
死鎖概述 對於資料庫中出現的死鎖,通俗地解釋就是:不同Session(會話)持有一部分資源,並且同時相互排他性地申請對方持有的資源,然後雙方都得不到自己想要的資源,從而造成的一種僵持的現象。當然,在任何一種資料庫中,這種僵持的情況不會一直持續下去,因為一直持續下去雙方永遠都無法執行,沒有任何意義,在 ...
死鎖概述
對於資料庫中出現的死鎖,通俗地解釋就是:不同Session(會話)持有一部分資源,並且同時相互排他性地申請對方持有的資源,然後雙方都得不到自己想要的資源,從而造成的一種僵持的現象。
當然,在任何一種資料庫中,這種僵持的情況不會一直持續下去,因為一直持續下去雙方永遠都無法執行,沒有任何意義,
在SQL Server中,後臺線程會以3秒鐘一次的頻率檢測死鎖Session,並且選擇其中一個回滾代價相對較低的作為犧牲品,從而使解除不同Session相互僵持的現象。
因此SQL Server中死鎖的僵持時間不會超過3秒鐘。
通常情況下,最簡單也是最常見的死鎖是發生在不同表級別的,
Session 1 第一步修改A表,第二步修改B表,
Session 2第一步修改B表,第二步修改A表,
當發生Session 1與Session 2推進順序發生交叉的時候,死鎖就發生了,這種結局辦法也比較簡單,以相同的推進順序進行操作即可解除死鎖。
以下演示一種不用於以上情況,稍微特殊一點的死鎖。
同一張表上發生的死鎖演示
不過死鎖的種類有很多種,上述的僅是一種最簡單最常見的一種死鎖,
理論上,只要滿足死鎖發生的條件:不同Session(會話)排他性地持有一部分資源,並且相互申請對方持有的資源
都會產生死鎖,並不僅僅是在不同的表上,而是在不同的資源上,這種資源,可以是同一張表,甚至同一行數據上,以下舉例說明。
--TestDeadLock的Id是主鍵(預設生成聚集索引),Col2欄位是唯一性的非聚集索引
create table TestDeadLock
(
Id int constraint pk_TestDeadLock_id primary key,
Col2 int constraint uk_TestDeadLock_col2 unique,
