
說到提高檢索效率,就必然提到索引。今天就來為大家講述搜索引擎中最常見的索引方式——倒排索引。 ...
考慮一下未來個人使用的設備,它將是一個機械化的個人圖書館,它需要一個名字引起人們的註意:"MEMEX"就可以.MEMEX是這樣一個機械化設備,人們可以在其中存儲書籍、記錄和信件,同時可以以很高的速度和極強的靈活性完成檢索.作為輔助設備,它是人腦的無限擴大.——Bush,1945
說到提高檢索效率,就必然提到索引。今天就來為大家講述搜索引擎中最常見的索引方式——倒排索引。
沒有索引的時代
走入一個書店,這個書店的書只是亂糟糟的擺在一起,你現在想要找到一本叫做《Spring in action》的書,你要怎麼辦?嗯……是的,你只能一本一本的翻,直到翻到這本書為止。結果你翻到最後一本才發現,這個書店並沒有你想要的書。你已經在這裡花費了一整天的時間(好在這個書店不大),你身心疲憊地罵了句“操蛋”,離開了這個書店。
這種在沒有任何索引的情況下檢索信息(或者說查找)的方式,我們可以稱之為grep。我們一般在類UNIX系統中使用的grep命令就是用類似的方法進行檢索的,win系統中常用的文本檢索(Ctrl+F)也是如此。對於電腦來講,掃描整個文件的速度會遠快於一個人翻閱整個書店,因此在檢索少量信息時(例如,單個文本文件的信息)是足夠的。但是當信息量變得十分龐大時,就會變得十分緩慢。比如在類UNIX系統中的grep命令,去掃描大文件夾的時候,就可能慢得無法忍受。
傳統索引
你實在是需要《Spring in action》這本書,你今天又來到了一個看起來十分古老的圖書館。這個圖書館的藏書不少,但是並沒有什麼圖書管理信息系統,但是他們有一套自己的索引系統——書名書目檢索櫃。大概就是這麼個東西:

你回憶起來你小時候似乎見過這個東西(大概,上個世紀末吧)這個柜子上每一個抽屜都對應著一個分類,比如歷史、法律、電腦等等。你找到了電腦分類的抽屜,然後拉開了抽屜,你看到裡邊有非常非常多的卡片:

這些卡片被一些標著字母的大卡片分組隔開,分為了26組。你知道這意味著每一組都是標題以某一字母或某一拼音開頭的圖書的信息。這些卡片叫做索引卡片。這些卡片都是按照字母或拼音順序進行排序的。有了這個排序,你很快就從S分組中找到了《Spring in action》這本書。然後根據索引卡片上關於圖書存放位置的指示很快的找到了這本書。你心滿意足的回家去了~
這種索引技術其實和電腦上傳統的索引技術是相同的。這就相當於為圖書的分類信息和書名信息做了索引。而且還是聯合索引。我們同樣也發現聯合索引的一個局限性,就是聯合索引是有先後順序的。比如說你先對分類做索引,再對書名做索引。這時你在查找的時候,如果你不先查找分類,而是先查找了書名,這個索引就不起作用了。對我們的另一個啟示就是,索引之所以快的原因,是因為有序(從電腦的角度講,有序就可以使用二分查找,這是十分高效的)。
辭彙文檔矩陣
你看完《Spring in action》之後還想深入學習一些關於依賴註入的內容,然而你不知道什麼書會講這部分內容。你想去圖書館再找找。然後你又一次來到了那個老舊的圖書館,你再一次打開了電腦分類的抽屜,看著數以千計的卡片,陷入了深深的沉思……這根本找不到嘛……這和翻書店有什麼區別?更何況光看標題可能也看不出什麼。
我們發現此時此刻你的需求變了,你不是要找具體的某本書了,你要找的是具有某個主題的書。這個主題可能是一句話,可能是一個詞。而我們發現一句話的最小組成粒度也是詞(或字)。所以我們發現我們最終要做的其實是對詞做索引。那麼我們要怎麼做呢?首先我們可以做一個“辭彙-文檔矩陣”,橫坐標為文檔id,縱坐標為具體辭彙:

我們可以讓縱坐標的辭彙有序排列(比如按照字母/拼音順序排列),這樣我們就可以快速的定位到一個辭彙。然後我們再去找都有哪些文檔對應著這些辭彙。但是“辭彙-文檔矩陣”只是一個概念模型,我們如何在電腦中使用數據結構實現這個概念呢?
最簡單的方法就是,直接這麼存。先存儲一個有序的文檔id數組,然後在存儲一個辭彙數組。之後創建一個二維數組,數組的橫坐標長度和文檔id數組長度相同,縱坐標長度和辭彙數組相同,然後在這個二維數組的元素中存儲1或0。1代表對應位置的文檔包含對應位置的辭彙,0代表不包含。如圖所示:

這種實現方法十分簡單,但是卻具有一個巨大的缺陷。如果我們的辭彙量有50萬個,文檔量有100萬個(在當今這個數量並不大),那麼我們需要的存儲空間大小就至少要50萬*100萬=5000億個位元組,也就是至少465gb的信息量,這個信息量要遠遠大於一臺電腦的記憶體量。這根本是無法忍受的。
倒排索引
那麼我們要如何優化這個結構呢?我們不難發現這個矩陣其實具有高度的稀疏性(大量的值為0)。畢竟不可能每本書都有50萬個不同的詞,如果考慮到大量的論文或者博客的話,可能平均一篇文獻中能有1000個不一樣的詞都很不容易了。這就意味著這個矩陣中99%的元素都為0。這樣我們很容易想到,那我們就只記錄那些1不就可以了。也就是說我們只要根據辭彙去記錄那些包含這個辭彙的文檔就可以了。這樣同樣我們要維護一個辭彙數組,然後辭彙數組中的每個元素(也就是每個辭彙)都會對應一個文檔列表,這個文檔列表中保存的是,具有這個辭彙的文檔的id。這樣就極大的節省了存儲空間。結構如下:
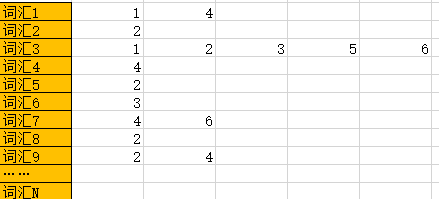
以上就是倒排索引的一些基本概念。其實倒排索引是一個很早就被人發明出的索引模型,在1958年IBM就在一次會議上展示了一臺“自動索引機器”。雖然這種索引方式誕生的很早,但是至今依舊是全文索引的重要的基礎之一。


