
本文目錄:1.集合的特征2.集合的無序性3.表中記錄的無序性4.集合的"序"和物理存儲順序之間的關係5.查詢結果(虛擬表)的無序性、隨機性6.為什麼總是強調"無序"?7.什麼時候的結果是有序的?8.索引的"序" 1.集合的特征 關係型資料庫,一方面它是資料庫,可以存儲數據,另一方面,它是關係的,也就 ...
本文目錄:
1.集合的特征
2.集合的無序性
3.表中記錄的無序性
4.集合的"序"和物理存儲順序之間的關係
5.查詢結果(虛擬表)的無序性、隨機性
6.為什麼總是強調"無序"?
7.什麼時候的結果是有序的?
8.索引的"序"
1.集合的特征
關係型資料庫,一方面它是資料庫,可以存儲數據,另一方面,它是關係的,也就是基於關係模型的。在關係型資料庫中,專門為關係模型設計了對應的"關係引擎",關係引擎中包含了語句分析器、優化器、查詢執行器。語句分析器用於分析語句是否正確,優化器用於生成查詢的執行計劃,查詢執行器按照優化器生成的執行計划去執行查詢操作,並將相關操作指令交給存儲引擎,由存儲引擎跟底層的數據(磁碟/緩存)打交道。
這裡我們不談數據存儲,而是站在資料庫的角度上談關係模型的一個特性:基於集合理論。
高中數學里,我們都學過集合有三個特征:確定性、互異性和無序性。其中確定性和互異性是成為集合的條件,無序性是集合的特性。
確定性指的是集合中的元素必須是明確的,不能在集合中存放一個可能大於2,也可能大於3這樣的元素。在關係型資料庫中,這一特征可以不用考慮,因為數據只要存到資料庫中,數據就一定是確定的。
互異性是指集合中的元素不能重覆。在關係型資料庫中,記錄是否重覆的問題沒有嚴格的規範。一方面,各種各樣的業務邏輯不允許在資料庫的角度上嚴格限制記錄的重覆性。另一方面,可以通過設置主鍵或者唯一索引來保證記錄之間不重覆,也就是"唯一性"。在很多情況下,具有唯一性的表能優化查詢,減少記錄的檢索次數。
無序性是指集合中的元素之間是無序的。在關係型資料庫中,對集合的無序性實現的最完整。甚至可以說,無序性貫穿了整個關係型資料庫,尤其是關係引擎中的優化器更是關註"序"這個概念。
因此,本文主要圍繞集合的"序",來解釋關係型資料庫中和"序"有關的行為。
2.集合的無序性
這裡的"序",不是指數據按大小排過序,也不是指物理存儲數據時排過序,而是站在集合的角度或關係引擎的角度(若不理解,就當是資料庫角度)上看"數據是否有序"的概念,它是邏輯上的"序"。
舉個例子就能理解。集合A(1,2,3,4)和集合B(2,1,4,3),看上去集合A中元素是有序的,集合B中元素是無序的。
如果要從集合A和集合B中取出小於2的元素,無論是集合A還是集合B都要比較4次才能得到最終結果,因為集合併不知道元素2的後面是否還有比2小的值。而且對於集合來說,根本就沒有前面和後面的概念。
也就是說,對於集合A來說,2是第二個元素是錯誤的說法。集合中不應該有"第"這種說法(資料庫也如此,只要檢索的對象不是order by後的結果或游標對象,取第幾行這種概念將總是按照物理存儲順序去訪問的)。
如果我們使用下圖的模式去看待這兩個集合,也用這種模式去看到資料庫表中的記錄,很多時候更有助於理解sql語法的本質和sql優化。

