
17 Group Replication 17 Group Replication.. 1 17.1 Group Replication後臺... 1 17.1.1 Replication技術... 1 17.1.1.1 主從複製... 1 17.1.1.2 Group Replication.. ...
17 Group Replication
17.2.1 Group Replication部署單主模式
17.2.1.1 部署Group Replication實例
17.2.1.2 為一個實例配置Group Replication
17.3.1 Replication_group_member_stats
17.3.2 Replication_group_members
17.3.3 Replication_connection_status
17.3.4 Replication_applier_status
17.3.5 Group Replication Server States
17.4.3.2 Unblocking a Partition
17.9.3 Data Manipulation Statements
17.9.4 Data Definition Statements
17.5.9.2 Recovering From a Point-in-time
17.1 Group Replication後臺
最常用創建容錯系統是使用手段來冗餘組件,也就是說組件可以被刪除,但是系統還是正常運行。複製的資料庫必須面臨的一個問題,他們需要維護和管理多個實例,還有服務組合在一起創建,把一切其他傳統分散式系統組合的問題也必須解決。
最主要的問題是抱著資料庫和數據的複製在幾個服務合作下,邏輯是一致的並且是簡單的。也就是說,多個服務同意系統和數據的狀態,並且同意系統前進時的每個修改。就是服務在每個資料庫的傳輸的狀態都必須同意,所有的處理就好像在一個資料庫或者之後會覆蓋的其他資料庫到相同的狀態。
MySQL Group Replication提供了分散式複製,使用server之間的強連接,如果服務在相同的group,那麼久會自動連接上。Group可以是單主,也可以是多主的。
有一個編譯好的服務,在任意時間點,可以看group的一致性和可用性。服務可以加入,離開group,並且view會有相應的更新。有時候服務會異常離開group,那麼錯誤診斷機制會發現並且通知組並且修改view,這些都是自動的。
對於事務提交,需要大多數同意。事務提交和回滾完成是由單獨服務確定的,不是所有的服務決定。如果有一個network partition,那麼就會導致分裂,成員不能相互通信,因此系統不能處理,知道問題被解決。當然也有內置的,自動的主分裂保護的機制。
17.1.1 Replication技術
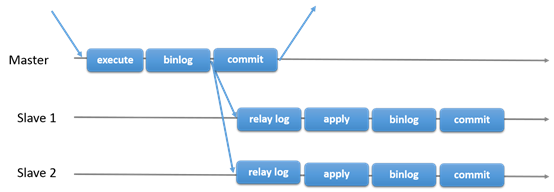
17.1.1.1 主從複製
MySQL傳統的主從複製。有一個主,多個從。主執行事務,提交然後發送到從,重新執行。是shared-nothing系統,所有的服務預設是full copy的。
17.1.1.2 Group Replication
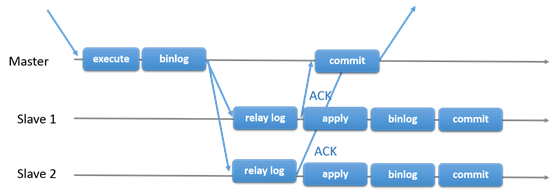
Group Replication可以用於容錯系統,是一組互相交互的服務。交互層提供了機制確保消息的原子性和消息的交互。
Group Replication實現了多主的複製。複製組由多個服務組成,每個服務都可以運行事務。讀寫的時候之後group認可之後才能提交。只讀事務因為不需要和group交互,因此提交很快。也就是說關於寫入事務,group需要決定事務是否提交,而不是原始的服務單獨確定的。當原始服務準備提交,服務會自動廣播。然後事務的全局順序被建立。這個很重要,也就是說所有的服務在相同的事務順序下,收到了相同的事務。這樣也就保證了group的數據一致性。
當然不同的服務併發的執行事務也會有衝突。這種衝突出現在檢查不同寫入集合的併發事務。這個過程叫做certification 。如果2個併發事務在不同的服務上運行,更新了相同的行,那麼就是發生衝突了。解決方法是提交順序在前面的,另外一個就回滾。
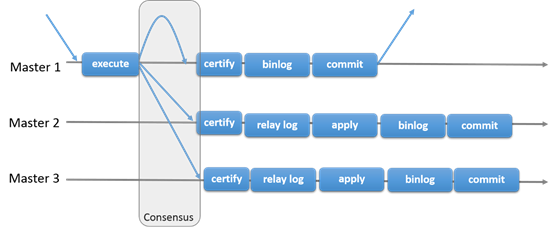 Group Replication也是一個shared-nothing系統,對整個數據的一個副本。
Group Replication也是一個shared-nothing系統,對整個數據的一個副本。
17.1.2 Group Replication使用場景
略,具體看:
https://dev.mysql.com/doc/refman/5.7/en/group-replication-use-cases.html
17.1.3 Group Replication細節
17.1.3.1 錯誤發現
有一個錯誤發現機制,用來找出報告那個服務是靜默的,然後假定為已經掛了。錯誤發現其實分散式服務用來提供服務的活動信息。之後group決定服務確實出錯,那麼剩下的group成員就會排除這個成員。
