
這兩年微服務越來越火,使用Consul的人也越來越多,這篇文章將結合Consul的官方文檔和自己的實際經驗,談一下Consul做服務發現的方式,文中儘量不依賴具體的框架和開發語言,從原理上進行說明,希望能夠講清楚幾個問題。 ...
從2016年起就開始接觸Consul,使用的主要目的就是做服務發現,後來逐步應用於生產環境,並總結了少許使用經驗。最開始使用Consul的人不多,為了方便交流創建了一個QQ群,這兩年微服務越來越火,使用Consul的人也越來越多,目前群里已有400多人,經常有人問一些問題,比如:
- 服務註冊到節點後,其他節點為什麼沒有同步?
- Client是乾什麼的?(Client有什麼作用?)
- 能不能直接註冊到Server?(是否只有Server節點就夠了?)
- 服務信息是保存在哪裡的?
- 如果節點掛了健康檢查能不能轉移到別的節點?
有些人可能對服務註冊和發現還沒有概念,有些人可能使用過其它服務發現的工具,比如zookeeper,etcd,會有一些先入為主的經驗。這篇文章將結合Consul的官方文檔和自己的實際經驗,談一下Consul做服務發現的方式,文中儘量不依賴具體的框架和開發語言,從原理上進行說明,希望能夠講清楚上邊的幾個問題。
為什麼使用服務發現
防止硬編碼、容災、水平擴縮容、提高運維效率等等,只要你想使用服務發現總能找到合適的理由。
一般的說法是因為使用微服務架構。傳統的單體架構不夠靈活不能很好的適應變化,從而向微服務架構進行轉換,而伴隨著大量服務的出現,管理運維十分不便,於是開始搞一些自動化的策略,服務發現應運而生。所以如果需要使用服務發現,你應該有一些對服務治理的痛點。
但是引入服務發現就可能引入一些技術棧,增加系統總體的複雜度,如果你只有很少的幾個服務,比如10個以下,並且業務不怎麼變化,吞吐量預計也很穩定,可能就沒有必要使用服務發現。
Consul內部原理
下麵這張圖來源於Consul官網,很好的解釋了Consul的工作原理,先大致看一下。
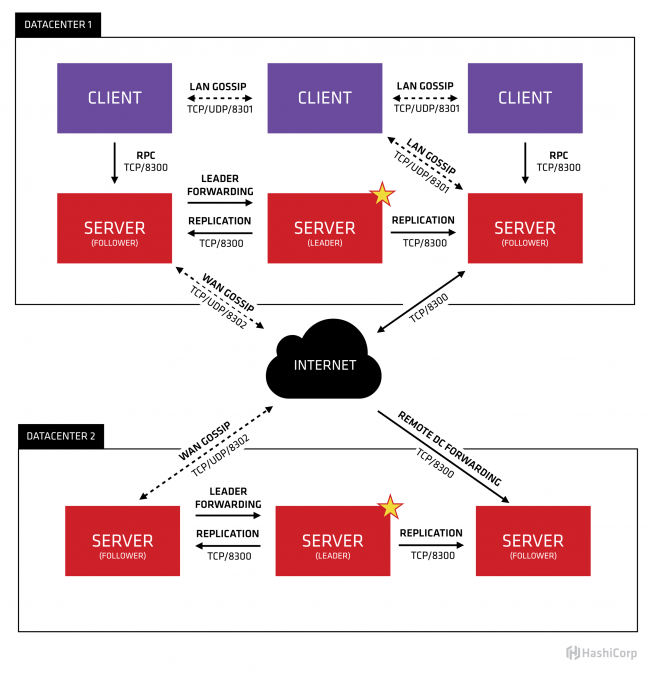
首先Consul支持多數據中心,在上圖中有兩個DataCenter,他們通過Internet互聯,同時請註意為了提高通信效率,只有Server節點才加入跨數據中心的通信。
在單個數據中心中,Consul分為Client和Server兩種節點(所有的節點也被稱為Agent),Server節點保存數據,Client負責健康檢查及轉發數據請求到Server;Server節點有一個Leader和多個Follower,Leader節點會將數據同步到Follower,Server的數量推薦是3個或者5個,在Leader掛掉的時候會啟動選舉機制產生一個新的Leader。
集群內的Consul節點通過gossip協議(流言協議)維護成員關係,也就是說某個節點瞭解集群內現在還有哪些節點,這些節點是Client還是Server。單個數據中心的流言協議同時使用TCP和UDP通信,並且都使用8301埠。跨數據中心的流言協議也同時使用TCP和UDP通信,埠使用8302。
集群內數據的讀寫請求既可以直接發到Server,也可以通過Client使用RPC轉發到Server,請求最終會到達Leader節點,在允許數據輕微陳舊的情況下,讀請求也可以在普通的Server節點完成,集群內數據的讀寫和複製都是通過TCP的8300埠完成。
Consul服務發現原理
下麵這張圖是自己畫的,基本描述了服務發現的完整流程,先大致看一下。
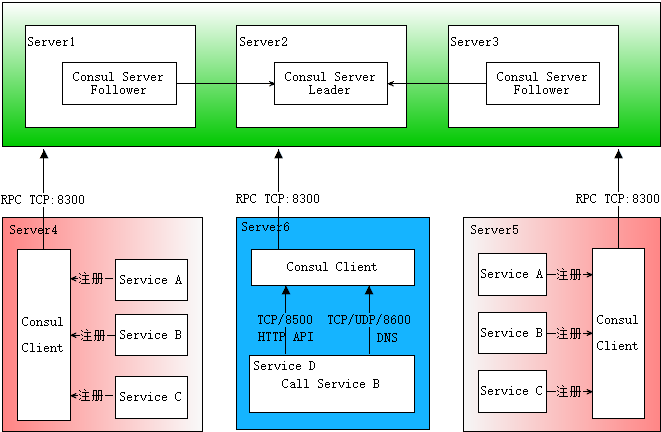
