是不是很想知道那三步? 其實很簡單! 1、打開網頁,獲取源碼 2、獲取圖片 3、保存圖片地址與下載圖片 打開網頁,獲取源碼 *由於多人同時爬蟲某個網站時候,會造成數據冗餘,網站崩潰,所以一些網站是禁止爬蟲的,會返回403拒絕訪問的錯誤信息。 獲取不到想要的內容/請求失敗/IP容易被封……..等 *解 ...

是不是很想知道那三步?
其實很簡單!
1、打開網頁,獲取源碼
2、獲取圖片
3、保存圖片地址與下載圖片
打開網頁,獲取源碼
*由於多人同時爬蟲某個網站時候,會造成數據冗餘,網站崩潰,所以一些網站是禁止爬蟲的,會返回403拒絕訪問的錯誤信息。----獲取不到想要的內容/請求失敗/IP容易被封……..等
*解決辦法:偽裝——不告訴網站我是一個腳本,告訴它我是一個瀏覽器。(加上隨便一個瀏覽器的頭部信息,偽裝成瀏覽器),由於是簡單例子,那我們就不搞這些騷操作了。
獲取圖片
*Find函數 :只去找第一個目標,查詢一次
*Find_all函數: 找到所有的相同的目標。
這裡可能有一個解析器的問題,我們也不說了,出問題的同學百度一堆解決辦法。
保存圖片地址與下載圖片
a.使用urlib---urlretrieve下載(保存位置:如果保存在跟*.py文件同一個地方,那麼只需要文件夾名稱即可,如果是其他地方,那麼得寫絕對路徑。)
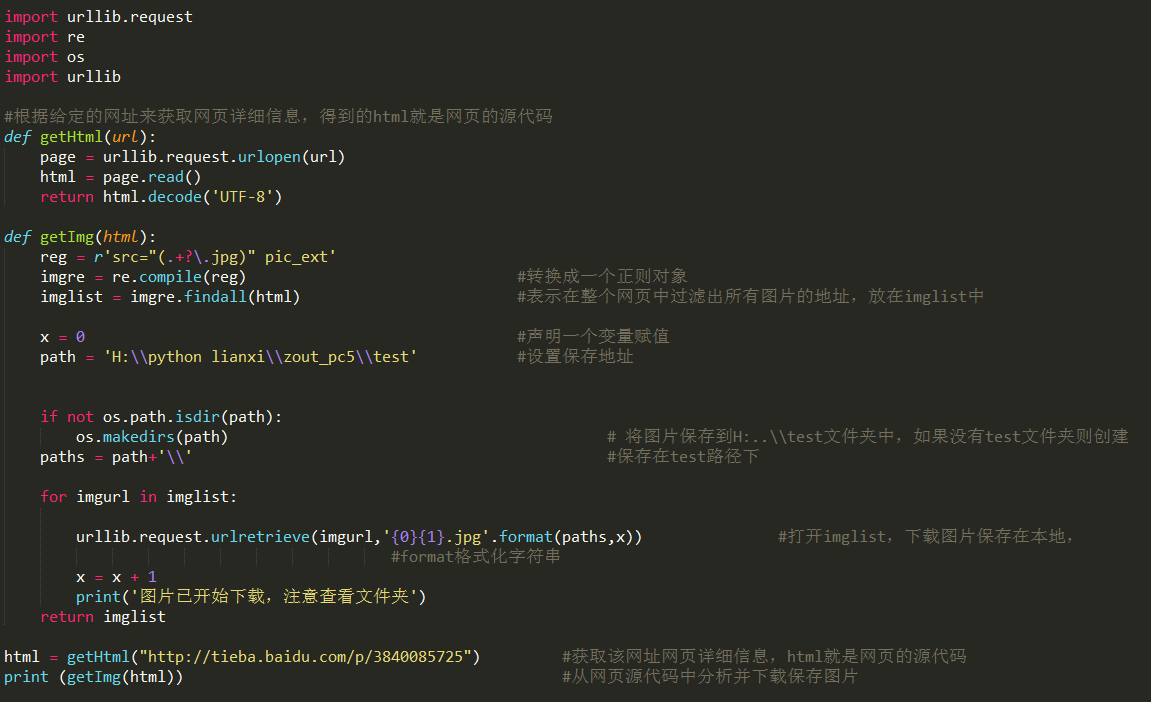
算了,不說那麼多廢話,既然是個簡單例子,那我就直接貼代碼吧。相信也沒多少人呢看不懂。
提一句:用BeautifulSoup就可以不用正則;爬蟲用正則,Bs4, xpath三種 選擇一個就好。當然也可以混合使用,也還有其他種。
掌握上面的爬蟲三步驟,一些簡單的網站都可以直接搞定!

下麵用一個小案例吧!
環境
需求:python3x pycharm
模塊:urllib 、urllib2、bs4、re
代碼: