 4 * 1 指向一個索引文件 5 * 2 生成輸出對象 6 * 3 封裝document對象(手動填寫數據) 7 * 4 將document添加到輸出對象索引文件的輸出 8 */ 9 //指向一個文件夾位置 10 Path path = Paths.get("./index02"); 11 Directory dir=FSDirectory.open(path); 12 //生成一個輸出對象 writer 需要分詞計算器,配置對象 13 Analyzer analyzer=new IKAnalyzer6x(); 14 IndexWriterConfig config=new IndexWriterConfig(analyzer); 15 IndexWriter writer=new IndexWriter(dir,config); 16 //構造document對象 17 Document doc1=new Document();//新聞 作者,內容,網站鏈接地址 18 Document doc2=new Document();//商品頁面,title,price,詳情,圖片等 19 doc1.add(new TextField("author", "韓寒", Store.YES)); 20 doc1.add(new TextField("content","我是上海大金子",Store.NO)); 21 doc1.add(new StringField("address", "http://www.news.com", Store.YES)); 22 doc2.add(new TextField("title", "三星(SAMSUNG) 1TB Type-c USB3.1 移動固態硬碟",Store.YES)); 23 doc2.add(new TextField("price","1699",Store.YES)); 24 doc2.add(new TextField("desc","不怕爆炸你就買",Store.YES)); 25 doc2.add(new StringField("image", "image.jt.com/1/1.jpg", 26 Store.YES)); 27 //將2個document對象添加到writer中寫出到索引文件; 28 writer.addDocument(doc1); 29 writer.addDocument(doc2); 30 //寫出到磁碟,如果沒有攜帶document,生成一個空的index文件 31 writer.commit(); 32 }
- 問題一:Store.yes和no的區別是什麼?????
- Store,yes和no的區別在於,創建索引數據,非領導數據是否在輸出到索引時存儲到索引文件,按照類的類型進行計算分詞,一些過大的數據,查詢不需要的數據可以不存儲在索引文件中(例如網頁內容;計算不計算分詞,和存儲索引沒有關係)
- 問題二:StringField和TextField的區別是什麼
- 域的數據需要進行分詞計算如果是字元串有兩種對應的域類型
- 其中StringField表示不對數據進行分詞計算,以整體形勢計算索引
- TextField表示對數據進行分詞計算,以詞形勢計算索引
- 問題三: 問題3:顯然document中的不同域field應該保存不同的數據類型
- 數據中的類型不同,存儲的數據計算邏輯也不同;
- int long double的數字數據如果使用字元串類型保存域
- 只能做到一件事--存儲在索引文件上
- 以上幾個Point類型的域會對數據進行二進位數字的計算;
- 範圍查找,只要利用intPoint,longPoint對應域存儲到document對象後
- 這種類型的數據在分詞計算中就具有了數字的特性 > <
- intPoint只能存儲數值,不存儲數據
- 如果既想記性數字特性的使用,又要存儲數據;需要使用StringField類型
5 Lucene索引的搜索
5.1詞項查詢
單域查詢:查詢條件封裝指定的域,給定Term(詞項),lucene調用搜索api可以根據指定的條件,將所有當前查詢的這個域中的分詞結果進行比對,如果比對成功指向document對象返回數據;
1 @Test 2 public void search() throws Exception{ 3 /* 4 * 1 指向索引文件 5 * 2 構造查詢條件 6 * 3 執行搜索獲取返回數據 7 * 4 從返回數據中獲取document對象 8 */ 9 Path path = Paths.get("./index02"); 10 Directory dir=FSDirectory.open(path); 11 //獲取與輸入流reader,從這裡生產查詢的對象 12 IndexReader reader=DirectoryReader.open(dir); 13 IndexSearcher search=new IndexSearcher(reader); 14 //由於使用的是term查詢,無需包裝analyzer; 15 //構造查詢條件; 16 Term term=new Term("title","三星"); 17 Query termQuery=new TermQuery(term); 18 //查詢,獲取數據 19 TopDocs docs = search.search(termQuery, 10); 20 //將docs轉化成document的獲取邏輯 21 ScoreDoc[] scoreDoc=docs.scoreDocs; 22 for (ScoreDoc sd : scoreDoc) { 23 //沒迴圈一次,都可以獲取document對象一個 24 Document doc=search.doc(sd.doc); 25 System.out.println("author:"+doc.get("author")); 26 System.out.println("content:"+doc.get("content")); 27 System.out.println("address:"+doc.get("address")); 28 System.out.println("title:"+doc.get("title")); 29 System.out.println("image:"+doc.get("image")); 30 System.out.println("price:"+doc.get("price")); 31 System.out.println("rate:"+doc.get("rate")); 32 System.out.println("desc:"+doc.get("desc"));}}
多域查詢:指定的查詢多個field,傳遞參數的字元串會被先進行分詞計算,利用分詞計算的結果(多個詞項),比對所有的域中的詞項,只要滿足一個與對應一個詞項的最小要求就可以拿到當前的document範圍.