Remark varchar(100)
)
然後利用SQLQueryStress,開啟兩個回話,分別按照聚集索引和非聚集索引,刪除同一行數據(造測試數據的時候會設置Id和Col2都為1),
如下圖所示
一開始先讓這兩個Session一直執行(空運行),隨後往TestDeadLock表中插入一行數據(insert into [TestDeadLock] values (1,1,newid()))
可能需要執行幾次,就會觀察到其中一個SQLQueryStress中發生了異常信息
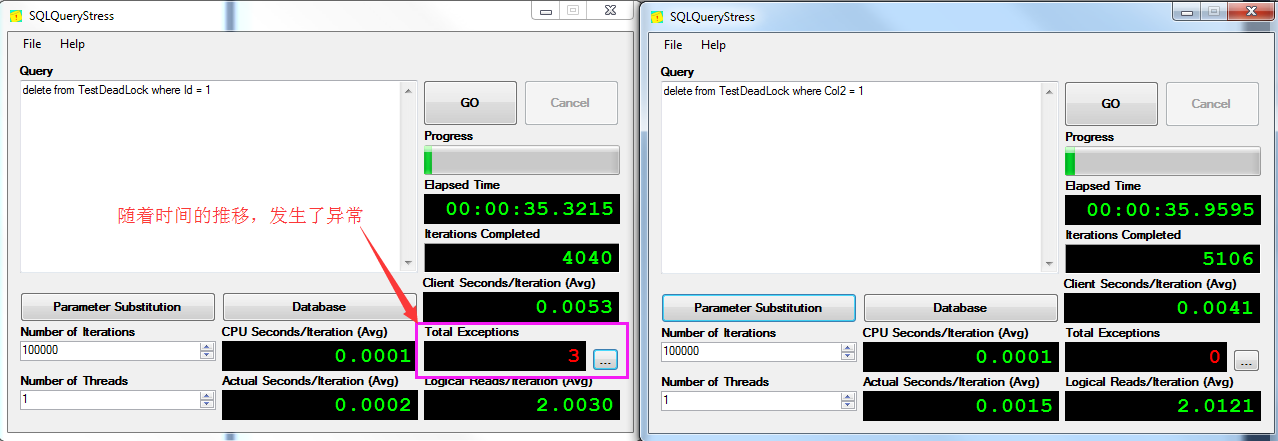
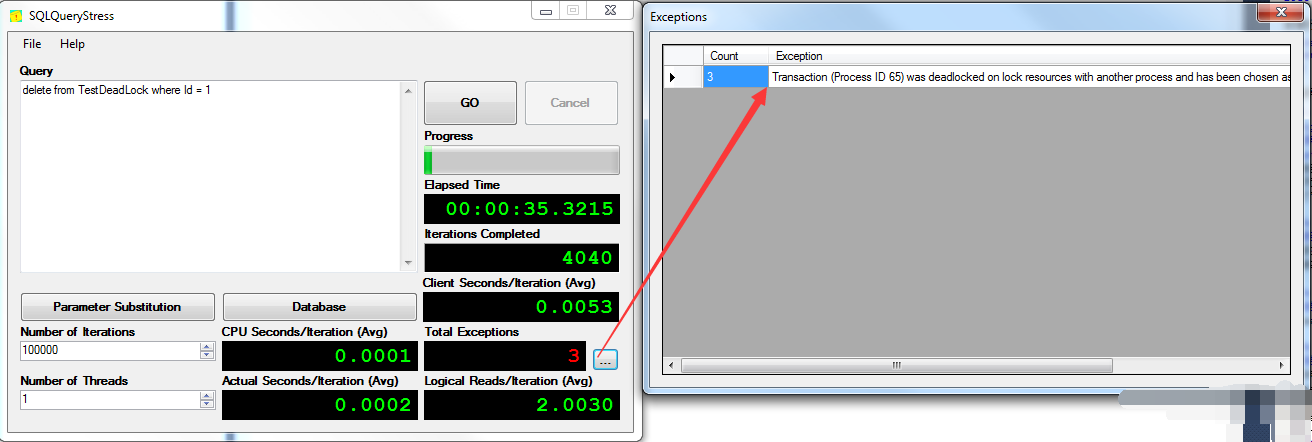
打開其異常信息的詳細內容 ,會發現是死鎖
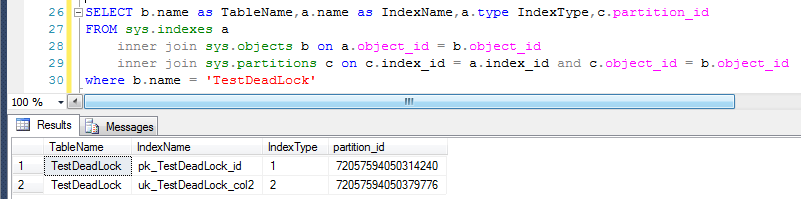
首先查一下表上索引的id,一下分析加鎖的過程中會用到。
pk_TestDeadLock_id 是聚集索引,其Id是 72057594050314240
uk_TestDeadLock_col2 是非聚集索引,其Id是 72057594050379776
利用sqlserver自帶的system_health擴展事件,觀察其死鎖信息(xml_deadlock_report)
SELECT CAST(xet.target_data AS XML)
FROM sys.dm_xe_session_targets xet
JOIN sys.dm_xe_sessions xe ON ( xe.address = xet.event_session_address )
WHERE xe.name = 'system_health'
select xml_event_data,
xml_event_data.value('(event[@name="xml_deadlock_report"]/@timestamp)[1]','datetime') Execution_Time,
