
SQL Server In-Memory OLTP Internals for SQL Server 2016 這份白皮書是在上一份《SQL Server In-Memory OLTP Internals Overview》基礎上的,很多東西都是一樣的不再介紹,只介紹不相同的部分。 行和索引存儲 R ...
SQL Server In-Memory OLTP Internals for SQL Server 2016 這份白皮書是在上一份《SQL Server In-Memory OLTP Internals Overview》基礎上的,很多東西都是一樣的不再介紹,只介紹不相同的部分。
行和索引存儲
Range索引
Range索引在2014的時候還是不支持的。Range index 使用bwtree數據結構。Bwtree和btree一樣有葉子結點和中間節點。最重要的不通點是,bwtree page指針是一個邏輯的page id,而不是物理的page no。PID表示mapping table 上的位置,mapping table把PID和物理記憶體地址關聯。Bwtree的index page是從來不更新的,而是增加一個新的,然後讓mapping table的相同PID指向一個不同的物理記憶體地址。具體的bwtree的演算法可以看:http://www.cnblogs.com/Amaranthus/p/4375331.html
列存儲索引
列存儲索引基本結構
SQL Server 2016記憶體優化表支持聚集的列存儲索引。列存儲索引是高複合的索引,並不是由行來組織,而是用列來組織的。行被分為多個組,一個組最多可以有2^20行,然後把某一列的數據放入行組中,不會去管剩下的行。每個行組,SQL Server都會使用Vertipaq壓縮演算法,重新編碼和排列行組中的順序來打到最有的壓縮效果。每個行組中的列都是獨立保存的,這個結構稱之為段(segment),每個段都是一個LOB,保存在LOB的分配段元中。段是數據讀寫的基本單元,如圖,表示吧一組多個索引列轉化為幾個段

上圖中,表被分為3個行組,每個行組有4個段,一共有12個段。
為了支持聚集行存儲索引的更新,有2個額外的結構。一個獨立的內部表(deleted rows table DRT)。顧名思義是用來做被刪除行的bitmap,用來保存所有已經刪除的行的rowid。新行加入會被保存在一個堆中,Delta Store。當行數達到一定行數(通常是2^20或者10萬行),SQL Server會吧這些行轉化為新的壓縮的行組。
記憶體優化表中聚集列存儲索引和記憶體優化表的非聚集索引是分開保存的,是數據的一個副本。實際上,記憶體優化表的聚集列存儲索引你可以理解為,保存了所有列的非聚集列存儲索引。因為數據是高效壓縮的,因此開銷比較少。因為類存儲索引可以壓縮到原始數據的10%,因此開銷也只有10%。
所有的類存儲索引段都是在記憶體中的。為了恢復的目的,每個行組在記憶體優化文件組中都保存成一個獨立的文件類型為LARGE DATA,在文件中對於某個行組,所有的段都是存放在一起的。SQL Server也維護了一個指針,指向每個段並且可以訪問這個段,特別是訪問了部分列的時候。這個部分會在下麵CHECKPOINT FILES的時候介紹。新的行會被以列存儲索引保存,但是並不會馬上加入到壓縮行組中,新的行只能使用記憶體優化表的其他索引來訪問。如圖,新的行和整個表分開維護的。你可以認為這些行是“delta rowgroup”和磁碟表的Delta Store類似,但是這些行是記憶體優化表的一部分,但是不是技術上的列存儲索引的一部分。實際上是課件的delta rowgroup
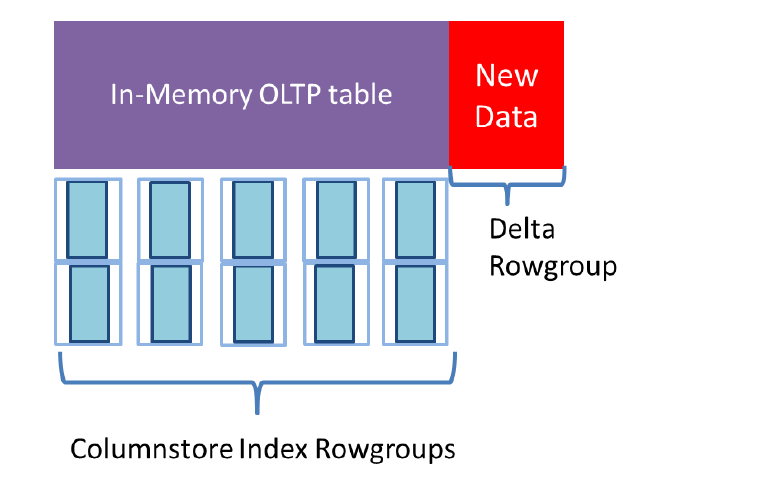
記憶體優化表中的列存儲索引只能在interop模式下由優化器進行選擇。查詢使用類存儲索引可以併發並且對於高性能有很多好處。原生編譯過程是不會使用列存儲索引的,並且所有的查詢都不會併發執行。若一個SQL Server 2016的記憶體優化表有聚集列存儲索引,那麼就有2個varheap,一個用於壓縮行組,另外一個用來保存新行,可以讓SQL Server快速識別哪些行還沒有進入壓縮段,這些行也在可見的delta rowgroup中。
