
調度器面對的情形就是這樣, 其任務是在程式之間共用CPU時間, 創造並行執行的錯覺, 該任務分為兩個不同的部分, 其中一個涉及 調度策略 , 另外一個涉及 上下文切換 . 1 背景知識 1.1 什麼是調度器 通常來說,操作系統是應用程式和可用資源之間的媒介。 典型的資源有記憶體和物理設備。但是CPU也 ...
調度器面對的情形就是這樣, 其任務是在程式之間共用CPU時間, 創造並行執行的錯覺, 該任務分為兩個不同的部分, 其中一個涉及調度策略, 另外一個涉及上下文切換.
1 背景知識
1.1 什麼是調度器
通常來說,操作系統是應用程式和可用資源之間的媒介。
典型的資源有記憶體和物理設備。但是CPU也可以認為是一個資源,調度器可以臨時分配一個任務在上面執行(單位是時間片)。調度器使得我們同時執行多個程式成為可能,因此可以與具有各種需求的用戶共用CPU。
內核必須提供一種方法, 在各個進程之間儘可能公平地共用CPU時間, 而同時又要考慮不同的任務優先順序.
調度器的一個重要目標是有效地分配 CPU 時間片,同時提供很好的用戶體驗。調度器還需要面對一些互相衝突的目標,例如既要為關鍵實時任務最小化響應時間, 又要最大限度地提高 CPU 的總體利用率.
調度器的一般原理是, 按所需分配的計算能力, 向系統中每個進程提供最大的公正性, 或者從另外一個角度上說, 他試圖確保沒有進程被虧待.
1.2 調度策略
傳統的Unix操作系統的都奧杜演算法必須實現幾個互相衝突的目標:
- 進程響應時間儘可能快
- 後臺作業的吞吐量儘可能高
- 儘可能避免進程的饑餓現象
- 低優先順序和高優先順序進程的需要儘可能調和等等
調度策略(scheduling policy)的任務就是決定什麼時候以怎麼樣的方式選擇一個新進程占用CPU運行.
傳統操作系統的調度基於分時(time sharing)技術: 多個進程以”時間多路服用”方式運行, 因為CPU的時間被分成”片(slice)”, 給每個可運行進程分配一片CPU時間片, 當然單處理器在任何給定的時刻只能運行一個進程.
如果當前可運行進程的時限(quantum)到期時(即時間片用盡), 而該進程還沒有運行完畢, 進程切換就可以發生.
分時依賴於定時中斷, 因此對進程是透明的, 不需要在承租中插入額外的代碼來保證CPU分時.
調度策略也是根據進程的優先順序對他們進行分類. 有時用複雜的演算法求出進程當前的優先順序, 但最後的結果是相同的: 每個進程都與一個值(優先順序)相關聯, 這個值表示把進程如何適當地分配給CPU.
在linux中, 進程的優先順序是動態的. 調度程式跟蹤進程正在做什麼, 並周期性的調整他們的優先順序. 在這種方式下, 在較長的時間間隔內沒有任何使用CPU的進程, 通過動態地增加他們的優先順序來提升他們. 相應地, 對於已經在CPU上運行了較長時間的進程, 通過減少他們的優先順序來處罰他們.
1.3 進程饑餓
進程饑餓,即為Starvation,指當等待時間給進程推進和響應帶來明顯影響稱為進程饑餓。當饑餓到一定程度的進程在等待到即使完成也無實際意義的時候稱為饑餓死亡。
產生饑餓的主要原因是
在一個動態系統中,對於每類系統資源,操作系統需要確定一個分配策略,當多個進程同時申請某類資源時,由分配策略確定資源分配給進程的次序。
有時資源分配策略可能是不公平的,即不能保證等待時間上界的存在。在這種情況下,即使系統沒有發生死鎖,某些進程也可能會長時間等待.當等待時間給進程推進和響應帶來明顯影響時,稱發生了進程饑餓,當饑餓到一定程度的進程所賦予的任務即使完成也不再具有實際意義時稱該進程被餓死。
舉個例子,當有多個進程需要列印文件時,如果系統分配印表機的策略是最短文件優先,那麼長文件的列印任務將由於短文件的源源不斷到來而被無限期推遲,導致最終的饑餓甚至餓死。
2 linux進程的分類
2.1 進程的分類
當涉及有關調度的問題時, 傳統上把進程分類為”I/O受限(I/O-dound)”或”CPU受限(CPU-bound)”.