xml_event_data.value('(event/data/value)[1]','varchar(max)') Query
from
(
SELECT event_table.xml_event_data
FROM(
SELECT CAST(event_data AS XML) xml_event_data
FROM sys.fn_xe_file_target_read_file(N'your path \system_health_*', NULL, NULL, NULL)
) AS event_table
CROSS APPLY xml_event_data.nodes('//event') n (event_xml)
WHERE event_xml.value('(./@name)', 'varchar(1000)') IN ('xml_deadlock_report')
) v
order by Execution_Time
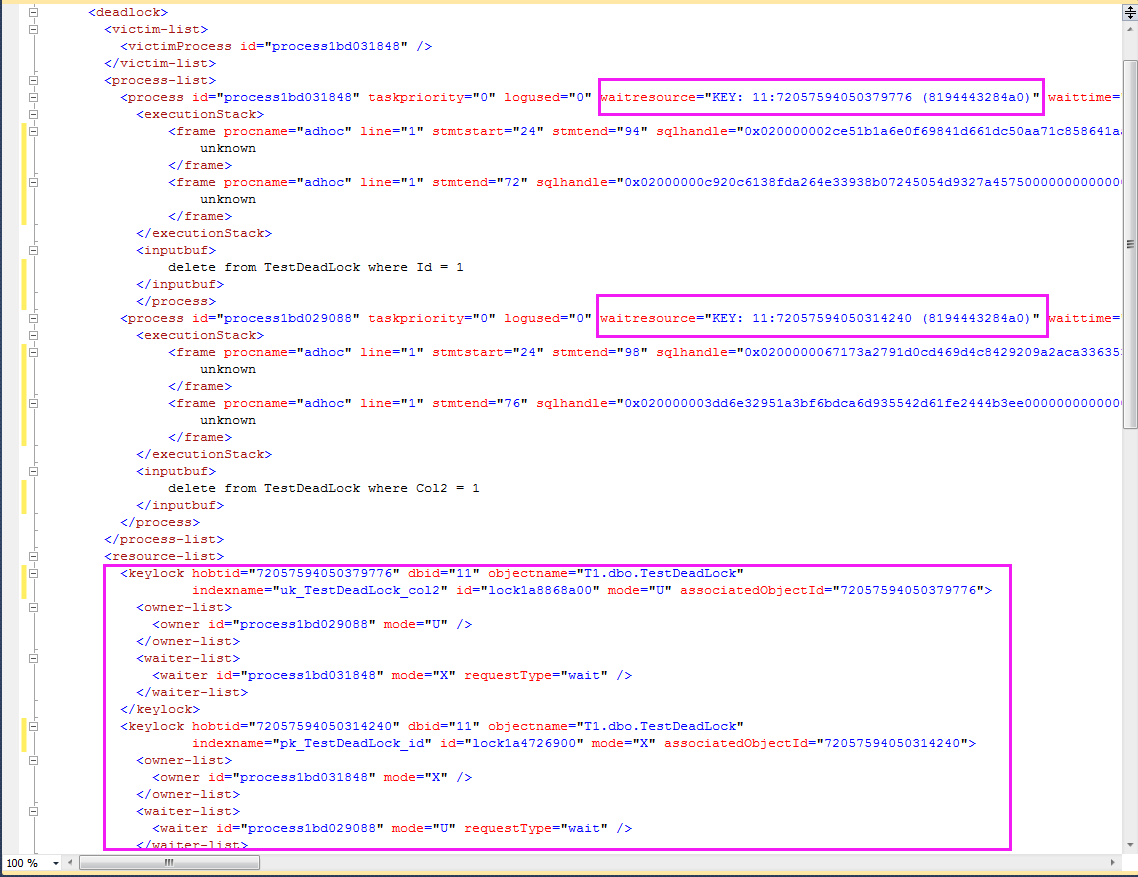
得到如下的死鎖信息,擴展事件中的xml_deadlock_report清楚吧地表明:對於當前這一行數據(8194443284a0一樣)
delete from [TestDeadLock] where Id= 1 等待非聚集索引上的鎖(waitresource="KEY: 11:72057594050379776 (8194443284a0)" )
delete from [TestDeadLock] where Col2 = 1 等待聚集索引上的鎖(waitresource="KEY: 11:72057594050314240 (8194443284a0)" )
兩者有死鎖,肯定是相互等待對方已經持有的資源(索引上的鎖)
因此,當前這個死鎖可以這麼理解
delete from [TestDeadLock] where Id=1 持有聚集索引上的U鎖,申請非聚集索引上的X鎖
delete from [TestDeadLock] where Col2 = 1 持有非聚集索引上的X鎖,申請聚集索引上的U鎖
結果:死鎖!
