
本文以海量大數據高併發查詢,低更新操作的場景為前提,提出一個基於分散式設計的資料庫解決方案,大致介紹了資料庫的部署方案及每個節點的功能,同時對主要的查詢和更新流程做了簡單介紹,闡述了一種可能的解決思路,為大家提供一個參照。 ...
前言
隨著互聯網的發展,分散式技術的逐漸成熟,動態水平擴展和自動容災備份、一鍵部署等技術方案不斷成熟,各大中小互聯網企業都在嘗試切換將產品的技術方案到分散式的方案,但是分散式的技術方案有一個業內比較難以解決的問題,就是分散式事務的處理,大部分都是將業務儘量限制在同庫中,避免跨庫事務,或者採用消息隊列處理分散式事務,或者採用DTC來處理,但是性能都不是太理想。在閱讀關於淘寶資料庫OceanBase的一些文章時受到啟發,想到一個不成熟的方案,也可以說是對OceanBase的一些思路的總結,在這裡寫出來給大家分享一下,也歡迎指出其中不合理或可改善的地方。
使用場景
1.海量數據;
2.讀取壓力大而更新操作的場景少;
3.保障高可用,最終一致性;
架構圖
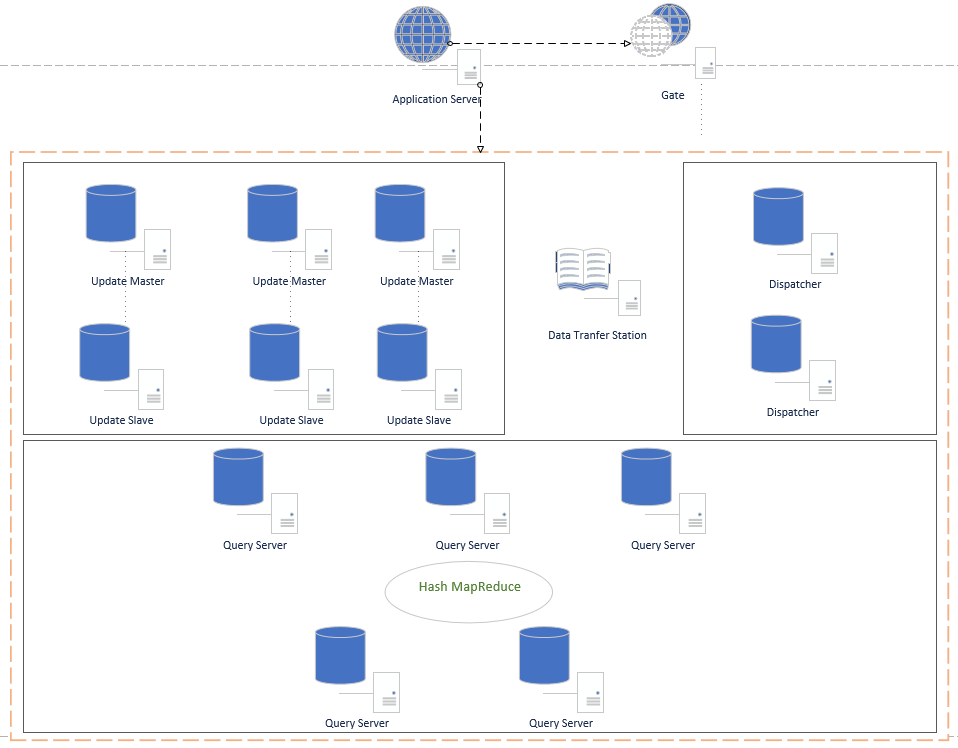
節點功能
1. Application Server 應用伺服器,這裡只畫了一臺,實際生產環境中可能是幾百上千個Host的服務,主要是業務服務;
2.Gate Gate中保持著數據中心各個功能節點的狀態信息,Application Server從Gate中獲取到需要操作的主機地址,然後再與數據中心指定的節點進行通信;Gate中保留的節點信息會記錄節點的路由ip和埠,節點的狀態,另外記錄節點的功能特點;Gate中會開一個守護進程負責與數據中心的各個節點進行通信(每個節點也有專門負責通信的守護進程),節點的可用狀態通過心跳檢測(節點是否拓機),節點是否處於busy狀態由節點自己彙報到Gate守護進程,Gate守護進程再更新配置信息;
3.Update Master 負責資料庫的更新操作,該節點並不保存所有數據,只是在需要更新時,將需要的數據從對應的查詢庫中獲取到數據,然後在本機做事務更新,完成後,也是提交到本機。並通過某種機制(定時器或達到某個閾值),就備份本機數據,並提交到Data Transfer Station,提交成功後,清空本地資料庫。這裡的難點是如果知道需要獲取哪些數據,我的初步思路是,由應用服務自己告訴該節點,這是最簡單的方式;
4.Update Slave:備用的Update伺服器,當Master拓機時自動成為Master代替UpdateMaster的工作。守護進程實時監控Master狀態;