當服務靜默,錯誤發現機制就會被觸發。當服務A沒有收到來自服務B的,而且超時就會觸發。
如果服務被所有的成員隔離,並懷疑所有的node都是錯誤的。就不能被group保護,懷疑是無效的。當服務被懷疑,那麼就不能再執行任何本地事務。
17.1.3.2 Group成員
MySQL Group Replication管理到Group成員服務,這個服務是內置的插件,定義了那個服務是線上的,可以投票的。線上的服務被稱為view。因此每個group內的服務都有一個一樣的view,表示那個服務是活動的。
所有服務需要統一的不單單是事務提交,還有當前的view。因此如果所有同意一個新的服務的加入,然後Group重新配置,加入這個服務,並且出發view的修改。當服務離開group的時候也會發生,然後group重排配置,並且出發view的修改。
當一個成員自覺的離開group,會先初始化Group的重新配置。然後出發一個過程,除了一開的服務之外,其他服務都要同意,如果成員是因為故障一開的,錯誤發現機制發現問題,並且發出重新配置的提議。需要所有的服務同意,如果不能同意那麼group的配置就無法修改。也就是說管理員需要手工來修複。
17.1.3.3 錯誤容忍
Group Replication實現了Paxos分散式演算法來提供服務的分散式服務。要求大多數的服務活動以達到大多數,來做個決定。直接影響了系統可以容忍的錯誤容錯公司如下,伺服器n,容錯f:n = 2 x f + 1
也就是說,容忍一個錯誤那麼group必須要有3個成員。因為就算有一個錯了,還有2個,任然可以形成大多數來處理一些事情。如果另外一個也掛, 那麼就剩下一個,不發形成大多數(大於半數)。
|
Group Size |
Majority |
Instant Failures Tolerated |
|
1 |
1 |
0 |
|
2 |
2 |
0 |
|
3 |
2 |
1 |
|
4 |
3 |
1 |
|
5 |
3 |
2 |
|
6 |
4 |
2 |
|
7 |
4 |
3 |
17.2 Getting Start
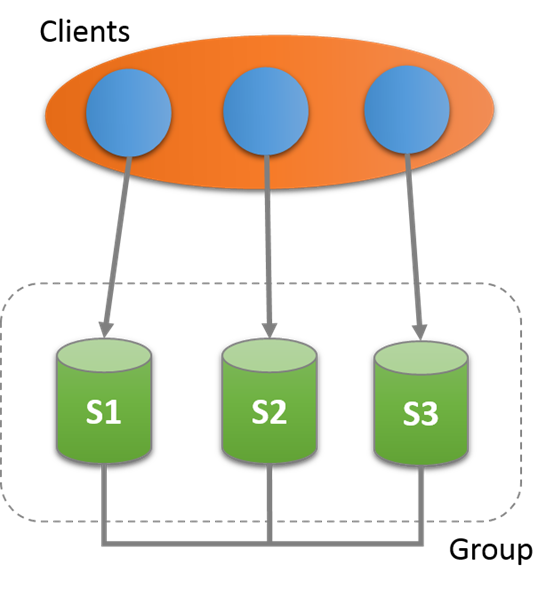
17.2.1 Group Replication部署單主模式
每個實例可以運行在單個機器上,可以在同一個機器上。
17.2.1.1 部署Group Replication實例
第一步不是三個實例。Group Replication是MySQL內部的插件,MySQL 5.7.17之後版本都開始有。
mkdir data
mysql-5.7/bin/mysqld --initialize-insecure --basedir=$PWD/mysql-5.7 --datadir=$PWD/data/s1
mysql-5.7/bin/mysqld --initialize-insecure --basedir=$PWD/mysql-5.7 --datadir=$PWD/data/s2
mysql-5.7/bin/mysqld --initialize-insecure --basedir=$PWD/mysql-5.7 --datadir=$PWD/data/s3
17.2.1.2 為一個實例配置Group Replication
配置服務的基本配置:
[mysqld]
# server configuration
datadir=<full_path_to_data>/data/s1
basedir=<full_path_to_bin>/mysql-5.7/
port=24801
socket=<full_path_to_sock_dir>/s1.sock
配置複製相關,並啟動GTID
server_id=1
gtid_mode=ON
enforce_gtid_consistency=ON
master_info_repository=TABLE
relay_log_info_repository=TABLE
binlog_checksum=NONE
log_slave_updates=ON
log_bin=binlog
binlog_format=ROW
Group Replication配置
transaction_write_set_extraction=XXHASH64
loose-group_replication_group_name="aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa"
loose-group_replication_start_on_boot=off
loose-group_replication_local_address= "127.0.0.1:24901"
loose-group_replication_group_seeds= "127.0.0.1:24901,127.0.0.1:24902,127.0.0.1:24903"
loose-group_replication_bootstrap_group= off
第一行:所有的寫入的事務的write set使用XXHASH64進行編碼。
第二行:要加入的group的名字
