
multiprocessing模塊 由於GIL的存在,python中的多線程其實並不是真正的多線程,如果想要充分地使用多核CPU的資源,在python中大部分情況需要使用多進程。 multiprocessing包是Python中的多進程管理包。與threading.Thread類似,它可以利用mul ...
multiprocessing模塊
由於GIL的存在,python中的多線程其實並不是真正的多線程,如果想要充分地使用多核CPU的資源,在python中大部分情況需要使用多進程。
multiprocessing包是Python中的多進程管理包。與threading.Thread類似,它可以利用multiprocessing.Process對象來創建一個進程。該進程可以運行在Python程式內部編寫的函數。該Process對象與Thread對象的用法相同,也有start(), run(), join()的方法。
此外multiprocessing包中也有Lock/Event/Semaphore/Condition類 (這些對象可以像多線程那樣,通過參數傳遞給各個進程),用以同步進程,其用法與threading包中的同名類一致。所以,multiprocessing的很大一部份與threading使用同一套API,只不過換到了多進程的情境。
multiprocessing模塊的功能眾多:支持子進程、通信和共用數據、執行不同形式的同步,提供了Process、Queue、Pipe、Lock等組件,進程沒有任何共用狀態,進程修改的數據,改動僅限於該進程內。
Process類的介紹
Process(target = talk,args = (conn,addr)) #由該類實例化得到的對象,表示一個子進程中的任務(尚未啟動)
group參數未使用,值始終為None,
target表示調用對象,即子進程要執行的任務,
args表示調用對象的位置參數元組,args=(1,2,'egon',),
kwargs表示調用對象的字典,kwargs={'name':'egon','age':18},
name為子進程的名稱。
方法:p.start():啟動進程,並調用該子進程中的p.run()
p.run():進程啟動時運行的方法,正是它去調用target指定的函數,我們自定義類的類中一定要實現該方法
p.terminate():強制終止進程p,不會進行任何清理操作,如果p創建了子進程,該子進程就成了僵屍進程,使用該方法需要特別小心這種情況。如果p還保存了一個鎖那麼也將不會被釋放,進而導致死鎖
p.is_alive():如果p仍然運行,返回True
p.join([timeout]):主線程等待p終止(強調:是主線程處於等的狀態,而p是處於運行的狀態)。timeout是可選的超時時間,需要強調的是,p.join只能join住start開啟的進程,而不能join住run開啟的進程
屬性:p.daemon:預設值為False,如果設為True,代表p為後臺運行的守護進程,當p的父進程終止時,p也隨之終止,並且設定為True後,p不能創建自己的新進程,必須在p.start()之前設置
p.name:進程的名稱
p.pid:進程的pid,每個進程都會開啟一個python解釋器去完成,對應一個pid號。


from multiprocessing import Process import os import time def info(name): print("name:",name) print('parent process:', os.getppid()) print('process id:', os.getpid()) print("------------------") time.sleep(1) def foo(name): info(name) if __name__ == '__main__': info('main process line') p1 = Process(target=info, args=('alvin',)) p2 = Process(target=foo, args=('egon',)) p1.start() p2.start() p1.join() p2.join() print("ending") 運行結果: name: main process line parent process: 7904#pycharm的進程pid process id: 11424#這個是python解釋器的pid ------------------ name: alvin parent process: 11424 process id: 9628 ------------------ name: egon parent process: 11424 process id: 9276 ------------------ endingpid
p.exitcode:進程在運行時為None、如果為–N,表示被信號N結束。
