
嵌入式開發常見問題解決方法 一、問題復現 穩定復現問題才能正確的對問題進行定位、解決以及驗證。一般來說,越容易復現的問題越容易解決。 1.1 模擬復現條件 有的問題存在於特定的條件下,只需要模擬出現問題的條件即可復現。對於依賴外部輸入的條件,如果條件比較複雜難以模擬可以考慮程式里預設直接進入對應狀態 ...
嵌入式開發常見問題解決方法
一、問題復現
穩定復現問題才能正確的對問題進行定位、解決以及驗證。一般來說,越容易復現的問題越容易解決。
1.1 模擬復現條件
有的問題存在於特定的條件下,只需要模擬出現問題的條件即可復現。對於依賴外部輸入的條件,如果條件比較複雜難以模擬可以考慮程式里預設直接進入對應狀態。
1.2 提高相關任務執行頻率
例如某個任務長時間運行才出現異常則可以提高該任務的執行頻率。
1.3 增大測試樣本量
程式長時間運行後出現異常,問題難以復現,可以搭建測試環境多套設備同時進行測試。
二、問題定位
縮小排查範圍,確認引入問題的任務、函數、語句。
2.1 列印LOG
根據問題的現象,在抱有疑問的代碼處增加LOG輸出,以此來追蹤程式執行流程以及關鍵變數的值,觀察是否與預期相符。
2.2 線上調試
線上調試可以起到和列印LOG類似的作用,另外此方法特別適合排查程式崩潰類的BUG,當程式陷入異常中斷(HardFault,看門狗中斷等)的時候可以直接STOP查看call stack以及內核寄存器的值,快速定位問題點。
2.3 版本回退
使用版本管理工具時可以通過不斷回退版本並測試驗證來定位首次引入該問題的版本,之後可以圍繞該版本增改的代碼進行排查。
2.4 二分註釋
“二分註釋”即以類似二分查找法的方式註釋掉部分代碼,以此判斷問題是否由註釋掉的這部分代碼引起。具體方法為將與問題不相干的部分代碼註釋掉一半,看問題是否解決,未解決則註釋另一半,如果解決則繼續將註釋範圍縮小一半,以此類推逐漸縮小問題的範圍。
2.5 保存內核寄存器快照
Cortex M內核陷入異常中斷時會將幾個內核寄存器的值壓入棧中,如下圖:
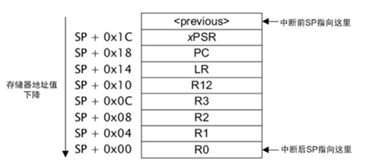
我們可以在陷入異常中斷時將棧上的內核寄存器值寫入RAM的一段複位後保留預設值的區域內,執行複位操作後再從RAM將該信息讀出並分析,通過PC、LR確認當時執行的函數,通過R0-R3分析當時處理的變數是否異常,通過SP分析是否可能出現棧溢出等。
三、問題分析處理
結合問題現象以及定位的問題代碼位置分析造成問題的原因。
3.1 程式繼續運行
3.1.1 數值異常
3.1.1.1 軟體問題
數組越界
寫數組時下標超出數組長度,導致對應地址內容被修改。如下:
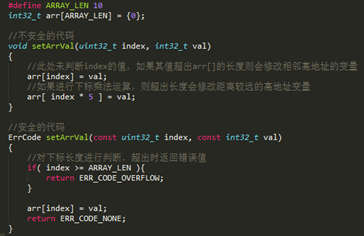
此類問題通常需要結合map文件進行分析,通過map文件觀察被篡改變數地址附近的數組,查看對該數組的寫入操作是否存在如上圖所示不安全的代碼,將其修改為安全的代碼。
棧溢出
|
0x20001ff8 |
g_val |
|
0x20002000 |
棧底 |
|
………… |
棧空間 |
|
0x20002200 |
棧頂 |
如上圖,此類問題也需要結合map文件進行分析。假設棧從高地址往低地址增長,如果發生棧溢出,則g_val的值會被棧上的值覆蓋。出現棧溢出時要分析棧的最大使用情況,函數調用層數過多,中斷服務函數內進行函數調用,函數內部申明瞭較大的臨時變數等都有可能導致棧溢出。
解決此類問題有以下方法:
1、 在設計階段應該合理分配記憶體資源,為棧設置合適的大小;
2、 將函數內較大的臨時變數加”static”關鍵字轉化為靜態變數,或者使用malloc()動態分配,將其放到堆上;
3、 改變函數調用方式,降低調用層數。
判斷語句條件寫錯

判斷語句的條件容易把相等運算符“==”寫成賦值運算符“=”導致被判斷的變數值被更改,該類錯誤編譯期不會報錯且總是返回真。建議將要判斷的變數寫到運算符的右邊,這樣錯寫為賦值運算符時會在編譯期報錯。還可以使用一些靜態代碼檢查工具來發現此類問題。
同步問題