第三行:服務啟動後,不自動啟動
第四行:使用127.0.0.1,埠為24901,來接入group成員的連接。
第五行:當加入一個group時,需要連接的host,只需要連接一個,然後該階段會要求group重新配置,允許伺服器加入到group。當多個服務同時要求加入group,保證用的seed已經在group 中。
第六行:插件是否關聯到group,這個參數很重要,必須只有一個服務使用,不然會出現主分裂的情況,就是不同的group有相同的Group名字。第一個服務實例online之後就禁用這個選項。
17.2.1.3 用戶授權
Group Replication使用非同步複製的協議,處理分佈的恢復,來同步將要加入group的成員。分佈的恢復處理依賴於複製通道,group_replication_recovery 用來在group成員之間做傳輸。因此需要一個複製用戶和足夠的許可權,用戶成員之間的恢複復制通道。
創建一個擁有REPLICATION_SLAVE許可權的用戶,但是這個過程不能被binlog捕獲。
mysql> SET SQL_LOG_BIN=0;
Query OK, 0 rows affected (0,00 sec)
mysql> CREATE USER rpl_user@'%' IDENTIFIED BY 'rpl_pass';
Query OK, 0 rows affected (0,00 sec)
mysql> GRANT REPLICATION SLAVE ON *.* TO rpl_user@'%';
Query OK, 0 rows affected, 1 warning (0,00 sec)
mysql> FLUSH PRIVILEGES;
Query OK, 0 rows affected (0,00 sec)
mysql> SET SQL_LOG_BIN=1;
Query OK, 0 rows affected (0,00 sec)
配置好之後,使用change master to語句配置服務
mysql> CHANGE MASTER TO MASTER_USER='rpl_user', MASTER_PASSWORD='rpl_pass' \\
FOR CHANNEL 'group_replication_recovery';
Query OK, 0 rows affected, 2 warnings (0,01 sec)
分散式恢復的第一步就是把服務加入到Group中,如果賬號和許可權設置的不對那麼無法運行恢復進程,最重要的是無法加入到group。類似的,如果成員不能正確的通過host識別其他成員那麼恢復進程也會錯誤。可以通過performance_schema. replication_group_members查看host。可以使用report_host區別開來。
17.2.1.4 執行Group Replication
弄完上面的配置,並且啟動後,連接到服務,執行一下命令:
INSTALL PLUGIN group_replication SONAME 'group_replication.so';
安裝好之後可以通過show plugins查看,如果安裝成功就會在返回中。
啟動group,讓s1關聯group並且啟動Group Replication。這個關聯要單個伺服器完成,並且只能啟動一次。所以這個配置不能保存在配置文件中,如果保存了,下次啟動會自動關聯到第二個Group,並且名字是一樣的。如果開關plugin,但是參數是ON的也會有這個問題。
SET GLOBAL group_replication_bootstrap_group=ON;
START GROUP_REPLICATION;
SET GLOBAL group_replication_bootstrap_group=OFF;
一旦start完成,就可以查到成員了:
mysql> SELECT * FROM performance_schema.replication_group_members;
+---------------------------+--------------------------------------+-------------+-------------+---------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
+---------------------------+--------------------------------------+-------------+-------------+---------------+
| group_replication_applier | ce9be252-2b71-11e6-b8f4-00212844f856 | myhost | 24801 | ONLINE |
+---------------------------+--------------------------------------+-------------+-------------+---------------+
