
RDD是spark的核心,先感性的先認識RDD,大體上對RDD進行了分類操作 ...
目錄
返回頂部RDD簡介
RDD是彈性分散式數據集(Resilient Distributed Dataset),能在並行計算階段進行高效的數據共用;RDD還提供了一種粗粒度介面,該介面會將相同的操作應用到多個數據集上並記錄創建數據集的‘血統’,從而在不需要存儲真正的數據的情況下,達到高效的容錯性。
返回頂部RDD操作類別
RDD操作大致可分為四類:創建操作、轉換操作、控制操作、行動操作;在這些大類的基礎上還能劃為些細類,下麵是大部分的RDD操作,以及其細類劃分情況。

返回頂部
RDD分區
分區的多少決定RDD的並行粒度;分區是邏輯概念,分區前後可能存儲在同一記憶體;RDD分區之間存在依賴關係,分為寬依賴和窄依賴
寬依賴:多個子RDD分區依賴一個父RDD分區;如join,groupBy操作;
窄依賴:窄依賴:每個父RDD的分區都至多被被一個子RDD的分區使用;如map操作一對一關係
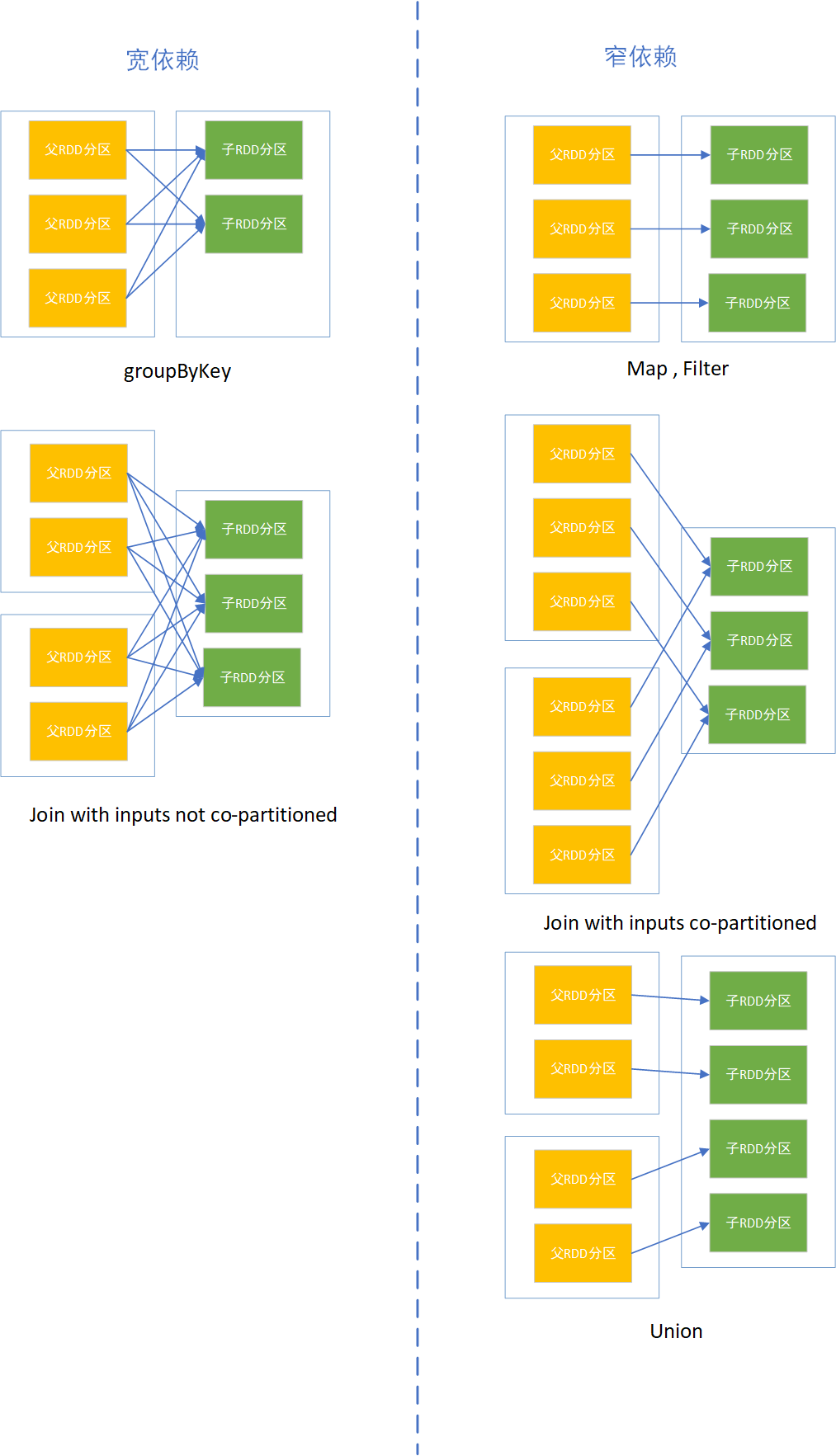
寬依賴和窄依賴作用
窄依賴允許在單個集群節點上流水線式執行,這個節點可以計算所有父級分區;而且,在窄依賴中,節點失敗後的恢復更加高效
寬依賴的繼承關係中,單個失敗節點可能導致一個RDD的所有祖先RDD中的一些分區丟失,導致計算重新執行
返回頂部RDD分區劃分器
spark中RDD計算是以分區為單位的,而計算函數都是在迭代器中複合;分區計算一般使用mapPartitions等計算。
spark提供了兩種預設的分區劃分器,一種是HashPartitioner(哈希分區劃分器),另一種是RangePartitioner(範圍分區劃分器)
返回頂部RDD到調度
RDD轉換操作屬於lazy級別,會延遲執行,作業的提交是由行動操作觸發。當執行RDD行動操作時觸發作業的提交,然後會根據RDD之間的關係構建DAG(有向無環圖),再提交給DAGScheduler進行解析;解析之後會得到調度階段Stage,也就是taskSet;最後TashScheduler進一步解析得到task,task將會在Worker中Executor裡面執行。


