
1:正則的概念 正則表達式(regular expression)是一個描述字元規則的對象。可以用來檢查一個字元串是否含有某個子字元串,將匹配的子字元串做替換或者從某個字元串中取出符合某個條件的子串等。 為什麼要用正則:前端往往有大量的表單數據校驗工作,採用正則表達式會使得數據校驗的工作量大大減輕。 ...
1:正則的概念
正則表達式(regular expression)是一個描述字元規則的對象。可以用來檢查一個字元串是否含有某個子字元串,將匹配的子字元串做替換或者從某個字元串中取出符合某個條件的子串等。
為什麼要用正則:前端往往有大量的表單數據校驗工作,採用正則表達式會使得數據校驗的工作量大大減輕。常用效果:郵箱、手機號、身份證號等。
2:創建方式
i:表示忽略大小寫。
g:表示全局匹配,查找所有匹配並返回而非在找到第一個匹配後停止。
m:多行匹配。
第一種方式:var reg = new RegExp(“study”, “ig”); // 第二個參數為修飾符,修飾符可以多個連寫
第二種方式:var reg = /study/ig;
var str = 'Good good study day day up!';
// 第一種
var regone = /good/ig;
// 第二種
var regtwo = new RegExp('good', 'ig');
console.log(str.match(regone))
console.log(str.match(regtwo))
3:正則對象方法
test:檢索字元串中指定的值。返回true或false。
exec:用於檢索字元串中的正則表達式的匹配。返回一個數組,其中存放匹配的結果。如果未找到匹配,則返回值為null。
註:如果沒有指定g修飾符,那麼每次匹配都是從頭開始匹配,如果指定g修飾符以後,下次匹配則從上次匹配的結束位置開始匹配。
var str = 'Good good study day day up!';
// 正則表達式對象的方法
var regone = /good/ig;
var regtwo = new RegExp('good', 'ig');
console.log(regone.test(str));
console.log("——————————我是分割線——————————");
regone.lastIndex = 4;//指定索引開始匹配的位置
console.log(regone.exec(str));
console.log(regtwo.exec(str));
console.dir(regone)

4:字元串函數
search:檢索與正則表達式相匹配的值。返回字元串中第一個與正則表達式相匹配的子串的起始位置。如果沒有找到則返回-1。
match:找到一個或多個正則表達式的匹配。
replace:替換與正則表達式匹配的子串。
replace(捕獲正則表達式,$1《對捕獲表達式的值引用》)
replace方法第二個參數支持回調函數,回調函數的參毀掉表就是正則表達式匹配到的結果
split:把字元串分割為字元串數組。
var str = 'Good good study day day up!';
// 字元串的方法
var reg = /good/ig;
var result = str.match(reg);
console.log(result)
var result = str.search(reg);
console.log(result)
var result = str.replace(reg, '****');
console.log(result)
var str = 'a=b&c=d&e=f';
var reg = /[=&]/;
var result = str.split(reg);
console.log(result)

5:正則表達式構成
正則表達式是由普通字元(例如字元a到z)以及特殊字元(稱為元字元)組成的文字模式。正則表達式作為一個模板,將某個字元模式與所搜索的字元串進行匹配。
元字元---限定符:限定符可以指定正則表達式的一個給定組件必須要出現多少次才能滿足匹配。
*:匹配前面的子表達式零次或多次。
+:匹配前面的子表達式一次或多次。
?:匹配前面的子表達式零次或一次。
{n}:匹配確定n次。
{n,}:至少匹配n次。
{n, m}:最少匹配n次且最多匹配m次。
// 限定符
var str = 'google good';
var reg = /go*gle/; // 代表0到多次
console.log(str.split(reg));
var reg = /go+gle/; // 代表1到多次
console.log(str.split(reg));
var reg = /go?gle/; // 代表0到1次
console.log(str.split(reg));
var reg = /go{4,}gle/; // 代表最少4次
console.log(str.split(reg));
var reg = /go{3,5}gle/; // 代表最少3次,最多5次
console.log(str.split(reg));
var reg = /go{2}gle/; // 代表只有2次
console.log(str.split(reg));

註:在限定符後緊跟 ? 則由貪婪匹配變成非貪婪匹配。
// 貪婪匹配轉換成非貪婪匹配
var str = '<div id="box"></div><p></p>';
var regone = /<.+>/;
var regtwo = /<.+?>/;
console.log(regone.exec(str));
console.log("————————上為貪婪匹配,下為非貪婪匹配————————");
console.log(regtwo.exec(str));

