
協程 1.定義 協程,顧名思義,程式協商著運行,並非像線程那樣爭搶著運行。協程又叫微線程,一種用戶態輕量級線程。協程就是一個單線程(一個腳本運行的都是單線程) 協程擁有自己的寄存器上下文和棧。協程調度切換時,將寄存器上下文和棧保存到其他地方,在切回來的時候,恢復先前保存的寄存器上下文和棧。 協程能保 ...
協程
1.定義
協程,顧名思義,程式協商著運行,並非像線程那樣爭搶著運行。協程又叫微線程,一種用戶態輕量級線程。協程就是一個單線程(一個腳本運行的都是單線程)
協程擁有自己的寄存器上下文和棧。協程調度切換時,將寄存器上下文和棧保存到其他地方,在切回來的時候,恢復先前保存的寄存器上下文和棧。
協程能保留上一次調用時的狀態(即所有局部狀態的一個特定組合),每次過程重入時,就相當於進入上一次調用的狀態,換種說法:進入上一次離開時所處邏輯流的位置,看到這



是的,就是生成器,後面再實例更會充分的利用到生成器,但註意:生成器 != 協程
2.特性
優點:
- 無需線程上下文切換的開銷
- 無需原子操作鎖定及同步的開銷
- 方便切換控制流,簡化編程模型
- 高併發+高擴展性+低成本:一個CPU支持上萬的協程都不是問題。所以很適合用於高併發處理。
註:比如修改一個數據的整個操作過程下來只有兩個結果,要嘛已修改,要嘛未修改,中途出現任何錯誤都會回滾到操作前的狀態,這種操作模式就叫原子操作,"原子操作(atomic operation)是不需要synchronized",不會被線程調度機制打斷的操作;這種操作一旦開始,就一直運行到結束,中間不會有任何 context switch (切換到另一個線程)。原子操作可以是一個步驟,也可以是多個操作步驟,但是其順序是不可以被打亂,或者切割掉只執行部分。視作整體是原子性的核心。
缺點:
- 無法利用多核資源:協程的本質是個單線程,它不能同時將 單個CPU 的多個核用上,協程需要和進程配合才能運行在多CPU上.當然我們日常所編寫的絕大部分應用都沒有這個必要,除非是cpu密集型應用。
- 進行阻塞(Blocking)操作(如IO時)會阻塞掉整個程式
3.實例
1)用生成器實現偽協程:
在這之前,相信很多朋友已經把生成器是什麼忘了吧,這裡簡單複習一下。
創建生成器有兩個放法:
A:使用列表生成器:

B:使用yield創建生成器:

訪問生成器數據,使用next()或者__next__()方法:
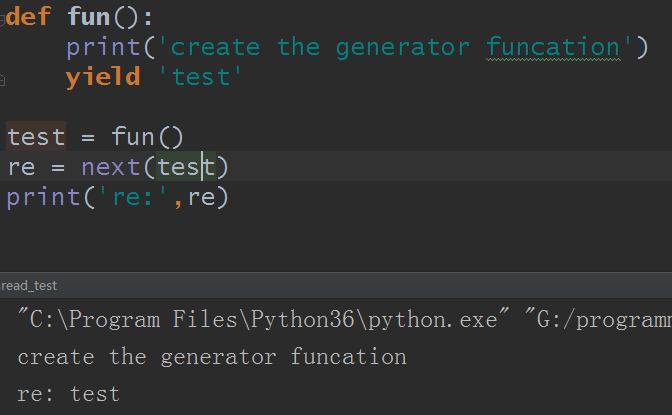
好的,既然說到這裡,就說下,yield可以暫存數據並轉發:
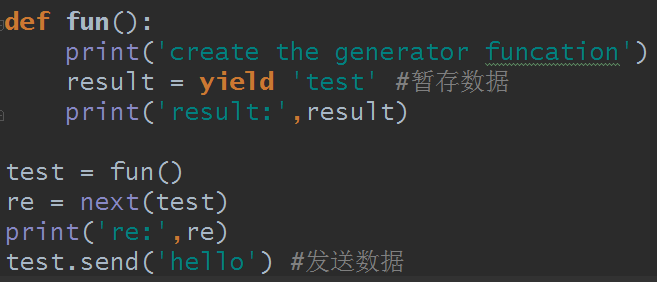
傳是傳入了,但結果卻報錯:

為什麼報錯呢?首先要說一個知識點,使用next()和send()方法都會取出一個數據,不同的是send即發送數據又取出上一數據,並且如果要發送數據必須是第二次發送,如果第一次就是用send,必須寫為send(None)才行,不然報錯。next(obj) = obj.send(None).
因為yield是暫存數據,每次next()時將會在結束時的此處阻塞住,下一次又從這裡開始,而發送完,send取數據發現已經結束了,數據已經沒了,所以修改報錯,
那麼稍作修改得:

完美!
好的,進入正題了,有了上面的現鈔,現在現賣應該沒問題了:
依然是前面的生產者消費者模型
import time
import queue
def consumer(name):
print("--->starting eating baozi...")
while True:
new_baozi = yield
print("[%s] is eating baozi %s" % (name,new_baozi))
#time.sleep(1)
def producer():
r = con.__next__()
r = con2.__next__()
n = 0
while n < 5:
n +=1
con.send(n)
con2.send(n)
print("\033[32;1m[producer]\033[0m is making baozi %s" %n )
if __name__ == '__main__':
con = consumer("c1")
con2 = consumer("c2")
p = producer()
運行結果:

首先我們知道使用yield創建了一個生成器對象,然後每次使用時利用new_baozi做一個中轉站來緩存數據。這就是實現協程效果了對吧?
前面我提了一句,yield下是偽協程,那麼什麼是真正的協程呢?
需要具備以下條件:
- 必須在只有一個單線程里實現併發
- 修改共用數據不需加鎖
- 一個協程遇到IO操作自動切換到其它協程
- 用戶程式里自己保存多個控制流的上下文棧
2)gevent協程
首先其實python提供了一個標準庫Greenlet就是用來搞協程的
#!usr/bin/env python
#-*- coding:utf-8 -*-
# author:yangva
from greenlet import greenlet
def test1():
print(1)
gr2.switch() #switch方法作為協程切換
print(2)
gr2.switch()
def test2():
print(3)
gr1.switch()
print(4)
gr1 = greenlet(test1)
gr2 = greenlet(test2)
gr1.switch()
運行結果:
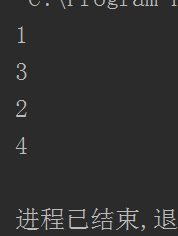
但是效果不好,無法滿足IO阻塞,所以一般情況都用第三方庫gevent來實現協程:
#!usr/bin/env python
#-*- coding:utf-8 -*-
# author:yangva
import gevent,time
def test1():
print(1,time.ctime())
gevent.sleep(1) #模擬IO阻塞,註意此時的sleep不能和time模塊下的sleep相提並論
print(2,time.ctime())
def test2():
print(3,time.ctime())
gevent.sleep(1)
print(4,time.ctime())
gevent.joinall([
gevent.spawn(test1), #激活協程對象
gevent.spawn(test2)
])
運行結果:
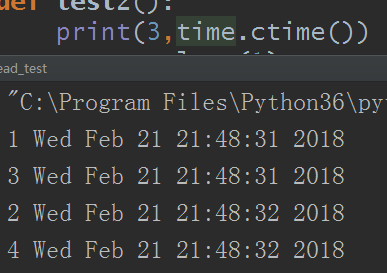
那麼如果函數帶有參數怎麼搞呢?
#!usr/bin/env python
#-*- coding:utf-8 -*-
# author:yangva
import gevent
def test(name,age):
print('name:',name)
gevent.sleep(1) #模擬IO阻塞
print('age:',age)
gevent.joinall([
gevent.spawn(test,'yang',21), #激活協程對象
gevent.spawn(test,'ling',22)
])
運行結果:

如果你對這個協程的速度覺得不理想,可以添加下麵這一段,其他不變:
這個patch_all()相當於一個檢測機制,發現IO阻塞就立即切換,不需等待什麼。這樣可以節省一些時間
好的,協程解析完畢。