所以,這兩個集合是等價的集合,只不過這裡的集合A,在我們人眼中碰巧有序而已。這也是資料庫中索引的意義,我們人為地將集合中的元素排序,人為地告訴優化器它們是有序的,即使關係引擎依舊認為它是無序的。
我們可以站在集合整體的角度上看待"序"這個概念。集合不關註其內部的元素是什麼,它只關註它自身是一個容器,包含了一堆滿足集合條件的元素。當需要找出集合中某個或某些具體的元素時,需要掃描整個集合。
3.表中記錄的無序性
站在資料庫層面來講,關係型資料庫表中的數據是無序的,也就是我們俗稱的"堆heap"。我們應該這樣看待表中的每行記錄:
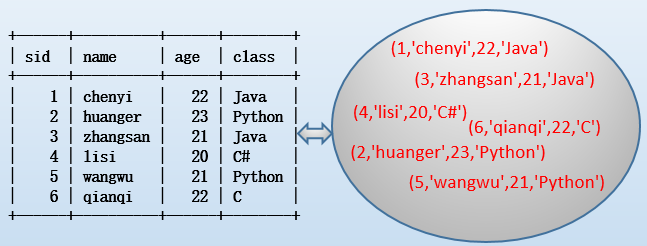
你可能會疑惑,使用(B+樹)索引不是可以將表中所有數據排序後存儲嗎?沒錯,但在關係引擎看來,這個表仍然是集合的,它是一個亂序的整體,其內每行數據也都認為是無序的。只不過在檢索數據的時候,優化器在生成執行計劃時能發現已經存在索引,它知道這些數據是根據索引排過序的,藉此生成成本更低的執行計劃。
轉換成上面集合的說法,索引的意義就是讓集合B(2,1,4,3)變成集合A(1,2,3,4),讓集合中的元素能夠使用"第幾"這種概念。
例如,在集合的層次上要找出值大於2的元素,需要掃描整個集合,即需要比較4次才能得到結果。同理,沒有使用索引的表也一樣會進行表掃描才能得到最終結果。當使用索引後,也就是人為地將集合B變成集合A,對於我們人來說,只要從前向後找,當找到第一個大於2的元素後(請註意,不是等於2,而是大於2,這兩種行為是有區別的),就知道它後面的所有元素一定是大於2的。對於資料庫來說,索引就是我們人為告訴優化器這個表排序過,優化器自然知道只要找到符合條件的記錄。
題外話:從這裡是否感受到了關係引擎和優化器之間的關係?
- 對於關係引擎來說,整個表都是無序的。如果沒有優化器組件,關係引擎(查詢執行器,後文將直接使用關係引擎來表示查詢執行器的行為)會進行表掃描,如果沒有索引,關係引擎也會進行表掃描。但是有了優化器,且經過"我們的提醒"後,優化器就能決定關係引擎的執行計劃:走索引。
- 另外,既然我們能隱式"提醒"優化器表存在索引,那麼我們也能顯式"提醒"優化器優化器有別的索引,甚至強制"提醒"優化器沒有索引。這就是為什麼關係型資料庫中都會有"hint"關鍵字的原因。
- 絕大多數情況下,我們應該完全信任優化器,相信它能幫我們選出成本最低的執行計劃。但優化器有時候也會"聰明反被聰明誤",選出一條不怎麼好甚至性能極低的執行計劃,這時我們要hint強制干涉,由我們自己告訴優化器應該怎麼走索引、走哪條索引。
- 從這方面看,一個不支持hint功能的資料庫系統是不合格的資料庫系統,比如老版本的PostgreSQL。當然,在2012年它已經添加了hint的擴展功能。
再來看看無序表聯接的問題。當無序表1和無序表2進行內聯接、外聯接時,我們應該這樣看待聯接的本質:
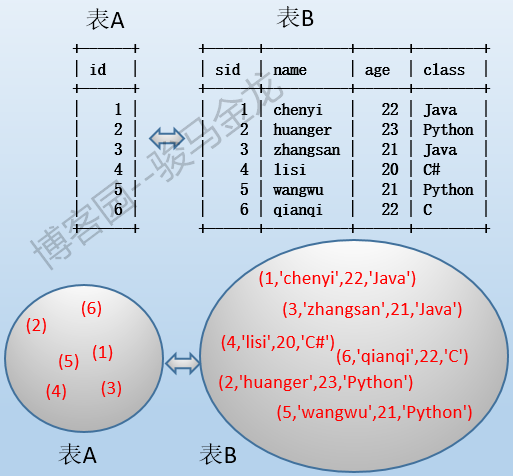
