
前言: Storm讀取實時數據流,並傳遞給處理單元,最終輸出處理後的數據。 下圖描述了storm的處理數據的主要結構。 元組(Tuple) : 元組是Storm提供的一個輕量級的數據格式,可以用來包裝你需要實際處理的數據。元組是一次消息傳遞的基本單元。一個元組是一個命名的值列表,其中的每個值都可以是 ...
前言:
Storm讀取實時數據流,並傳遞給處理單元,最終輸出處理後的數據。
下圖描述了storm的處理數據的主要結構。
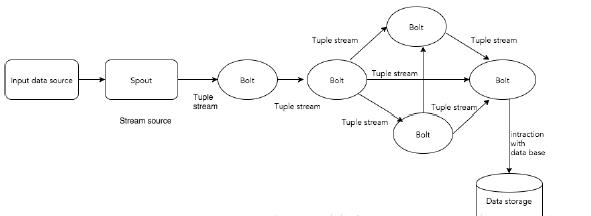
元組(Tuple) :
元組是Storm提供的一個輕量級的數據格式,可以用來包裝你需要實際處理的數據。元組是一次消息傳遞的基本單元。一個元組是一個命名的值列表,其中的每個值都可以是任意類型的。元組是動態地進行類型轉化的(欄位的類型不需要事先聲明)。在Storm中編程時,就是在操作和轉換由元組組成的流。通常,元組包含整數,位元組,字元串,浮點數,布爾值和位元組數組等類型。要想在元組中使用自定義類型,就需要實現自己的序列化方式。
流(Stream) :
一個流由無限的元組序列組成,這些元組會被分散式並行地創建和處理。通過流中元組包含的欄位名稱來定義這個流。
每個流聲明時都被賦予了一個ID。只有一個流的Spout和Bolt非常常見,所以OutputFieldsDeclarer提供了不需要指定ID來聲明一個流的函數(Spout和Bolt都需要聲明輸出的流)。這種情況下,流的ID是預設的“default”。
Spouts :
Spout(噴嘴)是Storm中流的來源。通常Spout從外部數據源,如消息隊列中讀取元組數據並吐到拓撲里。Spout可以是可靠的(reliable)或者不可靠(unreliable)的。可靠的Spout能夠在一個元組被Storm處理失敗時重新進行處理,而非可靠的Spout只是吐數據到拓撲里,不關心處理成功還是失敗了。
Spout可以一次給多個流吐數據。此時需要通過OutputFieldsDeclarer的declareStream函數來聲明多個流併在調用SpoutOutputCollector提供的emit方法時指定元組吐給哪個流。
Spout中最主要的函數是nextTuple,Storm框架會不斷調用它去做元組的輪詢。如果沒有新的元組過來,就直接返回,否則把新元組吐到拓撲里。nextTuple必須是非阻塞的,因為Storm在同一個線程里執行Spout的函數。
Spout中另外兩個主要的函數是ack和fail。當Storm檢測到一個從Spout吐出的元組在拓撲中成功處理完時調用ack,沒有成功處理完時調用fail。只有可靠型的Spout會調用ack和fail函數。
Bolts :
storm是一種分散式實時計算系統,而storm topology中,所有的實時計算的業務邏輯都是定義在bolt中的。bolt中可以做任何計算邏輯,比如過濾、執行自定義的函數、聚合、join、訪問資料庫,等等。簡而言之,bolt實際上就是我們實現或者繼承了storm提供的介面或基類,自己開發的類。
接著看一個實例,如何通過Apache Storm來構建Twitter Analysis。結構如下圖所示。

通過Twitter Streaming API為Twitter Analysis提供輸入數據。Spout通過Twitter Streaming API讀取數據,並以tuple流的形式輸出。隨後tuple將轉發給bolt,bolt將會對tuple進行處理。
Topology(拓撲):
storm topology和mapreduce job是有些類似的。唯一關鍵的區別就在於,mapreduce job是肯定會結束運行的;但是storm topology是永遠會運行的,除非你自己手動殺了它。
使用storm開發的實時計算應用程式,所有的計算邏輯都在topology中。一個topology,其實就是邏輯上的計算流向圖,由spout和bolt組成。一個topology可以包含一個或者多個spout和bolt。而spout和bolt,就是topology這個計算流向圖種的一個一個的計算節點,其中包含了我們自己編寫的計算代碼。spout和bolt之間的關係和聯繫,其實就定義了實時計算的數據流向。可以想象成,數據從外部讀入spout,然後傳輸到後面一個一個的bolt;而bolt之間的數據流向,可能是交叉層疊的,看起來整個topology就像一個DAG(有向無環圖)一樣。 簡而言之,topology,就是邏輯上的實時計算拓撲圖。
Tasks(任務):
Spout 和 bolt是topology中的最小邏輯單元。topology是通過一個spout和一組bolt構建。邏輯單元需要按特定的順序來執行。Storm所執行的每個spout和bolt稱為task。簡而言之,spout或bolt的執行稱為task。每個spout和bolt都可以有多個不同的實例運行在不同的線程中。(每一個task對應到一個線程)。
Workers:
toplogy是在分散式環境下,多個worker節點上運行。storm將任務均勻分配在所有worker節點上。work節點的作用是監聽任務(jobs),當有新任務來時,啟動或停止任務的處理。每個worker是一個物理JVM並且執行整個topology的一部分。
Stream Grouping:
流分組,是拓撲定義中的一部分,為每個bolt指定應該接收哪個流作為輸入。流分組定義流/元組如何在bolt的任務之間進行分發。
感謝您閱讀上海大數據培訓文章,
更多推薦閱讀:
【上海大數據培訓】storm集群架構;
【上海大數據培訓】storm如何分配任務和負載均衡