首先需要有一個正常的Consul集群,有Server,有Leader。這裡在伺服器Server1、Server2、Server3上分別部署了Consul Server,假設他們選舉了Server2上的Consul Server節點為Leader。這些伺服器上最好只部署Consul程式,以儘量維護Consul Server的穩定。
然後在伺服器Server4和Server5上通過Consul Client分別註冊Service A、B、C,這裡每個Service分別部署在了兩個伺服器上,這樣可以避免Service的單點問題。服務註冊到Consul可以通過HTTP API(8500埠)的方式,也可以通過Consul配置文件的方式。Consul Client可以認為是無狀態的,它將註冊信息通過RPC轉發到Consul Server,服務信息保存在Server的各個節點中,並且通過Raft實現了強一致性。
最後在伺服器Server6中Program D需要訪問Service B,這時候Program D首先訪問本機Consul Client提供的HTTP API,本機Client會將請求轉發到Consul Server,Consul Server查詢到Service B當前的信息返回,最終Program D拿到了Service B的所有部署的IP和埠,然後就可以選擇Service B的其中一個部署並向其發起請求了。如果服務發現採用的是DNS方式,則Program D中直接使用Service B的服務發現功能變數名稱,功能變數名稱解析請求首先到達本機DNS代理,然後轉發到本機Consul Client,本機Client會將請求轉發到Consul Server,Consul Server查詢到Service B當前的信息返回,最終Program D拿到了Service B的某個部署的IP和埠。
圖中描述的部署架構筆者認為是最普適最簡單的方案,從某些預設配置或設計上看也是官方希望使用者採用的方案,比如8500埠預設監聽127.0.0.1,當然有些同學不贊同,後邊會提到其他方案。
Consul實際使用
為了更快的熟悉Consul的原理及其使用方式,最好還是自己實際測試下。
Consul安裝十分簡單,但是在一臺機器上不方便搭建集群進行測試,使用虛擬機比較重,所以這裡選擇了docker。這裡用了Windows 10,需要是專業版,因為Windows上的Docker依賴Hyper-V,而這個需要專業版才能支持。這裡對於Docker的使用不會做過多的描述,如果遇到相關問題請搜索一下。
安裝Docker
通過這個地址下載安裝:
https://store.docker.com/editions/community/docker-ce-desktop-windows
安裝完成後打開 Windows PowerShell,輸入docker –version,如果正常輸出docker版本就可以了。
啟動Consul集群
在 Windows PowerShell中執行命令拉取最新版本的Consul鏡像:
docker pull consul
然後就可以啟動集群了,這裡啟動4個Consul Agent,3個Server(會選舉出一個leader),1個Client。