這也是站在關係引擎角度上看聯接的本質。由於無序,關係引擎只能對兩個表都進行表掃描並逐一比對,這樣就形成了我們常說的"笛卡爾積"。無疑,這樣的效率很低。為了提高聯接時的效率,應該儘可能多地減少記錄的掃描次數,這是聯接語句優化的本質。
雖然總是提到索引,感覺索引能帶來性能上的提高,但無論如何請記得,對於關係引擎來說,表是集合的,是無序的,不管它是否有索引,是否人為排序過。至於索引,它是優化器才認識的東西,關係引擎不認識。
4.集合的"序"和物理存儲順序之間的關係
先簡單說說資料庫是如何存儲數據的。
在資料庫系統中,表中的所有數據都存儲在資料庫文件中,這是磁碟上的文件。但在資料庫看來,表中的每一行數據都是存放在"頁"上的。頁是資料庫操作的最小單位,例如想讀取某一行數據時(假如走索引,不會表掃描),存儲引擎會將這行數據所在的一整頁地載入到記憶體中,並掃描這一頁。
數據頁中,使用槽位(slot)來記錄每一行數據,每個槽表示一行數據。例如,下圖是一個頁面的大致示意圖(不同資料庫系統有所不同,但不影響理解):
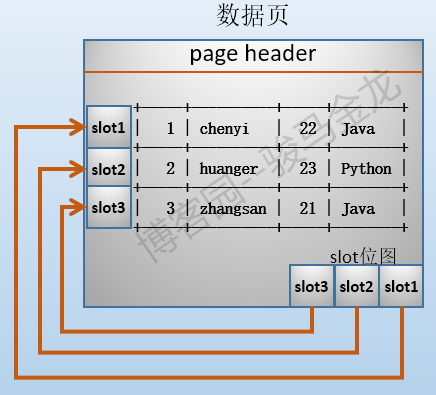
這個頁面中每插入一行數據,就分配一個槽位,併在槽點陣圖上標記這個槽的位置(比如距離頁面頂端的偏移位元組是多少),這樣就能知道這一行數據在頁中的位置。
而我們所說的"物理存儲順序"就是槽點陣圖標記的順序。註意,不是頁面空間上的前後位置。因為槽位的順序和頁面空間的位置可能是不一致的,例如下圖:
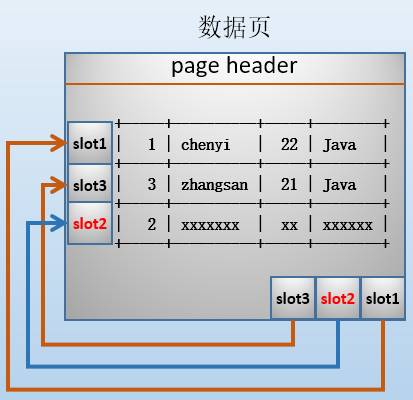
在頁面的空間位置上,slot2對應的記錄行在3的後面,但是掃描這個頁面的時候,將先掃描slot2,再掃描slot3。也就是說,物理順序是slot點陣圖的順序(或者說,將先返回slot2對應的行)。
在堆表中,slot點陣圖的和頁面的空間位置是完全對應的。刪除一行數據,這行數據的槽位會保留,只不過槽點陣圖上的偏移會指向0。當插入新數據的時候,這個新數據可能會直接插入到這個槽位中(如果這個槽位裝不下這行數據,則會尋找其他的槽位)。
而在有索引的情況下,slot的順序和頁面空間的位置順序可能不一樣,這關乎到索引的類型。例如插入2,它是1和3中間的值,按理說應該插在slot1對應行的後面,但這樣會使得slot3向後移動。而這樣的設計,可以讓數據直接插在頁面的尾部,只需要對slot號碼重新編號即可。性能要提高不少。
上面說的是單個頁內部的數據行順序問題。除了頁內順序,還有頁間的順序。例如頁面2緊跟在頁面1的後面,我們稱之為"頁面是連續的",但如果頁面2在頁面1的前面,或者頁面1和頁面2中間隔了很多其他的頁,我們稱之為"頁面不連續"。在頁面不連續的時候,存儲引擎需要不斷地進行頁面跳躍,反映到磁碟上就是需要不斷的定址。而我們知道,機械硬碟花在定址的時間上遠遠高於讀取數據的時間。這也稱之為"頁面碎片",當碎片較多的時候,它會對性能造成極大的影響。
本文不會去詳細介紹這些東西。在這裡,唯一需要知道的就是"數據存儲的物理順序並不是空間上的前後順序"。
那麼,集合的"序"和物理存儲順序之間有什麼關係呢?