p.authkey:進程的身份驗證鍵,預設是由os.urandom()隨機生成的32字元的字元串。這個鍵的用途是為涉及網路連接的底層進程間通信提供安全性,這類連接只有在具有相同的身份驗證鍵時才能成功。
使用方式分為直接調用和繼承類方式調用:
from multiprocessing import Process import time,random import os def piao(name): print(os.getppid(),os.getpid()) print('%s is piaoing' %name) time.sleep(random.randint(1,3)) print('%s is piao end' %name) if __name__ == '__main__': p1=Process(target=piao,kwargs={'name':'alex',}) p2=Process(target=piao,args=('wupeiqi',)) p3=Process(target=piao,kwargs={'name':'yuanhao',}) p1.start() p2.start() p3.start() print('主進程',os.getpid()) #os.getppid(),os.getpid() #父進程id,當前進程id開啟進程方式一
from multiprocessing import Process import time,random import os class Piao(Process): def __init__(self,name): super().__init__() self.name=name def run(self): print(os.getppid(),os.getpid()) print('%s is piaoing' %self.name) # time.sleep(random.randint(1,3)) print('%s is piao end' %self.name) if __name__ == '__main__': p1=Piao('alex') p2=Piao('wupeiqi') p3=Piao('yuanhao') p1.start() p2.start() p3.start() print('主進程',os.getpid(),os.getppid())開啟進程方式二
協程函數
協程擁有自己的寄存器上下文和棧。協程調度切換時,將寄存器上下文和棧保存到其他地方,在切回來的時候,恢復先前保存的寄存器上下文和棧。因此:
協程能保留上一次調用時的狀態(即所有局部狀態的一個特定組合),每次過程重入時,就相當於進入上一次調用的狀態,換種說法:進入上一次離開時所處邏輯流的位置。
import time """ 傳統的生產者-消費者模型是一個線程寫消息,一個線程取消息,通過鎖機制控制隊列和等待,但一不小心就可能死鎖。 如果改用協程,生產者生產消息後,直接通過yield跳轉到消費者開始執行,待消費者執行完畢後,切換回生產者繼續生產,效率極高。 """ # 註意到consumer函數是一個generator(生成器): # 任何包含yield關鍵字的函數都會自動成為生成器(generator)對象 def consumer(): r = '' while True: # 3、consumer通過yield拿到消息,處理,又通過yield把結果傳回; # yield指令具有return關鍵字的作用。然後函數的堆棧會自動凍結(freeze)在這一行。 # 當函數調用者的下一次利用next()或generator.send()或for-in來再次調用該函數時, # 就會從yield代碼的下一行開始,繼續執行,再返回下一次迭代結果。通過這種方式,迭代器可以實現無限序列和惰性求值。 n = yield r if not n: return print('[CONSUMER] ←← Consuming %s...' % n) time.sleep(1) r = '200 OK' def produce(c): # 1、首先調用c.next()啟動生成器 next(c) n = 0 while n < 5: n = n + 1 print('[PRODUCER] →→ Producing %s...' % n) # 2、然後,一旦生產了東西,通過c.send(n)切換到consumer執行; cr = c.send(n) # 4、produce拿到consumer處理的結果,繼續生產下一條消息; print('[PRODUCER] Consumer return: %s' % cr) # 5、produce決定不生產了,通過c.close()關閉consumer,整個過程結束。 c.close() if __name__=='__main__': # 6、整個流程無鎖,由一個線程執行,produce和consumer協作完成任務,所以稱為“協程”,而非線程的搶占式多任務。 