#啟動第1個Server節點,集群要求要有3個Server,將容器8500埠映射到主機8900埠,同時開啟管理界面 docker run -d --name=consul1 -p 8900:8500 -e CONSUL_BIND_INTERFACE=eth0 consul agent --server=true --bootstrap-expect=3 --client=0.0.0.0 -ui #啟動第2個Server節點,並加入集群 docker run -d --name=consul2 -e CONSUL_BIND_INTERFACE=eth0 consul agent --server=true --client=0.0.0.0 --join 172.17.0.2 #啟動第3個Server節點,並加入集群 docker run -d --name=consul3 -e CONSUL_BIND_INTERFACE=eth0 consul agent --server=true --client=0.0.0.0 --join 172.17.0.2 #啟動第4個Client節點,並加入集群 docker run -d --name=consul4 -e CONSUL_BIND_INTERFACE=eth0 consul agent --server=false --client=0.0.0.0 --join 172.17.0.2
第1個啟動容器的IP一般是172.17.0.2,後邊啟動的幾個容器IP會排著來:172.17.0.3、172.17.0.4、172.17.0.5。
這些Consul節點在Docker的容器內是互通的,他們通過橋接的模式通信。但是如果主機要訪問容器內的網路,需要做埠映射。在啟動第一個容器時,將Consul的8500埠映射到了主機的8900埠,這樣就可以方便的通過主機的瀏覽器查看集群信息。
進入容器consul1:
docker exec -it consul1 /bin/sh #執行ls後可以看到consul就在根目錄 ls
輸入exit可以跳出容器。
服務註冊
自己寫一個web服務,用最熟悉的開發語言就好了,不過需要在容器中能夠跑起來,可能需要安裝運行環境,比如python、java、.net core等的sdk及web伺服器,需要註意的是Consul的docker鏡像基於alpine系統,具體運行環境的安裝請搜索一下。
這裡寫了一個hello服務,通過配置文件的方式註冊到Consul,服務的相關信息:
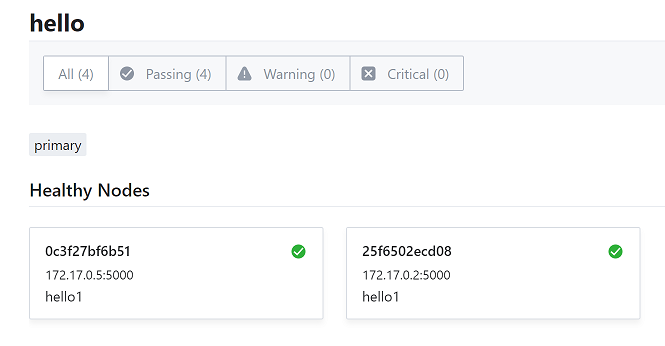
- name:hello,服務名稱,需要能夠區分不同的業務服務,可以部署多份並使用相同的name註冊。
- id:hello1,服務id,在每個節點上需要唯一,如果有重覆會被覆蓋。
- address:172.17.0.5,服務所在機器的地址。
- port:5000,服務的埠。
- 健康檢查地址:http://localhost:5000/,如果返回HTTP狀態碼為200就代表服務健康,每10秒Consul請求一次,請求超時時間為1秒。
請將下麵的內容保存成文件services.json,並上傳到容器的/consul/config目錄中。
{ "services": [ { "id": "hello1", "name": "hello", "tags": [ "primary" ], "address": "172.17.0.5", "port": 5000, "checks": [ { "http": "http://localhost:5000/", "tls_skip_verify": false, "method": "Get", "interval": "10s", "timeout": "1s" } ] } ] }
複製到consul config目錄:
docker cp {這裡請替換成services.json的本地路徑} consul4:/consul/config
重新載入consul配置:
consul reload