1 row in set (0,00 sec)
增加一些數據:
mysql> CREATE DATABASE test;
Query OK, 1 row affected (0,00 sec)
mysql> use test
Database changed
mysql> CREATE TABLE t1 (c1 INT PRIMARY KEY, c2 TEXT NOT NULL);
Query OK, 0 rows affected (0,00 sec)
mysql> INSERT INTO t1 VALUES (1, 'Luis');
Query OK, 1 row affected (0,01 sec)
17.2.1.5 增加一個實例到Group
這個時候已經有一個成員了s1,已經有了一些數據,現在加入其它節點到Group
增加s2 到group,設置配置文件,基本和s1的一直,修改server_id,因為文檔中是本地多實例,需要修改datadir等信息。
設置用於複製的用戶:
SET SQL_LOG_BIN=0;
CREATE USER rpl_user@'%';
GRANT REPLICATION SLAVE ON *.* TO rpl_user@'%' IDENTIFIED BY 'rpl_pass';
SET SQL_LOG_BIN=1;
CHANGE MASTER TO MASTER_USER='rpl_user', MASTER_PASSWORD='rpl_pass' \\
FOR CHANNEL 'group_replication_recovery';
然後啟動
mysql> INSTALL PLUGIN group_replication SONAME 'group_replication.so';
Query OK, 0 rows affected (0,01 sec)
這裡和s1不一樣的地方是不需要。
通過 performance_schema.replication_group_members 檢查成員是不是正常。
查看之前s1插入的數據時候已經完全同步過來。
17.3 監控Group Replication
使用performance schema 上的表來監控Group Replication,如果有performance_ schema那麼就會在上面創建來個表:
· performance_schema.replication_group_member_stats
· performance_schema.replication_group_members
· performance_schema.replication_connection_status
· performance_schema.replication_applier_status
· group_replication_recovery
· group_replication_applier
17.3.1 Replication_group_member_stats
|
Field |
Description |
|
Channel_name |
Group Replication通道名 |
|
Member_id |
成員的uuid |
|
Count_transactions_in_queue |
未經過衝突檢查的事務數量 |
|
Count_transactions_checked |
通過衝突檢查的事務數量 |
|
Count_conflicts_detected |
沒有通過衝突檢查的事務數量 |
|
Count_transactions_rows_validating |
衝突檢查資料庫的大小 |
|
Transactions_committed_all_members |
成功提交到成員的事務數量 |
|
Last_conflict_free_transaction |
最後一次衝突,被釋放的事務 |
17.3.2 Replication_group_members
|
Field |
Description |
|
Channel_name |
通道名 |
|
Member_id |
成員uuid |
|
Member_host |
成員host |
|
Member_port |
成員埠 |
|
Member_state |
成員狀態 (which can be ONLINE, ERROR, RECOVERING, OFFLINE or UNREACHABLE). |
17.3.3 Replication_connection_status
|
Field |
Description |
|
Channel_name |
通道名 |
|
Group_name |
Group名 |
|
Source_UUID |
Group的標識 |
|
Service_state |
查看服務是否是group成員{ON, OFF and CONNECTING}; |
|
Received_transaction_set |
已經被該成員接受的gtid集 |
17.3.4 Replication_applier_status