c = consumer() produce(c) ''' result: [PRODUCER] →→ Producing 1... [CONSUMER] ←← Consuming 1... [PRODUCER] Consumer return: 200 OK [PRODUCER] →→ Producing 2... [CONSUMER] ←← Consuming 2... [PRODUCER] Consumer return: 200 OK [PRODUCER] →→ Producing 3... [CONSUMER] ←← Consuming 3... [PRODUCER] Consumer return: 200 OK [PRODUCER] →→ Producing 4... [CONSUMER] ←← Consuming 4... [PRODUCER] Consumer return: 200 OK [PRODUCER] →→ Producing 5... [CONSUMER] ←← Consuming 5... [PRODUCER] Consumer return: 200 OK '''協程函數
from greenlet import greenlet def test1(): print (12) gr2.switch() print (34) gr2.switch() def test2(): print (56) gr1.switch() print (78) gr1 = greenlet(test1) gr2 = greenlet(test2) gr1.switch()greenlet
gevent模塊實現協程
Python通過yield提供了對協程的基本支持,但是不完全。而第三方的gevent為Python提供了比較完善的協程支持。
gevent是第三方庫,通過greenlet實現協程,其基本思想是:
當一個greenlet遇到IO操作時,比如訪問網路,就自動切換到其他的greenlet,等到IO操作完成,再在適當的時候切換回來繼續執行。由於IO操作非常耗時,經常使程式處於等待狀態,有了gevent為我們自動切換協程,就保證總有greenlet在運行,而不是等待IO。
由於切換是在IO操作時自動完成,所以gevent需要修改Python自帶的一些標準庫,這一過程在啟動時通過monkey patch完成:
import gevent import time def foo(): print("running in foo") gevent.sleep(2) print("switch to foo again") def bar(): print("switch to bar") gevent.sleep(5) print("switch to bar again") start=time.time() gevent.joinall( [gevent.spawn(foo), gevent.spawn(bar)] ) print(time.time()-start)gevent示例
實際代碼里,我們不會用gevent.sleep()去切換協程,而是在執行到IO操作時,gevent自動切換,代碼如下:
from gevent import monkey monkey.patch_all() import gevent from urllib import request import time def f(url): print('GET: %s' % url) resp = request.urlopen(url) data = resp.read() print('%d bytes received from %s.' % (len(data), url)) start=time.time() gevent.joinall([ gevent.spawn(f, 'https://itk.org/'), gevent.spawn(f, 'https://www.github.com/'), gevent.spawn(f, 'https://zhihu.com/'), ]) # f('https://itk.org/')這是分別爬,串列的操作 # f('https://www.github.com/') # f('https://zhihu.com/') print(time.time()-start)協程在爬網頁的I/O
I/O模型
一共有五種類型的I/O模型:1.阻塞I/O:全程阻塞,2.非阻塞I/O:發送多次系統調用,3.IO多路復用(監聽多個連接)4.非同步IO5.驅動信號
對於一個network IO (這裡我們以read舉例),它會涉及到兩個系統對象,一個是調用這個IO的process (or thread),另一個就是系統內核(kernel)。當一個read操作發生時,它會經歷兩個階段:
- 等待數據準備 (Waiting for the data to be ready)
- 將數據從內核拷貝到進程中 (Copying the data from the kernel to the process)
1.阻塞I/O
在linux中,預設情況下所有的socket都是blocking,一個典型的讀操作流程大概是這樣:
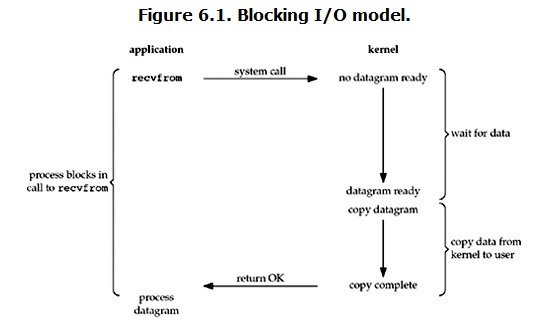
