
Mapper Mapper的maps階段將輸入鍵值對經過計算得到中間結果鍵值對,框架會將中間結果按照key進行分組,然後傳遞給reducer以決定最終的輸出。用戶可以通過Job.setGroupingComparatorClass(Class)來指定一個Comparator。 Mapper的輸出會被 ...

Mapper
Mapper的maps階段將輸入鍵值對經過計算得到中間結果鍵值對,框架會將中間結果按照key進行分組,然後傳遞給reducer以決定最終的輸出。用戶可以通過Job.setGroupingComparatorClass(Class)來指定一個Comparator。
Mapper的輸出會被排序,然後被分到不同的區,以供reducer處理。分區數與Reducer任務數相同。
如果指定了Combiner,那麼會對中間結果進行本地聚集操作,這樣可以減少從Mapper到Reducer傳輸的數量。
Reducer
Reducer減少中間結果的值,這些中間結果的值共用一個key
Reducer有三個主要階段:shuffle、sort、reduce
Shuffle:這個階段的輸入時Mapper的輸出,而且是被排過序的。這個階段會從所有Mapper的輸出中抓取相關分區。
Sort:這個階段會按照key分組。Shuffle和Sort階段是同時進行的,在抓取maps輸出的時候就已經進行了合併
Reduce:Reducer的輸出是沒有排序的


Partitioner
Partitioner控制Mapper中間結果的keys分區。預設的Partitioner是HashPartitioner。


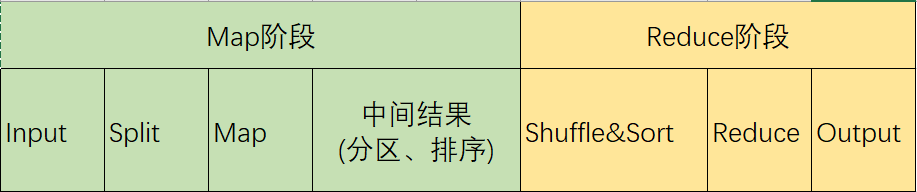
1、預設的分區方式是哈希取模(HashPartitioner),它會用key的哈希值經過計算然後對reduce任務書取模,以決定中間結果在哪個分區。由於是先用key值取哈希,再進行模運算,那麼key值相同的會進入到同一個分區。
2、Reducer任務的數量是根據公式算出來的。大概是<no. of nodes> * <no. of maximum containers per node> 的0.95倍到1.75倍之間。也就是說Reducer任務數決定了會有多少個分區。
3、分區是框架做的,中間結果的排序可以自定義
4、如果指定了Combiner則可以對中間結構進行本地聚集操作
5、Shuffle階段是通過HTTP抓取相關的分區並且對分區中的key進行分組排序


