
在進行網頁數據抓取時我們要先安裝一個模塊 requests 通過終端安裝如下圖 因為我之前安裝過了,所以不會顯示安裝進度條,安裝也非常簡單,如果你配置好環境變數的話,你只需要執行以下命令 如果提示要升級,就按下麵升級pip 安裝完模塊後我們正式開始進行數據爬取 先說一下requests的用法,導入這 ...
在進行網頁數據抓取時我們要先安裝一個模塊
requests
通過終端安裝如下圖
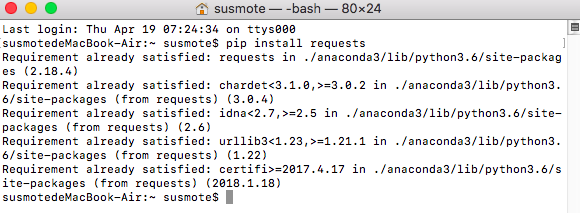
因為我之前安裝過了,所以不會顯示安裝進度條,安裝也非常簡單,如果你配置好環境變數的話,你只需要執行以下命令
pip install requests
如果提示要升級,就按下麵升級pip
pip install --upgrade pip
安裝完模塊後我們正式開始進行數據爬取
先說一下requests的用法,導入這個模塊後,你只需要調用一下get方法,就能獲取網頁的內容了
例如,爬取我的博客首頁,這個單網頁
In [1]: import requests
In [2]: resp = requests.get("http://www.susmote.com")
In [3]: resp.encoding = "utf-8"
In [4]: type(resp.text)
Out[4]: str
In [5]: content = resp.text[0:100]
In [6]: print(content)
<!DOCTYPE html>
<html lang="zh-Hans">
<head>
<meta http-equiv="Content-Type" content="text/html; ch
首先導入,然後調用get方法,裡面接你要爬取的網頁
註意:必須要加http:頭,不然會報錯
然後在第三步,我們更改了預設編碼,這個取決於你要爬取網頁的編碼格式,如果不更改,極大可能會出行亂碼,或是一些沒有看過的字元
在第五步,我們把爬取網頁內容的前50個字元賦值給了content,以便之後查看,因為網頁內容太多,不能一次全部列印出來,所以我們決定切片輸出一部分內容
最後一步,我們列印出剛纔保存的一部分內容
前面只是提前熟悉一下爬取數據的步驟,接下來我們通過列表字典批量獲取數據,然後把它保存為一個文件
首先定義一個字典,存儲我們要抓取頁面的網址
urls_dict = {
'特克斯博客': 'http://www.susmote.com/',
'百度': 'http://www.baidu.com',
'xyz': 'www.susmote.com',
'特克斯博客歌單區1': 'https://www.susmote.com/?cate=13',
'特克斯博客歌單區2': 'https://www.susmote.com/?cate=13'
}
然後我們在定義一個列表,也是存儲抓取頁面的網址
urls_lst = [
('特克斯博客', 'http://www.susmote.com/'),
('百度', 'http://www.baidu.com'),
('xyz', 'www.susmote.com'),
('特克斯博客歌單區1', 'https://www.susmote.com/?cate=13'),
('特克斯博客歌單區2', 'https://www.susmote.com/?cate=13')
]
然後我們先利用字典來抓取
代碼如下:
# 利用字典抓取
crawled_urls_for_dict = set()
for ind, name in enumerate(urls_dict.keys()):
name_url = urls_dict[name]
if name_url in crawled_urls_for_dict:
print(ind, name, "已經抓取過了.")
else:
try:
resp = requests.get(name_url)
except Exception as e:
print(ind, name, ":", str(e)[0:50])
continue
resp.encoding = "utf8"
content = resp.text
crawled_urls_for_dict.add(name_url)
with open("bydict_" + name + ".html", 'w', encoding='utf8') as f:
f.write(content)
print("抓取完成 : {} {}, 內容長度為{}".format(ind, name, len(content)))
首先定義一個空集合,以保存我們抓取完數據的網址,以避免重覆抓取
後面我們通過for迴圈和枚舉,遍歷每一個字典的鍵和值,把每一抓取的網址存進開始定義的集合crawled_urls_for_dict
然後我們判斷要抓取的網址,是否已經保存在集合中,如果存在,就輸出已經抓取過了
如果沒有,再進行後面的操作,在這裡我們為了防止程式出錯,影響程式的整體運行,我們在這裡使用了try except 語句來列印出錯的異常,這樣能保證程式能完整運行
然後無非和我之前說的一樣,改編碼格式,暫時保存內容
只是最後我們通過創建一個文件來保存爬取下來的網頁文件,這個我就不詳細解釋了,無非就是加了個尾碼
在後面我們列印抓取的網頁地址
for u in crawled_urls_for_dict:
print(u)
然後我們利用列表來抓取數據
代碼如下
# 利用列表抓取
crawled_urls_for_list = set()
for ind, tup in enumerate(urls_lst):
name = tup[0]
name_url = tup[1]
if name_url in crawled_urls_for_list:
print(ind, name, "已經抓取過了.")
else:
try:
resp = requests.get(name_url)
except Exception as e:
print(ind, name, ":", str(e)[0:50])
continue
resp.encoding = "utf8"
content = resp.text
crawled_urls_for_list.add(name_url)
with open('bylist_' + name + ".html", "w", encoding='utf8') as f:
f.write(content)
print("抓取完成:{} {}, 內容長度為{}".format(ind, name, len(content)))
原理上跟前面的字典一樣,我就不做過多解釋了
只是要註意這是一個嵌套的列表,遍歷的時候要註意一下
最後也是一樣
for u in crawled_urls_for_list:
print(u)
列印抓取過的數據
運行結果如下圖
susmotedeMacBook-Air:FirstDatamining susmote$ python main.py 抓取完成 : 0 特克斯博客, 內容長度為26793 抓取完成 : 1 百度, 內容長度為2287 2 xyz : Invalid URL 'www.susmote.com': No schema supplied. 抓取完成 : 3 特克斯博客歌單區1, 內容長度為21728 4 特克斯博客歌單區2 已經抓取過了. http://www.susmote.com/ http://www.baidu.com https://www.susmote.com/?cate=13 ------------------------------------------------------------ 抓取完成:0 特克斯博客, 內容長度為26793 抓取完成:1 百度, 內容長度為2287 2 xyz : Invalid URL 'www.susmote.com': No schema supplied. 抓取完成:3 特克斯博客歌單區1, 內容長度為21728 4 特克斯博客歌單區2 已經抓取過了. http://www.susmote.com/ http://www.baidu.com https://www.susmote.com/?cate=13
文件目錄變化如下
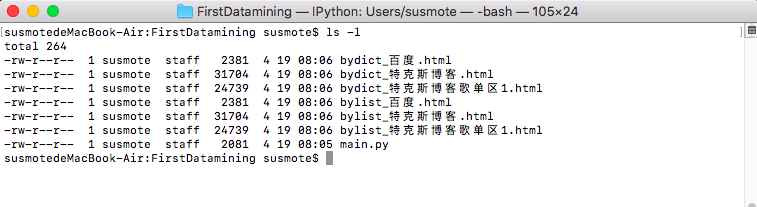
用瀏覽器打開如下圖
特克斯博客 www.susmote.com

百度網站 www.baidu..com
到這裡,簡單的數據抓取就講完了
歡迎訪問我的官網
www.susmote.com