這兩個階段都是阻塞的,在進行的時候不可以做其他的任務,所以是全程阻塞。
non-blocking IO(非阻塞IO)
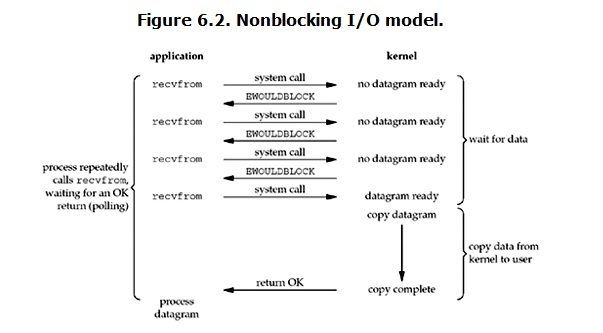
import socket import time sock=socket.socket() sock.bind(("127.0.0.1",8800)) sock.listen(5) sock.setblocking(False)#設置為非阻塞 while 1: try: conn,addr=sock.accept() # 阻塞等待鏈接 except Exception as e: print(e) time.sleep(3)非阻塞I/Oserver
import time import socket sk = socket.socket(socket.AF_INET,socket.SOCK_STREAM) while True: sk.connect(('127.0.0.1',6667)) print("hello") sk.sendall(bytes("hello","utf8")) time.sleep(2) breakclient
copy data的時候是阻塞的,等待數據時在監聽,數據不來就做其他的事,數據來了就複製數據。
優點:能夠在等待任務完成的時間里乾其他活了(包括提交其他任務,也就是 “後臺” 可以有多個任務在同時執行)。
缺點:任務完成的響應延遲增大了,因為每過一段時間才去輪詢一次read操作,而任務可能在兩次輪詢之間的任意時間完成。這會導致整體數據吞吐量的降低。並且數據也不是實時的,在數據沒來時進行某個操作,操作期間數據來了,但是他不能立刻去copy data。
IO multiplexing(IO多路復用)
IO multiplexing就是select,epoll實現的。有些地方也稱這種IO方式為event driven IO。select/epoll的好處就在於單個process就可以同時處理多個網路連接的IO。它的基本原理就是select/epoll這個function會不斷的輪詢所負責的所有socket,當某個socket有數據到達了,就通知用戶進程。它的流程如圖:
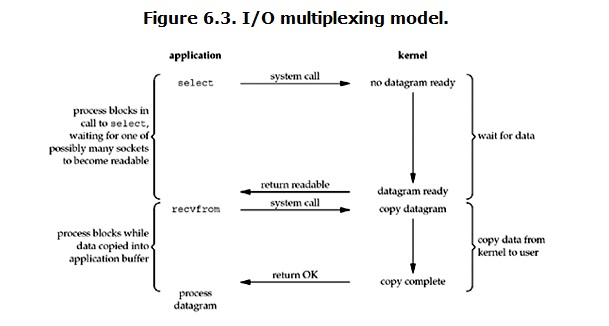
當用戶進程調用了select,那麼整個進程會被block,而同時,kernel會“監視”所有select負責的socket,當任何一個socket中的數據準備好了,select就會返回。這個時候用戶進程再調用read操作,將數據從kernel拷貝到用戶進程。
import socket import time import select sock=socket.socket() sock.bind(("127.0.0.1",8800)) sock.listen(5) sock.setblocking(False) inputs=[sock,] print("sock",sock) while 1: r,w,e=select.select(inputs,[],[]) # 監聽有變化的套接字 inputs=[sock,conn1,conn2,conn3..] print("r",r)#select就卡在這一有鏈接來就開始操作,沒鏈接就block阻塞 print("r",w) print("r",e) for obj in r: # 第一次 [sock,] 第二次 #[conn1,] if obj==sock:#sock是用戶來連接我我有變化,將新的鏈接加入 print('change') conn,addr=obj.accept() inputs.append(conn) # inputs=[sock,conn] else:#客戶端傳來消息,那麼我的conn發生變化,進行數據交互 data=obj.recv(1024) print(data.decode("utf8")) send_data=input(">>>") obj.send(send_data.encode("utf8"))I/O多路復用併發server
import socket sock=socket.socket() sock.connect(("127.0.0.1",8800)) while 1: data=input("input>>>") sock.send(data.encode("utf8")) rece_data=sock.recv(1024) print(rece_data.decode("utf8")) sock.close()client
select僅僅使用I/O多路復用就完成了併發。一開始只監聽sock,一有客戶端來連接將conn加入監聽,然後傳數據過來就只監聽conn傳數據,簡單來說select只監聽有變化的套接字,沒有變化的套接字傳輸還是按照之前學的套接字之間的數據傳輸。
結論: select的優勢在於可以處理多個連接,不適用於單個連接。
Asynchronous I/O(非同步IO)
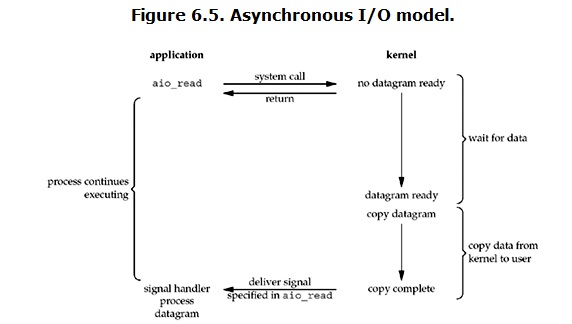