| 類型 | 別稱 | 描述 | 示例 |
|---|---|---|---|
| I/O受限型 | I/O密集型 | 頻繁的使用I/O設備, 並花費很多時間等待I/O操作的完成 | 資料庫伺服器, 文本編輯器 |
| CPU受限型 | 計算密集型 | 花費大量CPU時間進行數值計算 | 圖形繪製程式 |
另外一種分類法把進程區分為三類:
| 類型 | 描述 | 示例 |
|---|---|---|
| 互動式進程(interactive process) | 此類進程經常與用戶進行交互, 因此需要花費很多時間等待鍵盤和滑鼠操作. 當接受了用戶的輸入後, 進程必須很快被喚醒, 否則用戶會感覺系統反應遲鈍 | shell, 文本編輯程式和圖形應用程式 |
| 批處理進程(batch process) | 此類進程不必與用戶交互, 因此經常在後臺運行. 因為這樣的進程不必很快相應, 因此常受到調度程式的怠慢 | 程式語言的編譯程式, 資料庫搜索引擎以及科學計算 |
| 實時進程(real-time process) | 這些進程由很強的調度需要, 這樣的進程絕不會被低優先順序的進程阻塞. 並且他們的響應時間要儘可能的短 | 視頻音頻應用程式, 機器人控製程序以及從物理感測器上收集數據的程式 |
註意
前面的兩類分類方法在一定程式上相互獨立
例如, 一個批處理進程很有可能是I/O受限的(如資料庫伺服器), 也可能是CPU受限的(比如圖形繪製程式)
2.2 實時進程與普通進程
在linux中, 調度演算法可以明確的確認所有實時進程的身份, 但是沒辦法區分互動式程式和批處理程式(統稱為普通進程), linux2.6的調度程式實現了基於進程過去行為的啟髮式演算法, 以確定進程應該被當做互動式進程還是批處理進程. 當然與批處理進程相比, 調度程式有偏愛互動式進程的傾向
根據進程的不同分類Linux採用不同的調度策略.
- 對於實時進程,採用FIFO或者Round Robin的調度策略.
- 對於普通進程,則需要區分互動式和批處理式的不同。傳統Linux調度器提高互動式應用的優先順序,使得它們能更快地被調度。而CFS和RSDL等新的調度器的核心思想是”完全公平”。這個設計理念不僅大大簡化了調度器的代碼複雜度,還對各種調度需求的提供了更完美的支持.
註意Linux通過將進程和線程調度視為一個,同時包含二者。進程可以看做是單個線程,但是進程可以包含共用一定資源(代碼和/或數據)的多個線程。因此進程調度也包含了線程調度的功能.
linux進程的調度演算法其實經過了很多次的演變, 但是其演變主要是針對與普通進程的, 因為前面我們提到過根據進程的不同分類Linux採用不同的調度策略.實時進程和普通進程採用了不同的調度策略, 更一般的普通進程還需要啟髮式的識別批處理進程和互動式進程.
實時進程的調度策略比較簡單, 因為實時進程值只要求儘可能快的被響應, 基於優先順序, 每個進程根據它重要程度的不同被賦予不同的優先順序,調度器在每次調度時, 總選擇優先順序最高的進程開始執行. 低優先順序不可能搶占高優先順序, 因此FIFO或者Round Robin的調度策略即可滿足實時進程調度的需求.