元字元---字元匹配符:字元匹配符用於匹配某個或某些字元。
[xyz]:字元集合。匹配所包含的任意一個字元。
[^xyz]:負值字元集合。匹配未包含的任意字元。
[a-z]:字元範圍。匹配指定範圍內的任意字元。
[^a-z]:負值字元範圍。匹配任何不在指定範圍內的任意字元。
例如:[0-9]、[0-9a-z]、[0-9a-zA-Z]
\d:匹配一個數字字元。
\D:匹配一個非數字字元。
\w:匹配包含下劃線的任何單詞字元。等價於[a-z0-9A-Z_]
\W:匹配任何非單詞字元。等價於[^a-z0-9A-Z_]
\s:匹配任何空白字元。
\S:匹配任何非空白字元。
.:匹配除”\n”之外的任何單個字元。
// 字元匹配符
var str = 'a=b&c=d&e=f';
var reg = /[=&]/; // 字元匹配符集合
console.log(reg.exec(str))
var reg = /[^=&]/; // 否值字元匹配符集合
console.log(reg.exec(str))
var reg = /[b-e]/; // 範圍字元匹配符
console.log(reg.exec(str))
var reg = /[^b-e]/; // 否值範圍字元匹配符
console.log(reg.exec(str))
var str = '2018 we are coming! \n _%$#@';
var reg = /\d{4}/g;
console.log(reg.exec(str))
var reg = /\D{4}/g;
console.log(reg.exec(str))
var reg = /\w{4}/g;
console.log(reg.exec(str))
var reg = /\W{4}/g;
console.log(reg.exec(str))
var reg = /\s{1}/g;
console.log(reg.exec(str))
var reg = /\S{1}/g;
console.log(reg.exec(str))
var reg = /.+/g;
console.log(reg.exec(str))
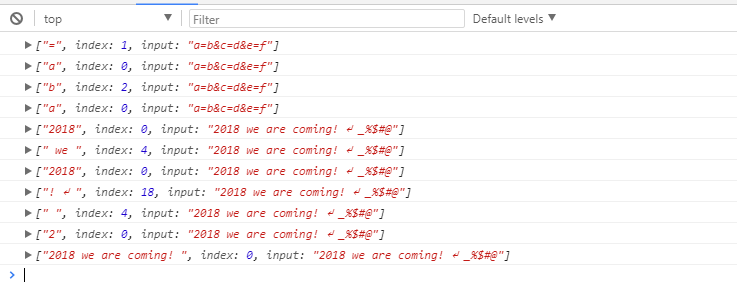
元字元---定位符:定位符可以將一個正則表達式固定在一行的開始或結束。也可以創建只在單詞內或只在單詞的開始或結尾處出現的正則表達式。
^:匹配輸入字元串的開始位置。
$:匹配輸入字元串的結束位置。
\b:匹配一個單詞邊界,也就是單詞和空格間的位置。
\B:匹配非單詞邊界。
// 定位符
// ^ 和 $ :限定字元串開始和結束的位置
var cellphone = '12345678901';
var reg = /^1\d{10}$/;
console.log(reg.test(cellphone));
// \b:限定單詞以什麼開頭和結尾,\B:限定單位不以什麼開頭和結尾
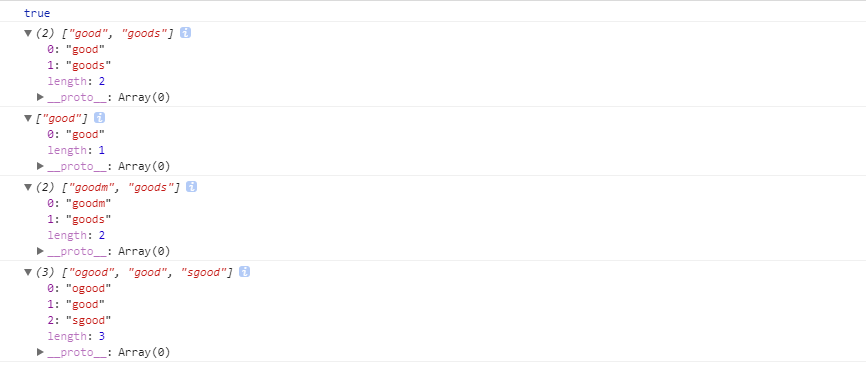
var str = 'good ogoodm goods sgoods';
var reg = /\bg\w+/g;
console.log(str.match(reg));
var reg = /\w+d\b/g;
console.log(str.match(reg));
var reg = /\Bg\w+/g;
console.log(str.match(reg));
var reg = /\w+d\B/g;
console.log(str.match(reg));
元字元---轉義符:\:用於匹配某些特殊字元。
// 轉義符
var str = 'a*********b';
var reg = /\*+/;
console.log(str.match(reg));