然後這個服務就註冊成功了。可以將這個服務部署到多個節點,比如部署到consul1和consul4,並同時運行。
服務發現
服務註冊成功以後,調用方獲取相應服務地址的過程就是服務發現。Consul提供了多種方式。
HTTP API方式:
curl http://127.0.0.1:8500/v1/health/service/hello?passing=false
返回的信息包括註冊的Consul節點信息、服務信息及服務的健康檢查信息。這裡用了一個參數passing=false,會自動過濾掉不健康的服務,包括本身不健康的服務和不健康的Consul節點上的服務,從這個設計上可以看出Consul將服務的狀態綁定到了節點的狀態。
如果服務有多個部署,會返回服務的多條信息,調用方需要決定使用哪個部署,常見的可以隨機或者輪詢。為了提高服務吞吐量,以及減輕Consul的壓力,還可以緩存獲取到的服務節點信息,不過要做好容錯的方案,因為緩存服務部署可能會變得不可用。具體是否緩存需要結合自己的訪問量及容錯規則來確定。
上邊的參數passing預設為false,也就是說不健康的節點也會返回,結合獲取節點全部服務的方法,這裡可以做到獲取全部服務的實時健康狀態,並對不健康的服務進行報警處理。
DNS方式:
hello服務的功能變數名稱是:hello.service.dc1.consul,後邊的service代表服務,固定;dc1是數據中心的名字,可以配置;最後的consul也可以配置。
官方在介紹DNS方式時經常使用dig命令進行測試,但是alpine系統中沒有dig命令,也沒有相關的包可以安裝,但是有人實現了,下載下來解壓到bin目錄就可以了。
curl -L https://github.com/sequenceiq/docker-alpine-dig/releases/download/v9.10.2/dig.tgz|tar -xzv -C /usr/local/bin
然後執行dig命令:
dig @127.0.0.1 -p 8600 hello.service.dc1.consul. ANY
如果報錯:parse of /etc/resolv.conf failed ,請將resolv.conf中的search那行刪掉。
正常的話可以看到返回了服務部署的IP信息,如果有多個部署會看到多個,如果某個部署不健康了會自動剔除(包括部署所在節點不健康的情況)。需要註意這種方式不會返回服務的埠信息。
使用DNS的方式可以在程式中集成一個DNS解析庫,也可以自定義本地的DNS Server。自定義本地DNS Server是指將.consul域的請求全部轉發到Consul Agent,Windows上有DNS Agent,Linux上有Dnsmasq;對於非Consul提供的服務則繼續請求原DNS;使用DNS Server時Consul會隨機返回具體服務的多個部署中的一個,僅能提供簡單的負載均衡。
DNS緩存問題:DNS緩存一般存在於應用程式的網路庫、本地DNS客戶端或者代理,Consul Sever本身可以認為是沒有緩存的(為了提高集群DNS吞吐量,可以設置使用普通Server上的陳舊數據,但影響一般不大),DNS緩存可以減輕Consul Server的訪問壓力,但是也會導致訪問到不可用的服務。使用時需要根據實際訪問量和容錯能力確定DNS緩存方案。
Consul Template
Consul Template是Consul官方提供的一個工具,嚴格的來說不是標準的服務發現方式。這個工具會通過Consul監聽數據變化然後替換模板中使用的標簽,併發布替換後的文件到指定的目錄。在nginx等web伺服器做反向代理和負載均衡時特別有用。