但是普通進程的調度策略就比較麻煩了, 因為普通進程不能簡單的只看優先順序, 必須公平的占有CPU, 否則很容易出現進程饑餓, 這種情況下用戶會感覺操作系統很卡, 響應總是很慢.
此外如何進程中如果存在實時進程, 則實時進程總是在普通進程之前被調度
3 linux調度器的演變
一開始的調度器是複雜度為O(n)的始調度演算法(實際上每次會遍歷所有任務,所以複雜度為O(n)), 這個演算法的缺點是當內核中有很多任務時,調度器本身就會耗費不少時間,所以,從linux2.5開始引入赫赫有名的O(1)調度器
然而,linux是集全球很多程式員的聰明才智而發展起來的超級內核,沒有最好,只有更好,在O(1)調度器風光了沒幾天就又被另一個更優秀的調度器取代了,它就是CFS調度器Completely Fair Scheduler. 這個也是在2.6內核中引入的,具體為2.6.23,即從此版本開始,內核使用CFS作為它的預設調度器,
O(1)調度器被拋棄了, 其實CFS的發展也是經歷了很多階段,最早期的樓梯演算法(SD), 後來逐步對SD演算法進行改進出RSDL(Rotating Staircase Deadline Scheduler), 這個演算法已經是”完全公平”的雛形了, 直至CFS是最終被內核採納的調度器, 它從RSDL/SD中吸取了完全公平的思想,不再跟蹤進程的睡眠時間,也不再企圖區分互動式進程。它將所有的進程都統一對待,這就是公平的含義。CFS的演算法和實現都相當簡單,眾多的測試表明其性能也非常優越.
更多CFS的信息, 請參照
http://www.ibm.com/developerworks/cn/linux/l-completely-fair-scheduler/index.html?ca=drs-cn-0125
另外內核文檔sched-design-CFS.txt中也有介紹
| 欄位 | 版本 |
|---|---|
| O(n)的始調度演算法 | linux-0.11~2.4 |
| O(1)調度器 | linux-2.5 |
| CFS調度器 | linux-2.6~至今 |
4 Linux的調度器設計
4 Linux的調度器設計
2個調度器
可以用兩種方法來激活調度
- 一種是直接的, 比如進程打算睡眠或出於其他原因放棄CPU
- 另一種是通過周期性的機制, 以固定的頻率運行, 不時的檢測是否有必要
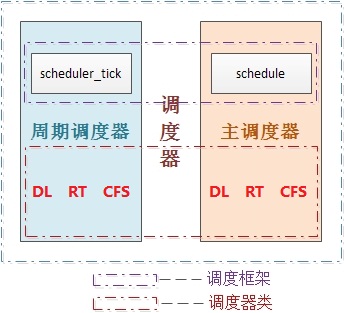
因此當前linux的調度程式由兩個調度器組成:主調度器,周期性調度器(兩者又統稱為通用調度器(generic scheduler)或核心調度器(core scheduler))
並且每個調度器包括兩個內容:調度框架(其實質就是兩個函數框架)及調度器類
6種調度策略
linux內核目前實現了6種調度策略(即調度演算法), 用於對不同類型的進程進行調度, 或者支持某些特殊的功能
比如:
- SCHED_NORMAL和SCHED_BATCH調度普通的非實時進程
- SCHED_FIFO和SCHED_RR和SCHED_DEADLINE則採用不同的調度策略調度實時進程
- SCHED_IDLE則在系統空閑時調用idle進程.