在關係引擎看來表中的數據是無序的,但即使無序,數據也已經持久化到磁碟上了。它總要找出一個能掃描所有數據的方案。在不走索引的情況下,優化器無其他路可選,它只能按照物理存儲順序進行表掃描。在這之後,如果沒有排序演算法對數據進行排序,那麼之後所有的操作都按照這個順序訪問數據。
因此,★★★★★★物理存儲順序是無序的起點,是數據隨機性的起點。★★★★★★虛擬表之所以無序,就是從這裡物理存儲順序開始的,當表掃描(或載入部分頁面)完成後,已經載入完成的數據已經固定在記憶體中,是有固定順序的,這時候已經不適合稱之為"無序",而應該稱之為"隨機"。
5.查詢結果(虛擬表)的無序性、隨機性
除了資料庫中的實體表,在查詢的時候,中途生成的虛擬表都是無序的,但order by和distinct後的結果除外。關於order by的結果,見後文的說明。
簡單的幾個例子。
首先創建示例表,並查看表結構和數據如下:
MariaDB [test]> create table Student1 (sid int ,name char(20),age int,class char(20));
MariaDB [test]> insert into Student1 values(3,'zhangsan',21,'Java');
(6,'zhaoliu',19,'Java'),
(2,'huanger',23,'Python'),
(1,'chenyi',22,'Java'),
(4,'lisi',20,'C#'),
(5,'wangwu',21,'Python'),
(7,'qianqi',22,'C'),
(8,'sunba',20,'C++'),
(9,'yangjiu',24,'Java');
MariaDB [test]> select * from Student1;
+------+----------+------+--------+
| sid | name | age | class |
+------+----------+------+--------+
| 3 | zhangsan | 21 | Java |
| 6 | zhaoliu | 19 | Java |
| 2 | huanger | 23 | Python |
| 1 | chenyi | 22 | Java |
| 4 | lisi | 20 | C# |
| 5 | wangwu | 21 | Python |
| 7 | qianqi | 22 | C |
| 8 | sunba | 20 | C++ |
| 9 | yangjiu | 24 | Java |
+------+----------+------+--------+