|
Field |
Description |
|
Channel_name |
通道名 |
|
Service_state |
服務狀態 |
|
Remaining_delay |
是否配置了延遲 |
|
Count_transactions_retries |
重試執行的事務個數 |
|
Received_transaction_set |
已經被接收的gtid集 |
17.3.5 Group Replication Server States
表replication_group_members在view發生變化的時候就會修改,比如group的配置動態變化。如果出現網路分離,或者服務離開group,信息就會被報告,根據不通的服務獲得的信息不通。註意如果服務離開了group,那麼就無法獲得其他服務的信息。如果發生分離,比如quorum丟失,服務就不能相互進行協同。也就是說會報告unreachable而不會一個假設狀態。
|
Field |
Description |
Group Synchronized |
|
ONLINE |
服務online可以提供全部服務 |
Yes |
|
RECOVERING |
成員正在恢復,之後會變成online黃台 |
No |
|
OFFLINE |
插件已經安裝,但是成員不屬於任何group |
No |
|
ERROR |
在recovery階段或者應用修改的時候,出現錯誤 |
No |
|
UNREACHABLE |
錯誤排查懷疑服務無法連接。 |
No |
17.4 Group Replication操作
17.4.1部署多主或者單主模式
Group Replication有2個不同的模式:
1. 單主模式
2. 多主模式
預設是單主模式的,不能的模式不能出現在一個group中,比如一個成員是單主,一個成員是多主。切換模式需要重新配置,然後重啟。不管什麼模式,Group Replication都不支持failover。這個必須由程式自己來處理,或者用其他中間件。
當不是了多主,語句是可以相容的,當在多主模式,以下情況是會被檢查語句的:
1. 如果一個事務執行在serializable隔離級別,但是提交失敗
2. 如果事務執行的表有外鍵,但是提交失敗
當然檢查可以通過group_replication_enforce_update_everywhere_checks來關閉。
17.4.1.1 單主模式
在單主模式下,只有主是可以讀寫的,其他都只能讀取。這個設置是自動的。主通常是關聯到group的,其他的成員join,自動學習主,並且設置為只讀。
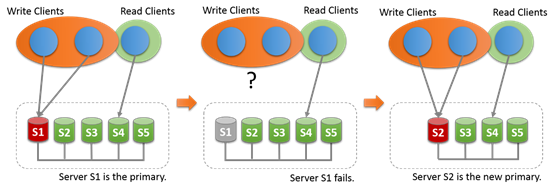
在單主模式下,多主的檢查被取消,因為系統只有一個服務是可寫的。當主成員失敗,自動主選舉機制會選取新的主。然後新竹根據成員的uuid進行排序然後選擇第一個。
當主離開Group,也會選舉新主,一旦新主被選出來之後,就會設置可讀寫,其他任然是從。
17.4.1.2 多主模式
在多主模式下,和單主不通,不需要選舉產生多主,服務沒有特定的角色。所有的服務都是可讀寫的。
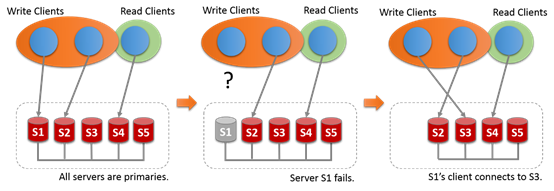
17.4.1.3 查找Primary
Primary 可以通過show status 或者select查找:
mysql> SELECT VARIABLE_VALUE FROM performance_schema.global_status WHERE VARIABLE_NAME= 'group_replication_primary_member';
+--------------------------------------+
| VARIABLE_VALUE |
+--------------------------------------+
| 69e1a3b8-8397-11e6-8e67-bf68cbc061a4 |
+--------------------------------------+
1 row in set (0,00 sec)
17.4.2 協調Recovery
當一個新的成員要加入到group,會連接到一個合適的donor並且獲取數據,成員會一直獲取直到狀態變為online。
Donor選擇
Donor選擇是隨機的在group中選一個成員。同一個成員不會被選擇多次。如果連接到donor失敗,那麼會自動或去連接新的donor,一旦超過連接重試限制就會報錯。
強制自動Donor切換
出現以下問題的時候會自動切換到一個新的donor,並嘗試連接:
1. 清理數據場景,如果被選擇的donor包含數據清理,但是是recovery需要的,那麼會產生錯誤並且,獲取一個新的donor。
2. 重覆數據,如果一個joiner已經包含了一些數據,和selected的有衝突,那麼也會報告錯誤,並且選擇一個新的donor。
3. 其他錯誤,任何recovery線程的錯誤都會觸發,連接一個新的donor。
Donor連接重試
Recovery數據的傳輸是依賴binlog和現存的MySQL複製框架,因此可能會有一些傳輸問題導致receiver或者applier有問題。這個時候會有donor切換。