idle的運行時機
idle 進程優先順序為MAX_PRIO,即最低優先順序。
早先版本中,idle是參與調度的,所以將其優先順序設為最低,當沒有其他進程可以運行時,才會調度執行 idle
而目前的版本中idle並不在運行隊列中參與調度,而是在cpu全局運行隊列rq中含idle指針,指向idle進程, 在調度器發現運行隊列為空的時候運行, 調入運行
| 欄位 | 描述 | 所在調度器類 |
|---|---|---|
| SCHED_NORMAL | (也叫SCHED_OTHER)用於普通進程,通過CFS調度器實現。SCHED_BATCH用於非交互的處理器消耗型進程。SCHED_IDLE是在系統負載很低時使用 | CFS |
| SCHED_BATCH | SCHED_NORMAL普通進程策略的分化版本。採用分時策略,根據動態優先順序(可用nice()API設置),分配CPU運算資源。註意:這類進程比上述兩類實時進程優先順序低,換言之,在有實時進程存在時,實時進程優先調度。但針對吞吐量優化, 除了不能搶占外與常規任務一樣,允許任務運行更長時間,更好地使用高速緩存,適合於成批處理的工作 | CFS |
| SCHED_IDLE | 優先順序最低,在系統空閑時才跑這類進程(如利用閑散電腦資源跑地外文明搜索,蛋白質結構分析等任務,是此調度策略的適用者) | CFS-IDLE |
| SCHED_FIFO | 先入先出調度演算法(實時調度策略),相同優先順序的任務先到先服務,高優先順序的任務可以搶占低優先順序的任務 | RT |
| SCHED_RR | 輪流調度演算法(實時調度策略),後者提供 Roound-Robin 語義,採用時間片,相同優先順序的任務當用完時間片會被放到隊列尾部,以保證公平性,同樣,高優先順序的任務可以搶占低優先順序的任務。不同要求的實時任務可以根據需要用sched_setscheduler() API設置策略 | RT |
| SCHED_DEADLINE | 新支持的實時進程調度策略,針對突髮型計算,且對延遲和完成時間高度敏感的任務適用。基於Earliest Deadline First (EDF) 調度演算法 | DL |
linux內核實現的6種調度策略, 前面三種策略使用的是cfs調度器類,後面兩種使用rt調度器類, 最後一個使用DL調度器類
5個調度器類
而依據其調度策略的不同實現了5個調度器類, 一個調度器類可以用一種種或者多種調度策略調度某一類進程, 也可以用於特殊情況或者調度特殊功能的進程.
| 調度器類 | 描述 | 對應調度策略 |
|---|---|---|
| stop_sched_class | 優先順序最高的線程,會中斷所有其他線程,且不會被其他任務打斷作用 1.發生在cpu_stop_cpu_callback 進行cpu之間任務migration 2.HOTPLUG_CPU的情況下關閉任務 |
無, 不需要調度普通進程 |
| dl_sched_class | 採用EDF最早截至時間優先演算法調度實時進程 | SCHED_DEADLINE |
| rt_sched_class | 採用提供 Roound-Robin演算法或者FIFO演算法調度實時進程 具體調度策略由進程的task_struct->policy指定 |
SCHED_FIFO, SCHED_RR |
| fair_sched_class | 採用CFS演算法調度普通的非實時進程 | SCHED_NORMAL, SCHED_BATCH |
| idle_sched_class | 採用CFS演算法調度idle進程, 每個cup的第一個pid=0線程:swapper,是一個靜態線程。調度類屬於:idel_sched_class,所以在ps裡面是看不到的。一般運行在開機過程和cpu異常的時候做dump | SCHED_IDLE |
其所屬進程的優先順序順序為
stop_sched_class -> dl_sched_class -> rt_sched_class -> fair_sched_class -> idle_sched_class3個調度實體
調度器不限於調度進程, 還可以調度更大的實體, 比如實現組調度: 可用的CPUI時間首先在一半的進程組(比如, 所有進程按照所有者分組)之間分配, 接下來分配的時間再在組內進行二次分配.
