
AI(Artificial Intelligence)正在不斷的改變著各個行業的形態和人們的生活方式,圖像識別、語音識別、自然語言理解等 AI 技術正在自動駕駛、智能機器人、人臉識別、智能助理等領域中發揮著越來越重要的作用。 那麼當手繪視頻遇到 AI,有 AI 的手繪視頻領域,有 AI 的 UWP ...
AI(Artificial Intelligence)正在不斷的改變著各個行業的形態和人們的生活方式,圖像識別、語音識別、自然語言理解等 AI 技術正在自動駕駛、智能機器人、人臉識別、智能助理等領域中發揮著越來越重要的作用。
那麼當手繪視頻遇到 AI,有 AI 的手繪視頻領域,有 AI 的 UWP 手繪視頻創作工具,會發生些什麼呢?我們從12月23日的一次發佈會開始講起吧:


在本次發佈會上,來畫視頻發佈了正式上線的 iOS Android 手繪視頻 App 和一系列新功能,二更、同道大叔、Prezi 創始人等也帶來了短視頻行業的精彩分享,而在 AI 方面,更是發佈了兩大核心功能:智能配音和智能繪畫。
眾所周知,在視頻中,圖像和聲音是最重要的兩個因素,而對應到手繪視頻中,則是配音和手繪素材:
1. 配音
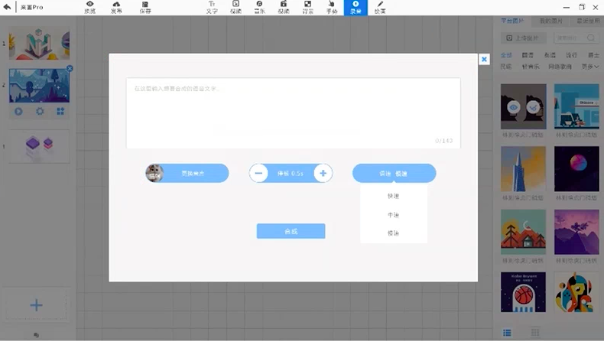
首先來說配音,在配音方面,來畫與科大訊飛進行了深度合作。科大訊飛是國內外語音識別和語音生成領域領先的人工智慧公司,而本次合作也是科大訊飛在短視頻領域的首次嘗試,雙方都對本次合作寄予了很高的期待。過往大家想製作一個短視頻時,配音需要專業配音人員完成。因為我們很多人的聲音或者對語速、語音的控制完成不了專業的要求。但依靠來畫和科大訊飛完成的智能配音功能,如下圖的操作方式,用戶只需要輸入簡單的文字以及你想使用誰的聲音。比如葛優、林志玲或者其他人的聲音,可以設置基本語速,還可以做相應停頓,就可以一鍵生成視頻中需要的配音,把它結合到手繪視頻中。
由於手繪視頻不像拍攝視頻那樣對配音的音畫同步要求那麼嚴格,我們在實現時更多的是針對手繪視頻的每個分鏡頭進行配音生成,讓每個分鏡頭的配音是和當前畫面同步的。針對每個分鏡頭,可以設置不同的語音來源,不同的語速,配合轉場動畫設置不同的停頓時間。
在技術實現上,藉助科大訊飛的 tts 技術,獲得每個分組的 mp3 語音文件,在手繪視頻預覽和生成時,把多個 mp3 文件合成到視頻文件的音軌中,設置不同的音量和語音開始時間、語音長度等信息。為保證語音生成的成功率(時長和同步方面),在輸入文字後,可以根據文字數量,以及設置的語速和停頓時間,來預估語音的時長,減少反覆轉換嘗試。