有2個後臺線程每2分鐘執行一次,用來檢查delta rowgroup中的行。註意這些行包含最新插入的,和update的,在記憶體優化表update就是delete+insert。如果這些行數超過10萬那麼就有下麵2個操作:
- 行會被覆制到一個或者多個行組,每個段都會被壓縮轉化變成聚集列存儲索引的一部分。
- 行會從特定的記憶體分配器移到常規的記憶體存儲。
SQL Server並不會是實際統計行數,而是使用評估。沒有行組的行數可以超過1048576.如果超過有10萬行,那麼就會創建另外一個行組。如果小於10萬行那麼這些行還是會被留在原來的地方。
因為最新插入的行會被頻繁更新,或者會被刪除,想要延遲對最新行的壓縮,可以設置一個等待量。當記憶體優化表有聚集列存儲索引,那麼就可以增加一個COMPRESSION_DELAY的參數,指定新行必須在delta rowgroup中呆多久。只有超過參數的行數超過10萬才會被壓縮到常規的列存儲索引行組中。
當行被轉換到壓縮rowgroup之後,所有刪除的行都會被放到Delete Rows表中,和磁碟表的聚集列存儲索引。當行多的時候查詢會很沒有效率。這種情況下重組列存儲索引並沒有什麼用,除非刪除並且重建索引。一旦rowgroup中90%的行被刪除,剩下的10%會自動被插入到未壓縮的varheap,在記憶體優化表的Delta rowgroup中。Rowgroup的存儲會被進行垃圾回收。
Note:
前面提到的,如果記憶體優化表有任何LOB或者溢出列,列存儲索引不能在上面被創建。因為最大的行不能超過8060位元組。另外一旦記憶體優化表有一個列存儲索引,就不能使用alter table操作。需要先刪除列存儲索引,alter,然後再創建列存儲索引。
以下是創建記憶體優化表的腳本,有2個索引,一個range索引一個列存儲索引,然後查詢記憶體消費。並且設置COMPRESSION_DELAY為60分鐘。
USE master; GO SET NOCOUNT ON; GO DROP DATABASE IF EXISTS IMDB; GO CREATE DATABASE IMDB; GO ALTER DATABASE IMDB ADD FILEGROUP IMDB_mod_FG CONTAINS MEMORY_OPTIMIZED_DATA; GO ALTER DATABASE IMDB ADD FILE ( NAME = 'IMDB_mod' , FILENAME = 'c:\HKData\IMDB_mod' ) TO FILEGROUP IMDB_mod_FG; GO USE IMDB; GO DROP TABLE IF EXISTS dbo.OrderDetailsBig; GO CREATE TABLE dbo.OrderDetailsBig ( OrderID INT NOT NULL , ProductID INT NOT NULL , UnitPrice MONEY NOT NULL , Quantity SMALLINT NOT NULL , Discount REAL NOT NULL INDEX IX_OrderID NONCLUSTERED HASH ( OrderID ) WITH (BUCKET_COUNT = 20000000) , INDEX IX_ProductID NONCLUSTERED ( ProductID ) , CONSTRAINT PK_Order_Details PRIMARY KEY NONCLUSTERED ( OrderID , ProductID ) , INDEX clcsi_OrderDetailsBig CLUSTERED COLUMNSTORE WITH (COMPRESSION_DELAY = 60) ) WITH ( MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA ); GO SELECT OBJECT_NAME(c.object_id) AS table_name , a.xtp_object_id , a.type_desc , minor_id , memory_consumer_id AS consumer_id , memory_consumer_type_desc AS consumer_type_desc , memory_consumer_desc AS consumer_desc , CONVERT(NUMERIC(10, 2), allocated_bytes / 1024. / 1024) AS allocated_MB , CONVERT(NUMERIC(10, 2), used_bytes / 1024. / 1024) AS used_MB FROM sys.memory_optimized_tables_internal_attributes a JOIN sys.dm_db_xtp_memory_consumers c ON a.object_id = c.object_id AND a.xtp_object_id = c.xtp_object_id LEFT JOIN sys.indexes i ON c.object_id = i.object_idAND c.index_id = i.index_id;
返回的結果:
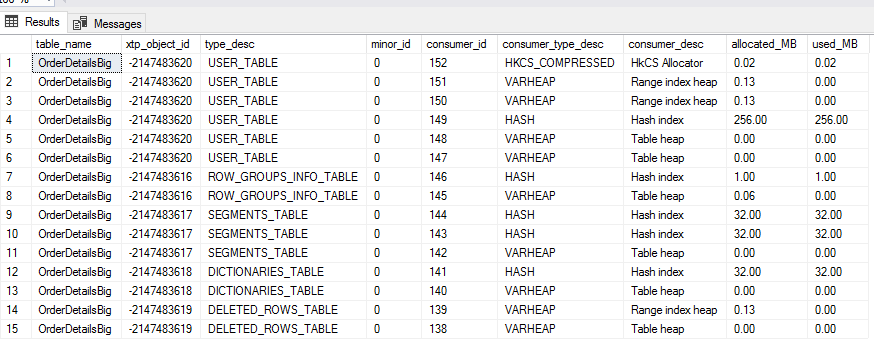
上圖,顯示表自己有6行。有一個記憶體消費者用於壓縮rowgroup(HKCS_COMPRESSED消費者),2個用於range index,1個用於hash index,2個用於表的行存儲(rowstore)(這個和白皮書中說的不同),行存儲中其中一個是為了表中的行,第二個是delta rowgroup。每個有列存儲索引的表都有4個內部表,xtp_object_id都不相同。每個內部表為了訪問方便至少有一個索引用於數據訪問。四個內部表:ROW_GROUP_INFO_TABLE(+hash索引),SEGMENTS_TABLE(+2個hash索引),DICTIONARIES_TABLE(+hash 索引),DELETED_ROW_TABLE(+hash索引)。(這些內部表的細節白皮書沒有介紹)
除了看記憶體消費者之外,另外一個要檢查的DMV是sys.dm_db_column_store_row_group_ physical_stats,這個視圖不單單是顯示了每個COMPRESSED並且OPEN的rowgroup的行數。你可以用一下腳本查看:
BEGIN TRAN; DECLARE @i INT = 0; WHILE ( @i < 10000000 ) BEGIN INSERT INTO dbo.OrderDetailsBig VALUES ( @i, @i % 1000000, @i % 57, @i % 10, 0.5 ); SET @i = @i + 1; IF ( @i % 264 = 0 ) BEGIN COMMIT TRAN; BEGIN TRAN; END; END; COMMIT TRAN; SELECT row_group_id , state_desc , total_rows , trim_reason_desc FROM sys.dm_db_column_store_row_group_physical_stats WHERE object_id = OBJECT_ID('dbo.OrderDetailsBig') ORDER BY row_group_id; GO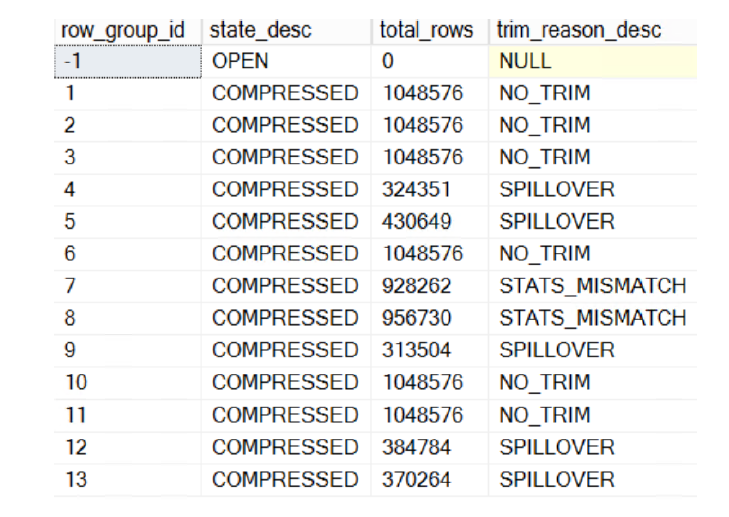
可以通過time_reason_desc欄位可以查看為什麼rowgroup的行會少於1048576行。如果沒有小於1048576那麼就顯示NO_TRIM。因為OPEN的rowgroup是不壓縮的,因此為null,若為STATS_MISMATCH表示行太少,若為SPILLOVER表示有移除導致。