全程無阻塞,非同步就是用戶進程發起read操作之後,立刻就可以開始去做其它的事。而另一方面,從kernel的角度,當它受到一個asynchronous read之後,首先它會立刻返回,所以不會對用戶進程產生任何block。然後,kernel會等待數據準備完成,然後將數據拷貝到用戶記憶體,當這一切都完成之後,kernel會給用戶進程發送一個signal,告訴它read操作完成了。
到目前為止,已經將四個IO Model都介紹完了。現在回過頭來回答最初的那幾個問題:blocking和non-blocking的區別在哪,synchronous IO和asynchronous IO的區別在哪。
調用blocking IO會一直block住對應的進程直到操作完成,而non-blocking IO在kernel還準備數據的情況下會立刻返回。
各個IO Model的比較如圖所示:

non-blocking IO中,雖然進程大部分時間都不會被block,但是它仍然要求進程去主動的check,並且當數據準備完成以後,也需要進程主動的再次調用recvfrom來將數據拷貝到用戶記憶體。而asynchronous IO則完全不同。它就像是用戶進程將整個IO操作交給了他人(kernel)完成,然後他人做完後發信號通知。在此期間,用戶進程不需要去檢查IO操作的狀態,也不需要主動的去拷貝數據。
selectors模塊(基於select機制實現的IO多路復用)
這個模塊已經封裝了select,poll,和epoll實現I/O多路復用。
windows下只有select,linux上還有poll和epoll。
select缺點每次調用都要將所有文件描述符copy到內核空間導致效率低,每次都要遍歷所有的fd,是否有數據訪問。最大連接數1024,poll只是沒有連接數限制。
epoll:第一個函數創建epoll句柄,只有第一次要將所有文件描述符copy到內核空間,第二個函數回調函數,某一個函數某一個動作成功完成後會觸發的函數,為所有fd綁定回調函數,一旦有數據訪問觸發此回調函數,回調函數將fd放到鏈表中。第三個函數判斷鏈表是否為空。
import selectors # 基於select模塊實現的IO多路復用,建議大家使用 import socket sock=socket.socket() sock.bind(("127.0.0.1",8800)) sock.listen(5) sock.setblocking(False) sel=selectors.DefaultSelector() #根據具體平臺選擇最佳IO多路機制,比如在linux,選擇epoll def read(conn,mask): try: data=conn.recv(1024) print(data.decode("UTF8")) data2=input(">>>") conn.send(data2.encode("utf8")) except Exception: sel.unregister(conn) def accept(sock,mask): conn, addr = sock.accept() print("conn",conn) sel.register(conn,selectors.EVENT_READ,read) sel.register(sock,selectors.EVENT_READ,accept) # selectors對象註冊事件,監聽誰就要註冊誰,第二個預設,第三個監聽對象有變化運行這個函數 while 1: print("wating...") events=sel.select() # 監聽 [(key1,mask1),(key2,mask2)]第一次只監聽sock有鏈接過來才會繼續 for key,mask in events: # print(key.fileobj) # conn # print(key.data) # read func=key.data#accept函數 obj=key.fileobj#sock func(obj,mask) # 1 accept(sock,mask) # 2 read(conn,mask)selectors模塊server
很明顯封裝好的模塊省去了select的底層操作,用起來簡便很多。
隊列
多線程多進程才有隊列的概念。隊列是數據類型。
import queue #q=queue.Queue(3) # 預設是 先進先出(FIFO)管道容納最大值 # q.put(111)#put塞值 # q.put("hello") # q.put(222) # # q.put(223,False) # # print(q.get())#get取值取不到值就是block # # print(q.get()) # # print(q.get()) # # # q.get(False)#取不到還把block轉成false就會報錯了。 # queue 優點: 線程安全的queue
q=Queue.Queue類即是一個隊列的同步實現。隊列長度可為無限或者有限。可通過Queue的構造函數的可選參數 maxsize來設定隊列長度。如果maxsize小於1就表示隊列長度無限。