重試次數
預設從donor pool裡面可以嘗試10次連接,也可以通過參數修改,一下腳本設置成了10次:
SET GLOBAL group_replication_recovery_retry_count= 10;
Sleep Routines
通過參數設置:
SET GLOBAL group_replication_recovery_reconnect_interval= 120;
設置為120秒,只有當joiner嘗試連接了所有的donor,但是沒有合適的,並且沒有剩餘的,那麼按照參數來sleep。
17.4.3 網路隔離
17.4.3.1 發現網路隔離
Replication_group_members包含了當前view裡面的所有服務的和服務的狀態。大多數情況下服務運行是正常的,所以這個表對所有服務來說是一致的。如果出現網路隔離,那麼quorum就會丟失,然後表上回顯示UNREACHABLE。
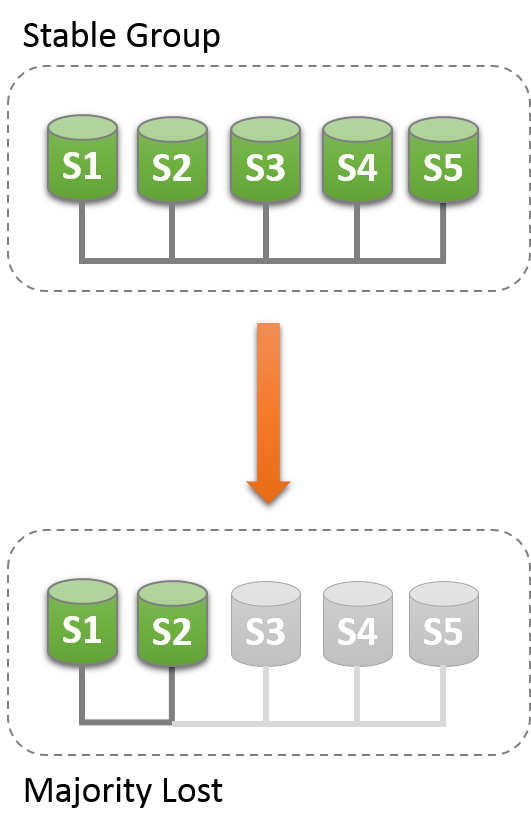
比如有個場景有5個服務,然後因為事故,其中3個丟失:
· Server s1 with member identifier 199b2df7-4aaf-11e6-bb16-28b2bd168d07
· Server s2 with member identifier 199bb88e-4aaf-11e6-babe-28b2bd168d07
· Server s3 with member identifier 1999b9fb-4aaf-11e6-bb54-28b2bd168d07
· Server s4 with member identifier 19ab72fc-4aaf-11e6-bb51-28b2bd168d07
· Server s5 with member identifier 19b33846-4aaf-11e6-ba81-28b2bd168d07
丟失之前的狀態:
mysql> SELECT * FROM performance_schema.replication_group_members;
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| group_replication_applier | 1999b9fb-4aaf-11e6-bb54-28b2bd168d07 | 127.0.0.1 | 13002 | ONLINE |
| group_replication_applier | 199b2df7-4aaf-11e6-bb16-28b2bd168d07 | 127.0.0.1 | 13001 | ONLINE |
| group_replication_applier | 199bb88e-4aaf-11e6-babe-28b2bd168d07 | 127.0.0.1 | 13000 | ONLINE |
| group_replication_applier | 19ab72fc-4aaf-11e6-bb51-28b2bd168d07 | 127.0.0.1 | 13003 | ONLINE |
| group_replication_applier | 19b33846-4aaf-11e6-ba81-28b2bd168d07 | 127.0.0.1 | 13004 | ONLINE |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
5 rows in set (0,00 sec)
然後因為事故quorum丟失:
mysql> SELECT * FROM performance_schema.replication_group_members;
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| group_replication_applier | 1999b9fb-4aaf-11e6-bb54-28b2bd168d07 | 127.0.0.1 | 13002 | UNREACHABLE |
| group_replication_applier | 199b2df7-4aaf-11e6-bb16-28b2bd168d07 | 127.0.0.1 | 13001 | ONLINE |
| group_replication_applier | 199bb88e-4aaf-11e6-babe-28b2bd168d07 | 127.0.0.1 | 13000 | ONLINE |
| group_replication_applier | 19ab72fc-4aaf-11e6-bb51-28b2bd168d07 | 127.0.0.1 | 13003 | UNREACHABLE |
| group_replication_applier | 19b33846-4aaf-11e6-ba81-28b2bd168d07 | 127.0.0.1 | 13004 | UNREACHABLE |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