Consul的docker鏡像中沒有集成這個工具,需要自己安裝,比較簡單:
curl -L https://releases.hashicorp.com/consul-template/0.19.5/consul-template_0.19.5_linux_amd64.tgz|tar -xzv -C /usr/local/bin
然後創建一個文件:in.tpl,內容為:
{{ range service "hello" }}
server {{ .Name }}{{ .Address }}:{{ .Port }}{{ end }}
這個標簽會遍歷hello服務的所有部署,並按照指定的格式輸出。在此文件目錄下執行:
nohup consul-template -template "in.tpl:out.txt" &
現在你可以cat out.txt查看根據模板生產的內容,新增或者關閉服務,文件內容會自動更新。
此工具我沒有用在生產環境,詳細使用請訪問:https://github.com/hashicorp/consul-template
節點和服務註銷
節點和服務的註銷可以使用HTTP API:
- 註銷任意節點和服務:/catalog/deregister
- 註銷當前節點的服務:/agent/service/deregister/:service_id
如果某個節點不繼續使用了,也可以在本機使用consul leave命令,或者在其它節點使用consul force-leave 節點Id。
Consul的健康檢查
Consul做服務發現是專業的,健康檢查是其中一項必不可少的功能,其提供Script/TCP/HTTP+Interval,以及TTL等多種方式。服務的健康檢查由服務註冊到的Agent來處理,這個Agent既可以是Client也可以是Server。
很多同學都使用ZooKeeper或者etcd做服務發現,使用Consul時發現節點掛掉後服務的狀態變為不可用了,所以有同學問服務為什麼不在各個節點之間同步?這個根本原因是服務發現的實現原理不同。
Consul與ZooKeeper、etcd的區別
後邊這兩個工具是通過鍵值存儲來實現服務的註冊與發現。
- ZooKeeper利用臨時節點的機制,業務服務啟動時創建臨時節點,節點在服務就在,節點不存在服務就不存在。
- etcd利用TTL機制,業務服務啟動時創建鍵值對,定時更新ttl,ttl過期則服務不可用。
ZooKeeper和etcd的鍵值存儲都是強一致性的,也就是說鍵值對會自動同步到多個節點,只要在某個節點上存在就可以認為對應的業務服務是可用的。
Consul的數據同步也是強一致性的,服務的註冊信息會在Server節點之間同步,相比ZK、etcd,服務的信息還是持久化保存的,即使服務部署不可用了,仍舊可以查詢到這個服務部署。但是業務服務的可用狀態是由註冊到的Agent來維護的,Agent如果不能正常工作了,則無法確定服務的真實狀態,並且Consul是相當穩定了,Agent掛掉的情況下大概率伺服器的狀態也可能是不好的,此時屏蔽掉此節點上的服務是合理的。Consul也確實是這樣設計的,DNS介面會自動屏蔽掛掉節點上的服務,HTTP API也認為掛掉節點上的服務不是passing的。
鑒於Consul健康檢查的這種機制,同時避免單點故障,所有的業務服務應該部署多份,並註冊到不同的Consul節點。部署多份可能會給你的設計帶來一些挑戰,因為調用方同時訪問多個服務實例可能會由於會話不共用導致狀態不一致,這個有許多成熟的解決方案,可以去查詢,這裡不做說明。
健康檢查能不能支持故障轉移?