這裡面沒有任何索引,無論是關係引擎,還是優化器,都認為這個表是無序的,因此只能執行表掃描。而表掃描的過程是按照數據的"物理存儲順序"進行訪問的,sid=3的記錄先存進資料庫,就先訪問這個記錄(按照前文的物理存儲方式,這個說法是錯誤的,但現在忽略這個問題)。在沒有任何索引、沒有任何優化"提醒"時,優化器就會生成"按照物理存儲順序"的執行計划去表掃描。
但是表掃描的結果對於我們人類來說是無序的結果,更準確的說,是隨機的結果,是我們無法去預料的結果。因為堆中的數據在進行物理存儲時,可能會"見縫插針",而我們根本不知道這根"針"插在哪個"縫"里,也不知道它前面的數據是什麼,後面的數據是什麼。例如,堆表中的部分數據刪除了,再插入一部分數據,新插入的數據有些可能會插入在表的尾部,有些也可能插在數據刪除後留下的"槽"(slot)中。
再來說明查詢執行過程中生成的虛擬表。虛擬表是邏輯的概念,是SQL語句執行過程中每一個階段產生的數據集合,在我們人的感官上,我們會把這個集合看成虛擬表。但多數時候,它們並不真的是二維表結構的形式,只是記憶體中一段存儲了數據的緩存空間。少數時候,由於演算法或某些操作的需要,會實實在在地創建虛擬臨時表,例如使用DISTINCT子句對結果去重時,就會先生成一張臨時表用於排序並去重。
例如,在兩表聯接時我們總說會產生"笛卡爾積",然後用一張二維表的形式去感受這個笛卡爾積的虛擬表。

但在實際執行過程中不會是這樣的表結構,而應該是下麵這種結構。
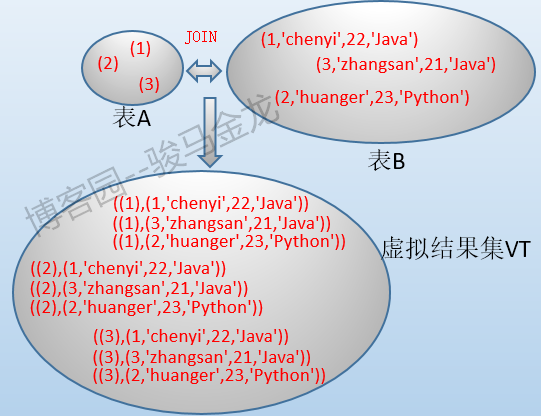
也就是說,虛擬結果集中的數據是無序的,隨後對該虛擬結果集的操作也是隨機而無法保證順序的。例如上面的笛卡爾積結果集,如果使用了WHERE子句篩選某些行,則篩選的過程是對笛卡爾積進行"表"掃描,但笛卡爾積本就是不保證順序的,所以當where篩選出多行時,這些行的順序可能會和我們預料的結果有所不同。當然,優化器不會真的採用這樣的方案,但站在邏輯角度上看,因為虛擬結果集無序,要從中檢索數據只能進行"表"掃描。
再比如說TOP子句(MySQL、MariaDB中等價的是LIMIT子句),如果沒有結合ORDER BY子句,那麼TOP將從其前面的虛擬結果集中按某種順序挑出滿足數量的行出來,挑出的這些行是我們人無法預料的,所以TOP的結果是隨機的。這裡的"某種順序"並非有序,例如從上圖的笛卡爾積中選一行時,由於笛卡爾積是無序的,挑選的這一行將受表A的物理存儲順序、表B的物理存儲順序影響。
只有使用了ORDER BY子句,才能保證TOP的結果是可預料而非隨機的,因為ORDER BY的虛擬結果集是有序的。事實上,ORDER BY的結果不應該叫"集",而應該叫"游標對象",因為排序後的結果中,每一行都按照我們期待的順序固定好了位置,之後TOP再去操作這樣的結果就一定能得到我們預料之中的數據。
6.為什麼總是強調"無序"
通過前面的內容,我們已經發現無序性的最大問題在於返回結果的無法預測性。返回結果無法預測,意味著數據增、刪、改的時候存在危險,意味著我們可能對檢索的數據認知不足。
7.什麼時候的數據是有序的?