5.Data Transfer Station 數據中轉中心,負責收集變更數據,並備份存儲,以防需要跟蹤或恢複數據等。在Update Master提交備份數據後,查找空閑的Dispatcher,再由Dispatcher拉去需要的數據,分發同步到Query Server中;
6.Dispatcher 數據分發器,分發器從Data Transfer Station獲取到數據,並從Gate中獲取空閑的、未同步過該數據的Query Server,並將該Query Server標記為同步數據中,然後同步數據,同步完成後,將同步日誌記錄,返回給Data Transfer Station,接著繼續下一個Query Server進行同步,直到所有都同步完成。完成後,Data Transfer Station將該份數據標記為所有節點已同步(同步過程中Query Server還是可以提供查詢服務);
7.Query Server 查詢伺服器,負責對外的數據查詢。這裡有一點還在考慮中,就是是否採用分片,因為數據量大,不分片肯定會導致單機的查詢效率下降,分片的話,如採用Hash演算法計算分片,會增加查詢的複雜度,最主要是,數據下發時,需要考慮該更新的數據是在哪個分片上,相對會比較複雜;
查詢數據請求流程圖(未使用Hash MapReduce,如果使用,則需要在過程中添加Hash計算數據所在的節點)

更新數據請求流程圖
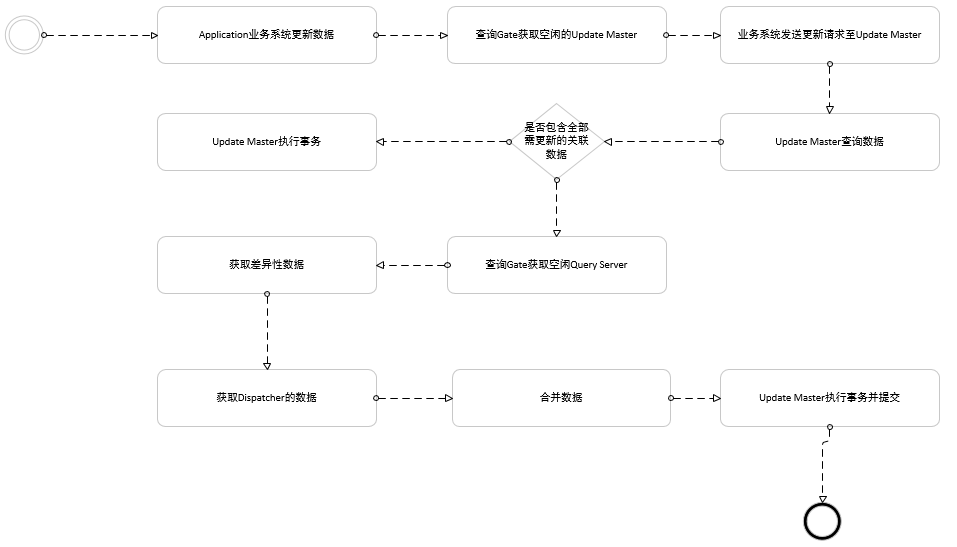
這裡獲取更新數據時,應該是全量的,即Update Master里的數據+Query Server的數據+Dispatcher未分發完成的數據;舉例來說,假設查詢到的某個賬戶餘額100,000元,需要做一個轉賬業務,需要轉出10000元,並且之前已經做過一次轉賬5000元,但是這筆5000元的轉賬還未同步到查詢伺服器中,那麼該次轉賬應該是100,000元減去5,000元,然後再去做轉出10,000元的操作。最終賬戶餘額應該是85,000元。另外,如果查詢要做到強一致性,也應該這樣做一個差異性數據合併,再轉發給業務服務,這樣就能做到信息的一致性和實時性。
以上僅提供一種思路,實現可結合自己的業務,對該解決方案做一些更改,具體選取技術。具體細節也考慮不是很周全,如有思路上的錯誤,請多指教。
本文原創,如有轉載,請註明出處。


