
參考 http://hbase.apache.org/book.html#_architecture Architecture 65. Overview 65.1. NoSQL? HBase是一種"NoSQL"資料庫。“NoSQL”一般指的是非關係型資料庫,我們知道,關係型資料庫支持SQL,也就是說 ...
參考 http://hbase.apache.org/book.html#_architecture
Architecture
65. Overview
65.1. NoSQL?
HBase是一種"NoSQL"資料庫。“NoSQL”一般指的是非關係型資料庫,我們知道,關係型資料庫支持SQL,也就是說HBase不支持SQL。非關係型資料庫有許多種,BerkeleyDB是一種本地非關係型資料庫,然而,HBase是分散式資料庫。從技術上來講,HBase更像是“Data Store”,而不是“Data Base”,因為它缺少許多關係型資料庫的特性,比如:列類型、輔助索引、觸發器、查詢語言等等。(PS:意思是,從技術的角度講,HBase更像一個數據存儲,而不像資料庫)
HBase集群擴展通過增加RegionServer來實現。如果一個集群從10擴展到20個RegionServer,那麼,不僅僅是存儲容量增加一倍,連處理能力也會增加一倍。對於關係型資料庫而言,也可以用scale做到這樣,但是需要指出的是,這需要特別的硬體和存儲設備。HBase特性如下:
- 強一致性讀寫:HBase不是一個“最終一致性”的數據存儲。這使得它更適合高速度的聚集任務。
- 自動分區:HBase的表通過region被分佈在集群中,而region是自動拆分並重新分佈數據行的。
- 自動RegionServer容災
- Hadoop/HDFS集成:HBase支持HDFS作為它的分散式文件系統
- MapReduce:HBase支持通過MapReduce基於HBase作為數據源的大量的並行處理
- Java Client API:HBase支持通過Java API編程的方式來訪問
- Thrift/REST API:HBase也支持Thrift和REST這樣的非Java的客戶端
- Block Cache and Bloom Filters
- Operational Management:HBase提供web界面
65.2. When Should I Use HBase?
並不是所有的問題都適合用HBase
第一、確保你有足夠的數據。如果你有數以億計的數據行,那麼HBase是一個不錯的選擇。如果你只有數千或者百萬的數據,那麼使用傳統的關係型資料庫可能更好,因為事實上你的這些數據可能只需要一個或者兩個節點就能處理得完,這樣的話集群中的其它的節點就處於空閑狀態。
第二、確保你不需要用到關係型資料庫的特性(比如:固定類型的列、輔助索引、事務、查詢語言等等)。基於關係型資料庫構建的應用不能通過簡單的改變JDBC驅動來傳輸到HBase中。從RDBMS到HBase是完全相反的兩套設計。
第三、確保你有足夠的硬體。因為當DataNode數量小於5的時候HDFS將不能正常工作了。
65.3. What Is The Difference Between HBase and Hadoop/HDFS?
HDFS是一個分散式的文件系統,適合存儲大文件,但它不能提供快速的個性化的在文件中查找。HBase是構建於HDFS基礎之上的,並且它支持對大表的中的記錄進行快速查找和更新。HBase內部將數據存放在HDFS中被索引的“StoreFiles”上以供快速查找。
69. Master
HMaster是Master Server的一個實現。Master Server負責監視集群中所有的RegionServer實例,並且它也是所有元數據改變的一個對外介面。在分散式集群中,典型的Master運行在NameNode那台機器上。
69.3. Interface
HMasterInterface介面是操作元數據的主要介面,提供以下操作:
- Table (createTable, modifyTable, removeTable, enable, disable)
- ColumnFamily (addColumn, modifyColumn, removeColumn)
- Region (move, assign, unassign)
70. RegionServer
HRegionServer是RegionServer的實現,它負責服務並管理regions。在分散式集群中,一個RegionServer通常運行在一個DataNode上。
70.1. Interface
HRegionRegionInterface既包含數據的操作也包含region維護的操作
- Data (get, put, delete, next, etc.)