這種一般性要求調度器不直接操作進程, 而是處理可調度實體, 因此需要一個通用的數據結構描述這個調度實體,即seched_entity結構, 其實際上就代表了一個調度對象,可以為一個進程,也可以為一個進程組.
linux中針對當前可調度的實時和非實時進程, 定義了類型為seched_entity的3個調度實體
| 調度實體 | 名稱 | 描述 | 對應調度器類 |
|---|---|---|---|
| sched_dl_entity | DEADLINE調度實體 | 採用EDF演算法調度的實時調度實體 | dl_sched_class |
| sched_rt_entity | RT調度實體 | 採用Roound-Robin或者FIFO演算法調度的實時調度實體 | rt_sched_class |
| sched_entity | CFS調度實體 | 採用CFS演算法調度的普通非實時進程的調度實體 | fair_sched_class |
調度器類的就緒隊列
另外,對於調度框架及調度器類,它們都有自己管理的運行隊列,調度框架只識別rq(其實它也不能算是運行隊列),而對於cfs調度器類它的運行隊列則是cfs_rq(內部使用紅黑樹組織調度實體),實時rt的運行隊列則為rt_rq(內部使用優先順序bitmap+雙向鏈表組織調度實體), 此外內核對新增的dl實時調度策略也提供了運行隊列dl_rq
調度器整體框架
本質上, 通用調度器(核心調度器)是一個分配器,與其他兩個組件交互.
- 調度器用於判斷接下來運行哪個進程.
內核支持不同的調度策略(完全公平調度, 實時調度, 在無事可做的時候調度空閑進程,即0號進程也叫swapper進程,idle進程), 調度類使得能夠以模塊化的方法實現這些側露額, 即一個類的代碼不需要與其他類的代碼交互
當調度器被調用時, 他會查詢調度器類, 得知接下來運行哪個進程
- 在選中將要運行的進程之後, 必須執行底層的任務切換.
這需要與CPU的緊密交互. 每個進程剛好屬於某一調度類, 各個調度類負責管理所屬的進程. 通用調度器自身不涉及進程管理, 其工作都委托給調度器類.
每個進程都屬於某個調度器類(由欄位task_struct->sched_class標識), 由調度器類採用進程對應的調度策略調度(由task_struct->policy )進行調度, task_struct也存儲了其對應的調度實體標識
linux實現了6種調度策略, 依據其調度策略的不同實現了5個調度器類, 一個調度器類可以用一種或者多種調度策略調度某一類進程, 也可以用於特殊情況或者調度特殊功能的進程.
| 調度器類 | 調度策略 | 調度策略對應的調度演算法 | 調度實體 | 調度實體對應的調度對象 |
|---|---|---|---|---|
| stop_sched_class | 無 | 無 | 無 | 特殊情況, 發生在cpu_stop_cpu_callback 進行cpu之間任務遷移migration或者HOTPLUG_CPU的情況下關閉任務 |
| dl_sched_class | SCHED_DEADLINE | Earliest-Deadline-First最早截至時間有限演算法 | sched_dl_entity | 採用DEF最早截至時間有限演算法調度實時進程 |
| rt_sched_class | SCHED_RR SCHED_FIFO |
Roound-Robin時間片輪轉演算法 FIFO先進先出演算法 |
sched_rt_entity | 採用Roound-Robin或者FIFO演算法調度的實時調度實體 |
| fair_sched_class | SCHED_NORMAL SCHED_BATCH |
CFS完全公平懂調度演算法 | sched_entity | 採用CFS演算法普通非實時進程 |
| idle_sched_class | SCHED_IDLE | 無 | 無 | 特殊進程, 用於cpu空閑時調度空閑進程idle |
它們的關係如下圖
5種調度器類為什麼只有3種調度實體
正常來說一個調度器類應該對應一類調度實體, 但是5種調度器類卻只有了3種調度實體?