2. 手繪素材
在中國,有數億的手繪愛好者,大家渴望用手繪視頻的方式來表達自己的感受。但是苦於繪畫基礎的差異,很多人沒辦法很順利的完成手繪視頻的創作。 為此,目前來畫視頻平臺積累了大量的手繪素材,擁有豐富的標簽和精準的分類,讓用戶可以隨心的選擇。 儘管如此,來畫還在不斷探索更好的技術方式來滿足用戶對手繪素材的需求,降低創作門檻。而這種技術方式就是來畫的 AI。 來畫 AI 由三部分組成:手繪路徑的智能識別、智能優化和智能生成。 這是一個不斷遞進的過程,當用戶繪製一段路徑時,來畫 AI 演算法可以識別和理解路徑,推薦出最符合用戶想法的分類素材供選擇,選擇後還可以做智能填色等後續處理。比如用戶在畫類似圓形的路徑,AI 可以識別為圓,球形,水果等;而在用戶畫了兩個圓形,再去畫一個梯形時,AI 會認為你想畫一輛汽車。這就是我們目前研發完成的智能識別功能,它可以極大降低用戶創作素材的時間和難度。 而更進一步,當用戶繪製一段路徑,比如曲線時,AI 演算法識別和理解路徑,並對曲線中有偏差的部分路徑做出局部糾正和優化,這樣可以在降低創作時間難度的基礎上,極大的保留用戶的手繪內容和風格。 最終,我們要實現的是 AI 自動繪畫,你只需要告訴 AI 你想畫的內容,AI 就可以依照對該用戶繪製風格的理解和評定,自動完成整副畫作的繪製,包括整體畫風、路徑、顏色填充等。這樣的來畫AI,能夠極大的降低用戶創作素材的時間和難度,讓所有沒有繪畫基礎的人,也可以快速的完成高質量的屬於自己的手繪視頻創作,這才是來畫 AI 要實現的目標。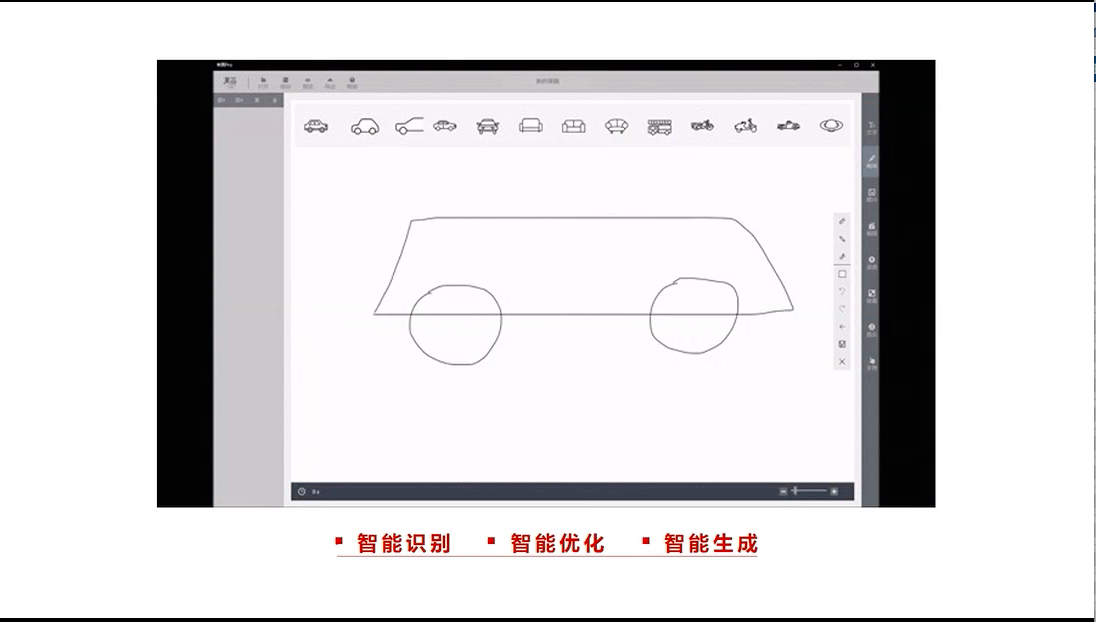
在技術實現方面,智能識別是圖像識別的深度學習,具體說是手繪草稿的識別範疇;在演算法模型的訓練方面,我們對接近 400 個分類的 4000w 個 SVG 數據進行了數據清洗和標註、訓練,目前演算法對於常見圖形的識別效果很好,隨著這一功能的上線,後面也會加強更多分類的數據採集和訓練工作;而智能優化和智能生成,除了對於草稿的圖像識別,還有對於繪製圖形的路徑理解和目標圖形的路徑理解,這也是後面突破的重點方向。
結合了配音功能和手繪素材智能識別的 UWP 來畫視頻將會在接下來發佈,歡迎大家下載使用,多提寶貴意見。
對這兩個方面感興趣的朋友,歡迎和我交流,謝謝!