- Region (splitRegion, compactRegion, etc.)
70.5. RegionServer Splitting Implementation
region server處理寫請求,它們被累積在記憶體中一個叫memstore的地方。一旦memstore文件滿了,內容將被寫到磁碟上作為store file。這個事件叫做memstore flush。隨著store file的不斷累積,RegionServer將合併它們成大文件,以減少store file的數量。在每次刷新或者合併以後,region中數據的數量會發生改變。RegionServer根據切分策略來查看是否region太大了或者應該被切分。
邏輯上,region切分的操作很簡單。找一個合適的位置,將region中的數據切分成兩個新的region。然而,這個處理的過程並不簡單。當切分發生的時候,數據並不是立刻被重寫到這個心創建的女兒region上。
71. Regions

73. HDFS

Data Model
在HBase中,數據被存儲在表中,有行和列。這些術語和關係型數據有一些重疊,當然這不是一個很好的類比,但是它對我們思考HBase的表示一個多維的map很有幫助。
Table
由多行組成
Row
HBase中的行由一個row key和一個或多個列組成。Rows在存儲的時候按照row key的字典序存儲。正因為如此,row key的設計就顯得非常重要。基於這一點,相關連的行相互之間存在附近。通常,row key是一個網站的功能變數名稱。如果你的row key是功能變數名稱,你應該以倒置的方式存儲它們(比如:org.apache.www,org.apache.mail,org.apache.jira等等)。這樣的話,所有的apache功能變數名稱在表中是相近的位置,而不是被子功能變數名稱的第一部分分開。
Column
HBase中的列由一個列簇和一個列修飾符組成,它們之間用冒號分隔(:)
Column Family
列簇由一系列的列和它們的值組成,這是基於性能考慮的。每一個列簇都有一系列的存儲屬性,比如:是否它們的值應該被緩存到記憶體中,它們的數據怎樣被壓縮,它們的row key怎樣被編碼,等等。表中的每一行都有相同的列簇,即使一個給定的行在給定的列簇上沒有存儲任何數據。
Column Qualifier
一個列修飾符被添加到列簇中為了給指定的數據片段提供索引。假設,給定的列簇是content,那麼,一個列修飾符可能是content:html,其它的還有可能是content:pdf。雖然,列簇在表創建的時候就固定了,但是列修飾符是不確定的,而且不同的行可能有不通的列修飾符。