q.put(10) 調用隊列對象的put()方法在隊尾插入一個項目。put()有兩個參數,第一個item為必需的,為插入項目值; 第二個block為可選參數,預設為 1。如果隊列當前為空且block為1,put()方法就使調用線程暫停,直到空出一個數據單元。如果block為0, put方法將引發Full異常。
將一個值從隊列中取出 q.get() 調用隊列對象的get()方法從隊頭刪除並返回一個項目。可選參數為block,預設為True。如果隊列為空且 block為True,get()就使調用線程暫停,直至有項目可用。如果隊列為空且block為False,隊列將引發Empty異常。
# join和task_done # q=queue.Queue(5) # q.put(111) # q.put(222) # q.put(22222) # # # while not q.empty(): # a=q.get() # print(a) #q.task_done()#任務完成了告訴一下join # b=q.get() # print(b) # q.task_done() # q.join()只有所有的都任務都結束才不block否則都卡住 # # print("ending")join,task_done
join() 阻塞進程,直到所有任務完成,需要配合另一個方法task_done。
task_done() 表示某個任務完成。每一條get語句後需要一條task_done。
其他常用方法
此包中的常用方法(q = Queue.Queue()):
q.qsize() 返回隊列的大小
q.empty() 如果隊列為空,返回True,反之False
q.full() 如果隊列滿了,返回True,反之False
q.full 與 maxsize 大小對應
q.get([block[, timeout]]) 獲取隊列,timeout等待時間
q.get_nowait() 相當q.get(False)非阻塞
q.put(item) 寫入隊列,timeout等待時間
q.put_nowait(item) 相當
q.put(item, False)
q.task_done() 在完成一項工作之後,
q.task_done() 函數向任務已經完成的隊列發送一個信號
q.join() 實際上意味著等到隊列為空,再執行別的操作。
其他模式
Python Queue模塊有三種隊列及構造函數:
1、Python Queue模塊的FIFO隊列先進先出。 class queue.Queue(maxsize)
2、LIFO類似於堆,即先進後出。 class queue.LifoQueue(maxsize)
3、還有一種是優先順序隊列級別越低越先出來。 class queue.PriorityQueue(maxsize)
# 先進後出模式 # q=queue.LifoQueue() # Lifo last in first out # # # q.put(111) # q.put(222) # q.put(333) # # print(q.get())先進後出模式
# 優先順序 # q=queue.PriorityQueue() # # q.put([4,"hello4"]) # q.put([1,"hello"]) # q.put([2,"hello2"]) # # print(q.get()) # print(q.get())優先順序
生產者消費者模型
是一種設計模式。我們來模擬這個過程。
#生產者消費者模型 import time,random import queue,threading q = queue.Queue() def Producer(name): count = 0 while count <10:#生產數據 print("making........") time.sleep(2)#生產時間 q.put(count) print('Producer %s has produced %s baozi..' %(name, count)) count +=1 #q.task_done() #q.join() print("ok......") def Consumer(name):#消費者 count = 0 while count <10: time.sleep(1) if not q.empty(): data = q.get() #q.task_done() #q.join() print(data) print('\033[32;1mConsumer %s has eat %s baozi...\033[0m' %(name, data)) else: print("-----no baozi anymore----") count +=1 p1 = threading.Thread(target=Producer, args=('A',)) c1 = threading.Thread(target=Consumer, args=('B',))生產者消費者模型