1 @Test 2 public void multiQuery() throws Exception{ 3 //使用parser,轉化查詢條件,需要傳遞analyzer,查詢的字元串需要計算分詞 4 Path path=Paths.get("./index02"); 5 Directory dir=FSDirectory.open(path); 6 IndexReader reader=DirectoryReader.open(dir); 7 IndexSearcher search=new IndexSearcher(reader); 8 //用到分詞器計算查詢的條件,必須和創建索引時用的分詞一致; 9 Analyzer analyzer=new IKAnalyzer6x(); 10 //準備查詢的2個域desc title 11 String[] fields={"desc","title"}; 12 //獲取轉化器,將查詢的字元串進行分詞計算,獲取多於查詢的對象query 13 MultiFieldQueryParser parser= 14 new MultiFieldQueryParser(fields,analyzer); 15 Query multiFieldQuery=parser.parse("爆");//三星,爆炸 16 TopDocs docs=search.search(multiFieldQuery, 10); 17 ScoreDoc[] scoreDocs=docs.scoreDocs; 18 for (ScoreDoc scoreDoc : scoreDocs) { 19 Document doc=search.doc(scoreDoc.doc); 20 System.out.println("author:"+doc.get("author")); 21 System.out.println("content:"+doc.get("content")); 22 System.out.println("address:"+doc.get("address")); 23 System.out.println("title:"+doc.get("title")); 24 System.out.println("image:"+doc.get("image")); 25 System.out.println("price:"+doc.get("price")); 26 System.out.println("rate:"+doc.get("rate")); 27 System.out.println("desc:"+doc.get("desc"));}}
布爾查詢:可以封裝多個查詢條件的對象query,由布爾查詢條件實現多個其他查詢的邏輯關係 MUST必須包含 MUST_NOT必須不包含.
對應一個布爾查詢條件,一個沒有must條件的布爾查詢可以有一個或者多個should,有must條件的布爾查詢,should不起作用;
MUST:匹配結果必須包含這個條件
MUST_NOT:匹配結果必須不包含這個條件
SHOULD:沒有must的booleanClause中,可以有1個或者多個should,一旦有must條件,should就沒有作用了
FILTER:和must效果一樣,必須包含,但是查詢過程不參加評分計算.
1 @Test 2 public void booleanQuery() throws Exception{ 3 Path path=Paths.get("./index02"); 4 Directory dir=FSDirectory.open(path); 5 IndexReader reader=DirectoryReader.open(dir); 6 IndexSearcher search=new IndexSearcher(reader); 7 //設置多個查詢的query,可以使任何類型,TermQuery 8 //準備查詢的2個域desc title 9 Analyzer analyzer=new IKAnalyzer6x(); 10 String[] fields={"desc","title"}; 11 //獲取轉化器,將查詢的字元串進行分詞計算,獲取多於查詢的對象query 12 MultiFieldQueryParser parser= 13 new MultiFieldQueryParser(fields,analyzer); 14 Query multiFieldQuery=parser.parse("三星爆炸");//三星,爆炸 15 Query query1=new TermQuery(new Term("title","三星")); 16 Query query2=new TermQuery(new Term("desc","爆炸")); 17 //構造一個布爾的查詢條件 先構造查詢的邏輯對象 18 BooleanClause bc1=new BooleanClause(query1,Occur.MUST); 19 //BooleanClause bc2=new BooleanClause(query2,Occur.MUST_NOT); 20 BooleanClause bc2=new BooleanClause(multiFieldQuery,Occur.FILTER); 21 BooleanQuery boolQuery= 22 new BooleanQuery.Builder().add(bc1).add(bc2).build(); 23 TopDocs docs=search.search(boolQuery, 10); 24 ScoreDoc[] scoreDocs=docs.scoreDocs; 25 for (ScoreDoc scoreDoc : scoreDocs) { 26 Document doc=search.doc(scoreDoc.doc); 27 System.out.println("author:"+doc.get("author")); 28 System.out.println("content:"+doc.get("content")); 29 System.out.println("address:"+doc.get("address")); 30 System.out.println("title:"+doc.get("title")); 31 System.out