這是因為調度實體本質是一個可以被調度的對象, 要麼是一個進程(linux中線程本質上也是進程), 要麼是一個進程組, 只有dl_sched_class, rt_sched_class調度的實時進程(組)以及fair_sched_class調度的非實時進程(組)是可以被調度的實體對象, 而stop_sched_class和idle_sched_class
4.2 進程的調度
首先,我們需要清楚,什麼樣的進程會進入調度器進行選擇,就是處於TASK_RUNNING狀態的進程,而其他狀態下的進程都不會進入調度器進行調度。
系統發生調度的時機如下
- 調用cond_resched()時
- 顯式調用schedule()時
- 從系統調用或者異常中斷返回用戶空間時
- 從中斷上下文返回用戶空間時
當開啟內核搶占(預設開啟)時,會多出幾個調度時機,如下
- 在系統調用或者異常中斷上下文中調用preempt_enable()時(多次調用preempt_enable()時,系統只會在最後一次調用時會調度)
- 在中斷上下文中,從中斷處理函數返回到可搶占的上下文時(這裡是中斷下半部,中斷上半部實際上會關中斷,而新的中斷只會被登記,由於上半部處理很快,上半部處理完成後才會執行新的中斷信號,這樣就形成了中斷可重入)
而在系統啟動調度器初始化時會初始化一個調度定時器,調度定時器每隔一定時間執行一個中斷,在中斷會對當前運行進程運行時間進行更新,如果進程需要被調度,在調度定時器中斷中會設置一個調度標誌位,之後從定時器中斷返回,因為上面已經提到從中斷上下文返回時是有調度時機的,在內核源碼的彙編代碼中所有中斷返回處理都必須去判斷調度標誌位是否設置,如設置則執行schedule()進行調度。
而我們知道實時進程和普通進程是共存的,調度器是怎麼協調它們之間的調度的呢,其實很簡單,每次調度時,會先在實時進程運行隊列中查看是否有可運行的實時進程,如果沒有,再去普通進程運行隊列找下一個可運行的普通進程,如果也沒有,則調度器會使用idle進程進行運行。
之後的章節會放上代碼進行詳細說明。
系統並不是每時每刻都允許調度的發生,當處於硬中斷期間的時候,調度是被系統禁止的,之後硬中斷過後才重新允許調度。而對於異常,系統並不會禁止調度,也就是在異常上下文中,系統是有可能發生調度的。
4.3 搶占標識TIF_NEED_RESCHED
內核在檢查need_resched標識TIF_NEED_RESCHED的值判斷是否需要搶占當前進程, 內核在thread_info的flag中設置了一個標識來標誌進程是否需要重新調度, 即重新調度need_resched標識TIF_NEED_RESCHED, 內核在即將返回用戶空間時會檢查標識TIF_NEED_RESCHED標誌進程是否需要重新調度
系統中每個進程都有一個特定於體繫結構的struct thread_info結構, 用戶層程式被調度的時候會檢查struct thread_info中的need_resched標識TLF_NEED_RESCHED標識來檢查自己是否需要被重新調度.
如果內核檢查進程的搶占標識被設置, 則會在一個關鍵的時刻, 調用調度器來完成調度和搶占的工作
4.4 內核搶占和用戶搶占
而根據進程搶占發生的時機, 搶占可以分為內核搶占和用戶搶占, 內核搶占就是指一個在內核態運行的進程, 可能在執行內核函數期間被另一個進程取
一般來說,用戶搶占發生幾下情況:
- 從系統調用返回用戶空間;
- 從中斷(異常)處理程式返回用戶空間
內核搶占發生的時機,一般發生在:
- 當從中斷處理程式正在執行,且返回內核空間之前。當一個中斷處理常式退出,在返回到內核態時(kernel-space)。這是隱式的調用schedule()函數,當前任務沒有主動放棄CPU使用權,而是被剝奪了CPU使用權。
- 當內核代碼再一次具有可搶占性的時候,如解鎖(spin_unlock_bh)及使能軟中斷(local_bh_enable)等, 此時當kernel code從不可搶占狀態變為可搶占狀態時(preemptible again)。也就是preempt_count從正整數變為0時。這也是隱式的調用schedule()函數
- 如果內核中的任務顯式的調用schedule(), 任務主動放棄CPU使用權
- 如果內核中的任務阻塞(這同樣也會導致調用schedule()), 導致需要調用schedule()函數。任務主動放棄CPU使用權
內核搶占採用同搶占標識的類似方法被實現, linux內核在thread_info結構中添加了一個自旋鎖標識preempt_count, 稱為搶占計數器(preemption counter).