Cell

Timestamp
一個timestamp被寫在每個value的旁邊,它是一個value的版本修飾符。預設的,timestamp代表數據被RegionServer寫入的時間,你也可以在寫數據的時候指定一個不同的timestamp值
20. Conceptual View

在這個例子中,有一個表叫“webtable”,它包含兩行數據(com.cnn.www和com.example.www)和三個列簇(contents,anchor,people)。對於第一行(com.cnn.www),anchor包含兩列(anchor:cssnsi.com,anchor:my.look.ca),contents包含一列(contents:html)。row key為“com.cnn.www”的行有5個版本,而row key為“com.example.www”的行有1個版本。contents:html列包含整個網站的HTML。
在這個表格中的空的單元格並不占用空間
下圖是一個模擬,目的在於解釋說明上面我們所說的,便於我們理解:

21. Physical View
雖然,在概念上,表看起來像是一行一行的,但物理上,它們是按照列簇被存儲的。一個新的列修飾符可以在任意時刻被添加到列簇中。
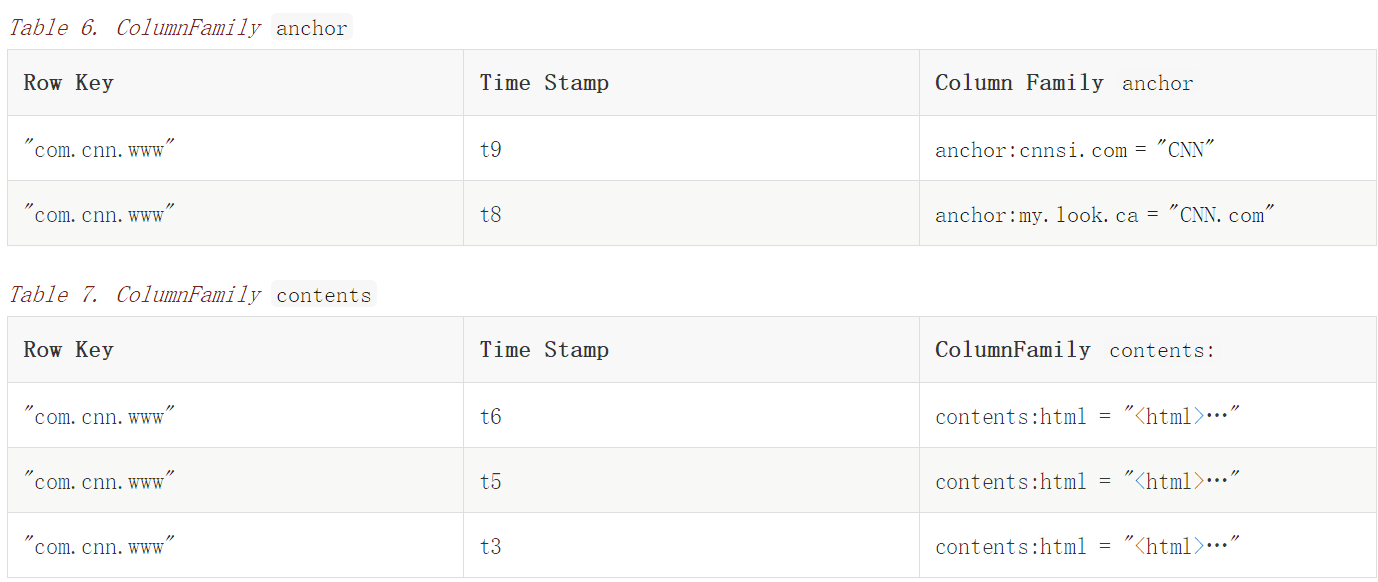
在前面的概念視圖中的空的單元格是不被存儲的。因此,請求contents:html列並且timestamp為t8將返回沒有值。然而,如果不指定timestamp,那麼某個列的大部分值都會被返回。如果指定多個版本,只有找到的第一個會被返回,因為數據是按照timestamp降序存儲的。
22. Namespace
一個命名空間是表的一個邏輯分組
23. Table
24. Row
行按照row key字典升序存儲
25. Column Family
Columns in Apache HBase are grouped into column families.
列簇中所有的列成員都有相同的首碼。例如,列courses:history和courses:math都是courses這個列簇的成員。用冒號分隔列簇和列修飾符。列簇首碼必須由可以列印輸出的字元組成。列修飾符可以由任意位元組組成。列簇必須在表被定義的時候就聲明好,因此列就不需要在表創建的時候定義了,並且可以隨時新增。
物理上,所有的列簇成員被存儲在一起。
26. Cells
A {row, column, version} tuple exactly specifies a cell in HBase.