上邊提到健康檢查是由服務註冊到的Agent來處理的,那麼如果這個Agent掛掉了,會不會有別的Agent來接管健康檢查呢?答案是否定的。
從問題產生的原因來看,在應用於生產環境之前,肯定需要對各種場景進行測試,沒有問題才會上線,所以顯而易見的問題可以屏蔽掉;如果是新版本Consul的BUG導致的,此時需要降級;如果這個BUG是偶發的,那麼只需要將Consul重新拉起來就可以了,這樣比較簡單;如果是硬體、網路或者操作系統故障,那麼節點上服務的可用性也很難保障,不需要別的Agent接管健康檢查。
從實現上看,選擇哪個節點是個問題,這需要實時或準實時同步各個節點的負載狀態,而且由於業務服務運行狀態多變,即使當時選擇出了負載比較輕鬆的節點,無法保證某個時段任務又變得繁重,可能造成新的更大範圍的崩潰。如果原來的節點還要啟動起來,那麼接管的健康檢查是否還要撤銷,如果要,需要記錄服務們最初註冊的節點,然後有一個監聽機制來觸發,如果不要,通過服務發現就會獲取到很多冗餘的信息,並且隨著時間推移,這種數據會越來越多,系統變的無序。
從實際應用看,節點上的服務可能既要被髮現,又要發現別的服務,如果節點掛掉了,僅提供被髮現的功能實際上服務還是不可用的。當然發現別的服務也可以不使用本機節點,可以通過訪問一個Nginx實現的若幹Consul節點的負載均衡來實現,這無疑又引入了新的技術棧。
如果不是上邊提到的問題,或者你可以通過一些方式解決這些問題,健康檢查接管的實現也必然是比較複雜的,因為分散式系統的狀態同步是比較複雜的。同時不要忘了服務部署了多份,掛掉一個不應該影響系統的快速恢復,所以沒必要去做這個接管。
Consul的其它部署架構
如果你實在不想在每個主機部署Consul Client,還有一個多路註冊的方案可供選擇,這是交流群中獲得的思路。

如圖所示,在專門的伺服器上部署Consul Client,然後每個服務都註冊到多個Client,這裡為了避免服務單點問題還是每個服務部署多份,需要服務發現時,程式向一個提供負載均衡的程式發起請求,該程式將請求轉發到某個Consul Client。這種方案需要註意將Consul的8500埠綁定到私網IP上,預設只有127.0.0.1。
這個架構的優勢:
- Consul節點伺服器與應用伺服器隔離,互相干擾少;
- 不用每台主機都部署Consul,方便Consul的集中管理;
- 某個Consul Client掛掉的情況下,註冊到其上的服務仍有機會被訪問到;
但也需要註意其缺點:
- 引入更多技術棧:負載均衡的實現,不僅要考慮Consul Client的負載均衡,還要考慮負載均衡本身的單點問題。
- Client的節點數量:單個Client如果註冊的服務太多,負載較重,需要有個演算法(比如hash一致)合理分配每個Client上的服務數量,以及確定Client的總體數量。
- 服務發現要過濾掉重覆的註冊,因為註冊到了多個節點會認為是多個部署(DNS介面不會有這個問題)。
這個方案其實還可以優化,服務發現使用的負載均衡可以直接代理Server節點,因為相關請求還是會轉發到Server節點,不如直接就發到Server。
是否可以只有Server?
這個問題的答案還是有關服務數量的問題,首先Server的節點數量不是越多越好,3個或者5個是推薦的數量,數量越多數據同步的處理越慢(強一致性);然後每個節點可以註冊的服務數量是有上限的,這個受限於軟硬體的處理能力。所以如果你的服務只有10個左右,只有Server問題是不大的,但是這時候有沒有必要使用Consul呢?因此正常使用Consul的時候還是要有Client才好,這也符合Consul的反熵設計。
大家可以將這個部署架構與前文提到的普世架構對比下,看看哪個更適合自己,或者你有更好的方案歡迎分享出來。
後記
在編寫這篇文章的時候,發現很多地方還不瞭解,很多框架也沒有使用過,增長了不少見識,同時確認了一些之前似是而非的細節,但是文中仍可能有些理解錯誤,或者說的不是很清楚的地方,比如如何結合容器在生產環境使用,歡迎大家加群交流(群號: 234939415)!
我的獨立博客:http://blog.bossma.cn/consul/consul-service-register-and-discovery-style/