struct thread_info
{
/* ...... */
int preempt_count; /* 0 => preemptable, <0 => BUG */
/* ...... */
}| preempt_count | 描述 |
|---|---|
| >0 | 禁止內核搶占, 其值標記了使用preempt_count的臨界區的數目 |
| =0 | 開啟內核搶占 |
| <0 | 鎖為負值, 內核出現錯誤 |
內核自然也提供了一些函數或者巨集, 用來開啟, 關閉以及檢測搶占計數器preempt_coun的值, 這些通用的函數定義在include/asm-generic/preempt.h, 而某些架構也定義了自己的介面, 比如x86架構/arch/x86/include/asm/preempt.h
4.5 周期性調度器scheduler_tick
周期調度器
周期性調度器scheduler_tick由內核時鐘中斷周期性的觸發, 周期性調度器以固定的頻率激活負責當前進程調度類的周期性調度方法, 以保證系統的併發性, 周期性調度器通過調用進程所屬調度器類的task_tick操作完成周期性調度的通知和配置工作, 通過resched_curr函數(早期的resched_task函數)設置搶占標識TIF_NEED_RESCHED來通知內核在必要的時間由主調度函數完成真正的調度工作, 此種做法稱之為延遲調度策略
4.6 主調度器schedule
主調度器
schedule就是主調度器的工作函數, 在內核中的許多地方, 如果要將CPU分配給與當前活動進程不同的另一個進程, 都會直接調用主調度器函數schedule或者其子函數__schedule.
__schedule完成搶占
- 完成一些必要的檢查, 並設置進程狀態, 處理進程所在的就緒隊列
- 調度全局的pick_next_task選擇搶占的進程
如果當前cpu上所有的進程都是cfs調度的普通非實時進程, 則直接用cfs調度, 如果無程式可調度則調度idle進程
否則從優先順序最高的調度器類sched_class_highest(目前是stop_sched_class)開始依次遍歷所有調度器類的pick_next_task函數, 選擇最優的那個進程執行
- context_switch完成進程上下文切換
調用switch_mm(), 把虛擬記憶體從一個進程映射切換到新進程中
調用switch_to(),從上一個進程的處理器狀態切換到新進程的處理器狀態。這包括保存、恢復棧信息和寄存器信息
4.7 進程上下文切換context_switch
context_switch流程
context_switch其實是一個分配器, 他會調用所需的特定體繫結構的方法
- 調用switch_mm(), 把虛擬記憶體從一個進程映射切換到新進程中
switch_mm更換通過task_struct->mm描述的記憶體管理上下文, 該工作的細節取決於處理器, 主要包括載入頁表, 刷出地址轉換後備緩衝器(部分或者全部), 向記憶體管理單元(MMU)提供新的信息
- 調用switch_to(),從上一個進程的處理器狀態切換到新進程的處理器狀態。這包括保存、恢復棧信息和寄存器信息
switch_to切換處理器寄存器的呢內容和內核棧(虛擬地址空間的用戶部分已經通過switch_mm變更, 其中也包括了用戶狀態下的棧, 因此switch_to不需要變更用戶棧, 只需變更內核棧), 此段代碼嚴重依賴於體繫結構, 且代碼通常都是用彙編語言編寫.
為什麼switch_to需要3個參數
在新進程被選中執行時, 內核恢復到進程被切換出去的點繼續執行, 此時內核只知道誰之前將新進程搶占了, 但是卻不知道新進程再次執行是搶占了誰, 因此底層的進程切換機制必須將此前執行的進程(即新進程搶占的那個進程)提供給context_switch. 由於控制流會回到函數的該中間, 因此無法通過普通函數的返回值來完成. 因此使用了一個3個參數, 但是邏輯效果是相同的, 仿佛是switch_to是帶有兩個參數的函數, 而且返回了一個指向此前運行的進程的指針.
switch_to(prev, next, last);
即
prev = last = switch_to(prev, next);其中返回的prev值並不是做參數的prev值, 而是prev被再次調度的時候搶占掉的那個進程last.