27. Data Model Operations
數據模型有4個主要操作,分別是Get、Put、Scan和Delete。這些操作是應用在表上的。
27.1. Get
返回指定行的屬性
27.2. Put
添加新的行到表中,或者更新已經存在的行
27.3. Scans
掃描特定屬性的多行
27.4. Delete
從表中刪除一行
28. Versions
在HBase中,{row,column,version}可以確定一個單元格。當行和列被壓縮成位元組的時候,版本用long類型指定。在HBase中,版本以降序存儲,所以,最近的值總是最先被髮現。
29. Sort Order
對於所有的數據模型操作,HBase以數據被存儲時的順序返回。首先按行排序,其次按列簇,再其次按列修飾符,最後是timestamp。(PS:前是三個是字典升序,最後一個timestamp是降序)
30. Column Metadata
不存儲列的元數據,因此,HBase可以支持每一行有許多列,行與行之間可以有多種不同的列。
31. Joins
HBase不直接join操作,至少不支持關係型資料庫那種join。在HBase中,讀取數據通過Get和Scan。
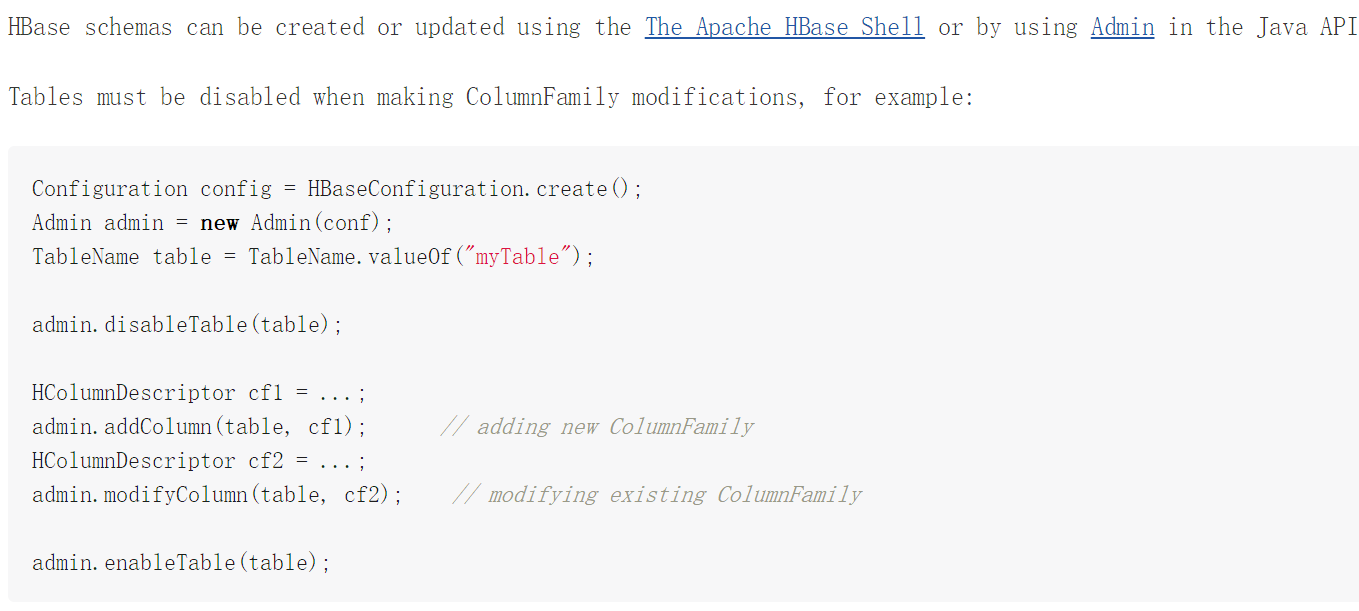
33. Schema Creation
34. Table Schema Rules Of Thumb
- regions的大小在10~50GB之間
- cells的大小不超過10MB
- 典型的,每個表的列簇在1~3個之間。HBase的表不應該被設計成模仿關係型資料庫的表
- 一個有1~2個列簇的表所擁有的regions大約在50~100個左右
- 保持你的列簇名字儘可能的短
50. HBase as a MapReduce Job Data Source and Data Sink
HBase可以作為MapReduce作業的數據源。對於讀寫HBase的MapReduce作業,建議使用TableMapper和TableReducer。
如果你運行HBase作為數據源的MapReduce作業,你需要在配置文件中指定表和列名。
當你從HBase讀取數據的時候,TableInputFormat請求regions的列表並且作為一個map。
54. HBase MapReduce Examples