5 rows in set (0,00 sec)
因為大多數已經丟失,所以Group就無法繼續運行。為了讓Group恢復運行需要重置group成員列表。或者關閉s1,s2的group replication,然後解決s3,s4,s5出現的問題,然後重啟group replication。
17.4.3.2 Unblocking a Partition
Group Replication可以強製成員配置來重置。一下場景只有S1,S2,就可以強製成員列表,通過設置變數group_replication_force_members變數。
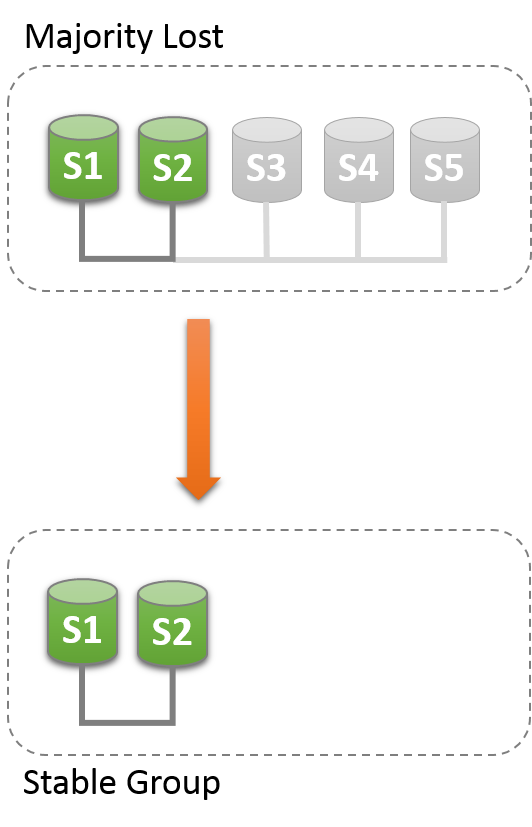
假設S1,S2存活,其他都非預期退出group,想要強製成員只有S1,S2。
首先查看S1上的成員列表:
mysql> SELECT * FROM performance_schema.replication_group_members;
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| group_replication_applier | 1999b9fb-4aaf-11e6-bb54-28b2bd168d07 | 127.0.0.1 | 13002 | UNREACHABLE |
| group_replication_applier | 199b2df7-4aaf-11e6-bb16-28b2bd168d07 | 127.0.0.1 | 13001 | ONLINE |
| group_replication_applier | 199bb88e-4aaf-11e6-babe-28b2bd168d07 | 127.0.0.1 | 13000 | ONLINE |
| group_replication_applier | 19ab72fc-4aaf-11e6-bb51-28b2bd168d07 | 127.0.0.1 | 13003 | UNREACHABLE |
| group_replication_applier | 19b33846-4aaf-11e6-ba81-28b2bd168d07 | 127.0.0.1 | 13004 | UNREACHABLE |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
5 rows in set (0,00 sec)
然後從S1,S2中獲取@@group_replication_local_address,然後設置到變數中
mysql> SELECT @@group_replication_local_address;
+-----------------------------------+
| @@group_replication_local_address |
+-----------------------------------+
| 127.0.0.1:10000 |
+-----------------------------------+
1 row in set (0,00 sec)
mysql> SELECT @@group_replication_local_address;
+-----------------------------------+
| @@group_replication_local_address |
+-----------------------------------+
| 127.0.0.1:10001 |
+-----------------------------------+
1 row in set (0,00 sec)
mysql> SET GLOBAL group_replication_force_members="127.0.0.1:10000,127.0.0.1:10001";
Query OK, 0 rows affected (7,13 sec)
檢查members
mysql> select * from performance_schema.replication_group_members;
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| group_replication_applier | b5ffe505-4ab6-11e6-b04b-28b2bd168d07 | 127.0.0.1 | 13000 | ONLINE |
| group_replication_applier | b60907e7-4ab6-11e6-afb7-28b2bd168d07 | 127.0.0.1 | 13001 | ONLINE |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
2 rows in set (0,00 sec)
當強制一個新的成員配置,要保證