4.8 處理進程優先順序
內核使用一些簡單的數值範圍0~139表示內部優先順序, 數值越低, 優先順序越高。
從0~99的範圍專供實時進程使用, nice的值[-20,19]則映射到範圍100~139
其中task_struct採用了三個成員表示進程的優先順序:prio和normal_prio表示動態優先順序, static_prio表示進程的靜態優先順序.
此外還用了一個欄位rt_priority保存了實時進程的優先順序
| 欄位 | 描述 |
|---|---|
| static_prio | 用於保存靜態優先順序, 是進程啟動時分配的優先順序, ,可以通過nice和sched_setscheduler系統調用來進行修改, 否則在進程運行期間會一直保持恆定 |
| prio | 保存進程的動態優先順序 |
| normal_prio | 表示基於進程的靜態優先順序static_prio和調度策略計算出的優先順序. 因此即使普通進程和實時進程具有相同的靜態優先順序, 其普通優先順序也是不同的, 進程分叉(fork)時, 子進程會繼承父進程的普通優先順序 |
| rt_priority | 用於保存實時優先順序, 實時進程的優先順序用實時優先順序rt_priority來表示 |
靜態優先順序static_prio(普通進程)和實時優先順序rt_priority(實時進程)是計算的起點
因此他們也是進程創建的時候設定好的, 我們通過nice修改的就是普通進程的靜態優先順序static_prio
首先通過靜態優先順序static_prio計算出普通優先順序normal_prio, 該工作可以由nromal_prio來完成, 該函數定義在kernel/sched/core.c#L861
內核通過effective_prio設置動態優先順序prio, 計算動態優先順序的流程如下
- 設置進程的普通優先順序(實時進程99-rt_priority, 普通進程為static_priority)
- 計算進程的動態優先順序(實時進程則維持動態優先順序的prio不變, 普通進程的動態優先順序即為其普通優先順序)
最後, 我們綜述一下在針對不同類型進程的計算結果
| 進程類型 | 實時優先順序rt_priority | 靜態優先順序static_prio | 普通優先順序normal_prio | 動態優先順序prio |
|---|---|---|---|---|
| EDF調度的實時進程 | rt_priority | 不使用 | MAX_DL_PRIO-1 | 維持原prio不變 |
| RT演算法調度的實時進程 | rt_priority | 不使用 | MAX_RT_PRIO-1-rt_priority | 維持原prio不變 |
| 普通進程 | 不使用 | static_prio | static_prio | static_prio |
| 優先順序提高的普通進程 | 不使用 | static_prio(改變) | static_prio | 維持原prio不變 |
4.9 喚醒搶占
當在try_to_wake_up/wake_up_process和wake_up_new_task中喚醒進程時, 內核使用全局check_preempt_curr看看是否進程可以搶占當前進程可以搶占當前運行的進程.
每個調度器類都因應該實現一個check_preempt_curr函數, 在全局check_preempt_curr中會調用進程其所屬調度器類check_preempt_curr進行搶占檢查, 對於完全公平調度器CFS處理的進程, 則對應由check_preempt_wakeup函數執行該策略.
新喚醒的進程不必一定由完全公平調度器處理, 如果新進程是一個實時進程, 則會立即請求調度, 因為實時進程優先極高, 實時進程總會搶占CFS進程
內核為了實現完全公平, 對一些互動式進程有補償機制, 這些互動式進程多數情況下屬於睡眠狀態, 只有在接收到信號以後被喚醒, 比如vim在接收了鍵盤錄入的信號後被喚醒, 完成工作後又進入睡眠態, 因此我們需要對喚醒的進程做一些補償, 關於補償的內容我們會在各個調度器類的設計中講解.