例如操作隊列時,出隊操作執行的過程中發生中斷(任務切換),並且在中斷(切換後的任務)中執行入隊操作則可能破壞隊列結構,對於這類情況應該操作時關中斷(使用互斥鎖同步)。
優化問題
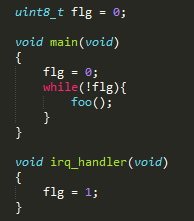
如上圖程式,本意是等待irq中斷之後不再執行foo()函數,但被編譯器優化之後,實際運行過程中flg可能被裝入寄存器並且每次都判斷寄存器內的值而不重新從ram里讀取flg的值,導致即使irq中斷發生foo()也一直運行,此處需要在flg的申明前加“volatile”關鍵字,強制每次都從ram里獲取flg的值。
3.1.1.2 硬體問題
晶元BUG
晶元本身存在BUG,在某些特定情況下給單片機返回一個錯誤的值,需要程式對讀回的值進行判斷,過濾異常值。
通信時序錯誤

例如電源管理晶元Isl78600,假設現在兩片級聯,當同時讀取兩片的電壓採樣數據時,高端晶元會以固定周期通過菊花鏈將數據傳送到低端晶元,而低端晶元上只有一個緩存區,如果單片機不在規定時間內將低端晶元上的數據讀走那麼新的數據到來時將會覆蓋當前數據,導致數據丟失。此類問題需要仔細分析晶元的數據手冊,嚴格滿足晶元通信的時序要求。
3.1.2 動作異常
3.1.2.1 軟體問題
設計問題
設計中存在錯誤或者疏漏,需要重新評審設計文檔。
實現與設計不符
代碼的實現與設計文檔不相符需要增加單元測試覆蓋所有條件分支,進行代碼交叉review。
狀態變數異常
例如記錄狀態機當前狀態的變數被篡改,分析該類問題的方法同前文數值異常部分。
3.1.2.2 硬體問題
硬體失效
目標IC失效,接收控制指令後不動作,需要排查硬體。
通信異常
與目標IC通信錯誤,無法正確執行控制命令,需要使用示波器或邏輯分析儀去觀察通信時序,分析是否發出的信號不對或者受到外部干擾。
3.2 程式崩潰
3.2.1 停止運行
3.2.1.1軟體問題
HardFault
以下情況會造成HardFault:
1、 在外設時鐘門未使能的情況下操作該外設的寄存器;
2、 跳轉函數地址越界,通常發生在函數指針被篡改,排查方法同數值異常;
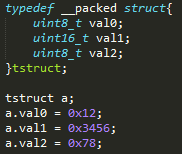
3、 解引用指針時出現對齊問題:
以小端序為例,如果我們聲明瞭一個強制對齊的結構體如下:
|
地址 |
0x00000000 |
0x00000001 |
0x00000002 |
0x00000003 |
|
變數名 |
Val0 |
Val1_low |
Val1_high |
Val2 |
|
值 |
0x12 |
0x56 |
0x34 |
0x78 |
此時a.val1的地址為0x00000001,如果以uint16_t類型去解引用此地址則會因為對齊問題進入HardFault,如果一定要用指針方式操作該變數則應當使用memcpy()。
中斷服務函數中未清除中斷標誌
中斷服務函數退出前不正確清除中斷標誌,當程式執行從中斷服務函數內退出後又會立刻進入中斷服務函數,表現出程式的“假死”現象。
NMI中斷
調試時曾遇到SPI的MISO引腳復用NMI功能,當通過SPI連接的外設損壞時MISO被拉高,導致單片機複位後在把NMI引腳配置成SPI功能之前就直接進入NMI中斷,程式掛死在NMI中斷中。這種情況可以在NMI的中斷服務函數內禁用NMI功能來使其退出NMI中斷。
3.2.1.2 硬體問題
晶振未起振
供電電壓不足
複位引腳拉低
3.2 .2 複位
3.2.2.1 軟體問題
看門狗複位
除了喂狗超時導致的複位以外,還要註意看門狗配置的特殊要求,以Freescale KEA單片機為例,該單片機看門狗在配置時需要執行解鎖序列(向其寄存器連續寫入兩個不同的值),該解鎖序列必須在16個匯流排時鐘內完成,超時則會引起看門狗複位。此類問題只能熟讀單片機數據手冊,註意類似的細節問題。
3.2.2.2 硬體問題
供電電壓不穩
電源帶載能力不足
四、回歸測試
問題解決後需要進行回歸測試,一方面確認問題是否不再復現,另一方面要確認修改不會引入其他問題。
五、經驗總結
總結本次問題產生的原因及解決問題的方法,思考類似問題今後如何防範,對相同平臺產品是否值得借鑒,做到舉一反三,從失敗中吸取經驗。