關於waitresource的解讀,參考:https://blog.csdn.net/kk185800961/article/details/41687209
兩個SQL的加鎖順序分析
上述分析只是根據已有現象推測其過程,如果能夠觀察到每一個sql語句執行過程中的鎖的申請與釋放順序,問題就更容易理解了。
以下利用profile觀察兩個語句執行過程中對鎖的申請和釋放順序
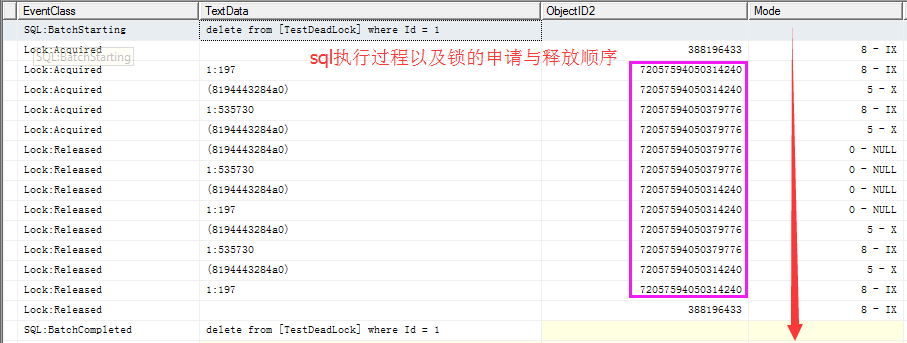
觀察一下delete from [TestDeadLock] where Id = 1 這句sql的執行過程的鎖的申請順序
profile里就很清楚,對於delete from [TestDeadLock] where Id = 1
先申請聚集索引(72057594050314240)page層面上的意向排它鎖(IX),轉為行級別的排它鎖(X),再申請非聚集索引(72057594050379776)的page層面意向排它鎖(IX),轉換為行級別排它鎖(X)
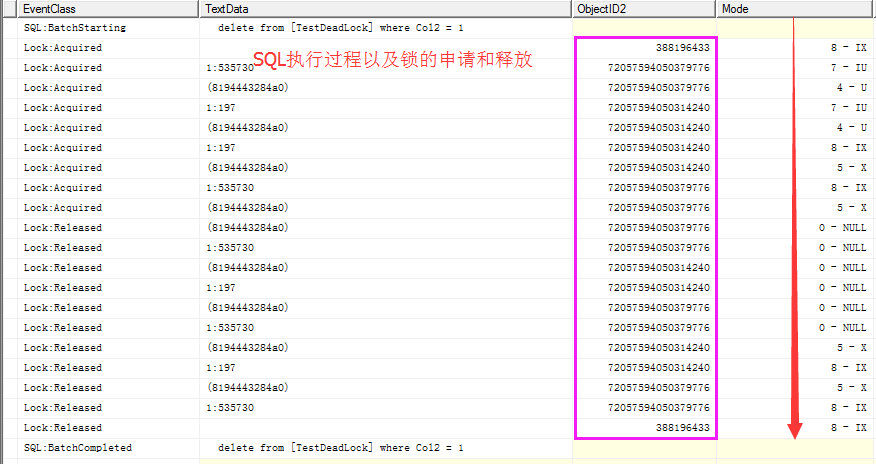
對於delete from [TestDeadLock] where Col2 = 1
先申請非聚集索引(72057594050379776)上page層面的意向更新鎖(IU),轉為行級別更新鎖鎖(U),再申請page層面聚集索引(72057594050314240)的意向排它鎖(IX),轉換為行級別排它鎖(X)
通過以上加鎖順序的分析,印證了上述加鎖方式的推測,不難理解兩個SQL語句為什麼會發生死鎖。
仍然回到死鎖的概念上:不同Session(會話)排他性地持有一部分資源,並且同時申請對方持有的資源
這種相互持有的資源,可以是不同表上的資源,可以是同一個表上的資源,甚至可以是同一行數據的不同資源(不同索引的資源)
只要發生不同Session相互排他性地持有對方想要的資源,死鎖就會發生。
這種方式是雙方根據不同的索引同時delete引起的死鎖,類似上述情況,可以延伸到雙方同時update,雙方同時delete或者update,雙方同時update或者select等等
只要是索引推進順序不一致,都有可能引起死鎖的發生,此類問題可以歸結為同一行數據上,不同索引操作引起的死鎖。
如何解決?
對於常見的不同表上的推進順序不當造成的死鎖,只要改進持鎖的順序即可,也就是按照同一種方式來操作不同表中的數據。
對於上述的問題,不是不同表上的推進順序造成的,而是同一張表的同一行數據的資源推進順序不當導致的,在sql語句層面看起來並沒有什麼不妥當的,因此只能從鎖的範圍或者隔離級別上進行調整。
1,嘗試從業務入手,是否能夠按照統一的方式對數據進行操作。
2,使用隊列消除併發操作的峰值。
3,嘗試tablockx,一次性鎖定整個表。
4,嘗試改變隔離級別,嘗試序列化隔離級別。
最後佛系一下:
很多問題都喜歡用奇怪解釋,其實很多問題並不奇怪,只是不知道而已,
技術上的問題,不知道也沒什麼大不了,知道了更沒什麼大不了,知道也僅僅是知道而已,不知道經歷一次就知道了,知不知道都沒有任何值得自豪或者自卑的
你的知識死角不能否定你的技術能力,應用層面的東西,只不過是在人家制定好的規則上玩游戲而已,誰也不要裝。
參考:
https://www.cnblogs.com/Uest/p/4998527.html
https://blogs.msdn.microsoft.com/apgcdsd/2012/02/27/sql-serverdeadlock/
https://www.simple-talk.com/sql/performance/sql-server-deadlocks-by-example/