前面說了一大堆,總結一下就是:數據都是無序的,每一步的檢索都有隨機性,無法保證能達到我們人的期待。但是,關係型資料庫中的所有數據都是無序,都是隨機的嗎?換句話說,上面的總結對嗎?答案是不對。
在關係型資料庫中,我們除了考慮從存儲引擎到磁碟這段路程(受物理存儲順序影響),還要考慮語句執行過程中記憶體中的虛擬表。在前面,我們說虛擬表是無序的,這句話不准確。
一方面,數據載入成功後,它們在記憶體中已經是有序的,但對我們人來說,我們無法看到這樣的"序",也就是說結果是隨機的,是我們無法預料的。
另一方面,當有排序演算法對虛擬表進行排序後,結果也是有序的,這樣的結果是符合我們人所預料的。對於排序後的結果,ANSI將其稱之為"游標對象"。
常見的兩個涉及到排序演算法的子句是ORDER BY和DISTINCT。此處之外,還有游標自身,它的結果也是有序的。
對於ORDER BY子句,它會將它前面的虛擬結果集進行排序,排序的結果集中,每行記錄都固定好了位置,我們可以預料到任何一行數據處於哪個位置,也知道它前面是什麼數據,後面是什麼數據。也就是說,排序後的數據是固定而非隨機的。
對於DISTINCT子句,在對其前面的虛擬結果集進行去重操作時,DISTINCT總會帶有排序操作(即使沒有指定order by,內部也自帶排序),排序之後再對結果集進行去重。例如下麵的表。
id name
---- -----
5 e
2 b
4 d
1 a
2 x
3 c
對id列去重時,它將對id列進行排序,得到的結果將是:
id
----
1
2
3
4
5
結果是有序的。但對於id=2的記錄來說,在去重時應該保留name=b的還是name=x的記錄呢?無法保證,因為DISTINCT只對id列排序,不對id之外的列排序。因此對於有重覆值的記錄,DISTINCT只能返回一個隨機記錄,我們無法預料這個記錄是不是我們想要的結果。
在SQL Server和Oracle中這沒什麼問題,因為使用DISTINCT後,它後面的過程不允許使用非DISTINCT列(DISTINCT後面還有ORDER BY和TOP,但涉及到列的只有ORDER BY子句),因此最終得到的結果只有指定的去重列(id列)。但是在MySQL/MariaDB中,ORDER BY允許使用非DISTINCT列,例如select distinct id from t1 order by name,它將先按name排序,再按id排序,最後對id去重。也許你發現了,這種情況下DISTINCT是在ORDER BY之後才執行的,沒錯,事實就是如此。
8.索引的"序"
無論是MySQL還是SQL Server(Oracle的知識都忘光了,所以不說它了),都可以創建"聚集索引"和"非聚集索引"(MySQL中沒有這種稱呼,但它的主鍵索引就是聚集索引,非主鍵索引就是非聚集索引,非聚集索引有時候也稱之為secondary index)。它們都是B+樹的組織結構。
對於聚集索引,B+樹的葉級頁包含了所有數據行以及所有列(有些時候還包括一個或兩個額外的列),它們是排過序的。但是這種排序是通過雙鏈表和指針的方式實現的。
例如,表中有數據行1,2,3,4,5,6,假設這幾行數據都較大,每兩行占用一個數據頁面,那麼存儲數據的數據頁總共需要3頁(假設分別稱為A、B、C頁)。
這3頁之間通過雙鏈表的方式組織起來,例如B頁的page header中記錄了它前一頁是A,後一頁是C,C頁的page header中記錄了它的前一頁是B,沒有後一頁(用0表示)。
而對於頁面內的數據,則是通過slot槽位偏移指針來組織的。在前面的"物理存儲順序"一節中已經說明瞭這個葉級頁是如何每行數據的。
無論是聚集索引還是非聚集索引,都必須要有一列或多列能唯一識別每一行記錄。可以通過同時創建唯一性索引的方式實現,在沒有創建唯一性索引時,系統內部會自動添加一個列,幫助索引列唯一識別每一行記錄,只不過當沒有重覆值的時候,這一列占用的空間未0。
總之,有了索引,無論是聚集還是非聚集索引,都一定能保證每一行數據都唯一,每一行數據在排序時都有完全確定的位置。也就是說,當我們走索引去檢索數據的時候,數據不再無序,返回的結果也總能預料到。
回到Linux系列文章大綱:http://www.cnblogs.com/f-ck-need-u/p/7048359.html
回到網站架構系列文章大綱:http://www.cnblogs.com/f-ck-need-u/p/7576137.html
回到資料庫系列文章大綱:http://www.cnblogs.com/f-ck-need-u/p/7586194.html
轉載請註明出處:http://www.cnblogs.com/f-ck-need-u/p/8718662.html
註:若您覺得這篇文章還不錯請點擊右下角推薦,您的支持能激發作者更大的寫作熱情,非常感謝!