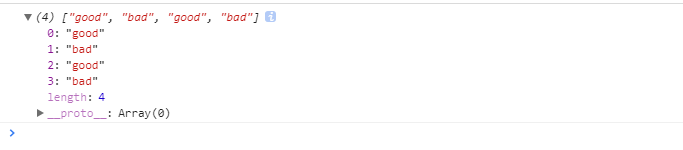
元字元---選擇匹配符:|:可以匹配多個規則。
var str = 'good bad goodbad';
var reg = /good|bad/g;
console.log(str.match(reg));
特殊用法:
():捕獲性分組,也稱為子表達式。使用\1、\2、\3…對子組的引用。當子組發生嵌套時,順序是從外到內。
var str = '<div>你好</ppp>';
var reg = /<.+?>(?:.*?)<\/.+?>/g;
console.log(str.match(reg));
console.log("————————我是分割線————————")
var reg = /<(.+?)>(.*?)<\/\1>/g;
console.log(str.match(reg));
//釋義:\1或\2...表示對錶達式的引用及對字元串匹配值方式的引用,不是表義上\數值對(.+?)表達式的引用

//()捕獲型分組表達式的應用及表達式返回值的引用 //$對()捕獲型分組返回值的引用 var str = '<div>HF胡辣湯!!!!!!</div>'; var reg = /<div>(.*)<\/div>/; console.log(reg.exec(str)); //表達式的匹配的值:<div>HF胡辣湯!!!!!!</div> //子表達式返回的值:HF胡辣湯!!!!!! console.log(str.replace(reg, '<h2>$1</h2>')); //$字元在此處的作用是對子表達式返回值的引用,經replace替換,將字元串改寫成<h2>HF胡辣湯!!!!!!</h2>

var str = '<div>HF胡辣湯!!!!!!</div>';
var reg = /<div>(.*)<\/div>/;
var result = str.replace(reg, function (name, name1) {
console.log(name, name1);
return name1;
});
//replace方法第二個參數支持回調函數,回調函數的形參表對應正則表達式匹配到的返回結果
//返回結果(表達式的返回結果及子表達式的返回結果)。

(?:pattern):非捕獲性分組。匹配pattern但不獲取匹配結果。也就是說這是一個非獲取匹配,不進行存儲供以後使用。這在使用 "或" 字元 (|) 來組合一個模式的各個部分是很有用。例如, 'industr(?:y|ies) 就是一個'industry|industries' 更簡略的表達式。
var str = '<div>HF胡辣湯!!!!!!</div>';
var reg = /<div>(?:.*)<\/div>/;//(註意表達式內的變化)
var result = str.replace(reg, function (name, name1) {
console.log(name, name1);
return name1;
});
console.log(result);

(?=pattern):正向預查,在任何匹配 pattern 的字元串開始處匹配查找字元串。這是一個非獲取匹配,也就是說,該匹配不需要獲取供以後使用。例如, 'Windows (?=95|98|NT|2000)' 能匹配 "Windows 2000" 中的 "Windows" ,但不能匹配 "Windows 3.1" 中的 "Windows"。預查不消耗字元,也就是說,在一個匹配發生後,在最後一次匹配之後立即開始下一次匹配的搜索,而不是從包含預查的字元之後開始。
(?!pattern):負向預查,在任何不匹配pattern 的字元串開始處匹配查找字元串。這是一個非獲取匹配,也就是說,該匹配不需要獲取供以後使用。例如‘Windows (?!95|98|NT|2000)’ 能匹配 “Windows 3.1” 中的 “Windows”,但不能匹配 “Windows 2000” 中的 “Windows”。預查不消耗字元,也就是說,在一個匹配發生後,在最後一次匹配之後立即開始下一次匹配的搜索,而不是從包含預查的字元之後開始。
// 預查
var str = 'windowsXP windows7 windows10 windows8 windows8.1 windows97';
var regone = /windows(?=[a-z]+)/i; //正向預查
var regtwo = /windows(?![a-z]+)/i;//反向預查
console.log(str.match(regone));
console.log(str.match(regtwo));

擴展:
手機號監測
身份證監測
日期監測
中文監測
unicode編碼中文監測:/^[\u2E80-\u9FFF]+$/
用戶名監測
正則:/^[a-z0-9_-]{3,16}$/
字元串過濾
用字元串replace方法。


