
剛剛大學畢業,接觸大數據有一年的時間了,把自己的一些學習筆記分享給大家,希望同熱愛大數據的伙伴們一起學習,成長! 資料準備: Hadoop-2.7.1下載:http://pan.baidu.com/s/1o7LKaSU 密碼:64du Jdk下載(文中使用1.7,這裡給得1.8,不影響使用):htt ...
剛剛大學畢業,接觸大數據有一年的時間了,把自己的一些學習筆記分享給大家,希望同熱愛大數據的伙伴們一起學習,成長!
資料準備:
Hadoop-2.7.1下載:http://pan.baidu.com/s/1o7LKaSU 密碼:64du
Jdk下載(文中使用1.7,這裡給得1.8,不影響使用):http://pan.baidu.com/s/1kVEEJ91 密碼:r22t
安裝步驟:
0.關閉防火牆
執行:service iptables stop 這個指令關閉完防火牆後,如果重啟,防火牆會重新建立,所以,如果想重啟後防火牆還關閉,需額外執行:chkconfig iptables off
1.配置主機名
執行: vim /etc/sysconfig/network
編輯主機名
註意:主機名里不能有下滑線,或者特殊字元#$,不然會找不到主機導致無法啟動
這種方式更改主機名需要重啟才能永久生效,因為主機名屬於內核參數。
如果不想重啟,可以執行:hostname hadoop01。但是這種更改是臨時的,重啟後會恢復 原主機名。
所以可以結合使用。先修改配置文件,然後執行:hostname hadoop01 。可以達到不重啟或重啟都是主機名都是同一個的目的

2.配置hosts文件
執行:vim /etc/hosts(192.168.161.41是我自己機器的ip,這裡必須寫入自己本機的ip)

3.配置免秘鑰登錄
在hadoop01節點執行(執行過hostname hadoop01):
執行:ssh-keygen
然後一直回車,直到出現類似的圖形:
生成節點的公鑰和私鑰,生成的文件會自動放在/root/.ssh目錄下
然後把公鑰發往遠程機器,比如hadoop01向hadoop02發送
執行:ssh-copy-id root@hadoop01
此時,hadoop02節點就是把收到的hadoop秘鑰保存在
/root/.ssh/authorized_keys 這個文件里,這個文件相當於訪問白名單,凡是在此白明白存儲的 秘鑰對應的機器,登錄時都是免密碼登錄的。
當hadoop01再次通過ssh遠程登錄hadoop02時,發現不需要輸入密碼了。

在hadoop02節點執行上述上述步驟,讓hadoop02節點連接hadoop01免密碼登錄
4.配置自己節點登錄的免密碼登錄
如果是單機的偽分散式環境,節點需要登錄自己節點,即hadoop01要登錄hadoop01
但是此時是需要輸入密碼的,所以要在hadoop01節點上
執行:ssh-copy-id root@hadoop01(上面已經給出)
5.安裝和配置jdk
1)安裝jdk
mkdir /usr/local/src/java
rz 上傳jdk tar包
tar -xvf jdk-7u51-linux-x64.tar.gz
配置環境變數
1:vi /etc/profile
2:在尾行添加
#set java environment
JAVA_HOME=/usr/local/src/java/jdk1.7.0_51
JAVA_BIN=/usr/local/src/java/jdk1.7.0_51/bin
PATH=$JAVA_HOME/bin:$PATH
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JAVA_HOME JAVA_BIN PATH CLASSPATH
保存退出
3:source /etc/profile 使更改的配置立即生效
4:java -version 查看JDK版本信息。如顯示1.7.0證明成功。
執行: vi /etc/profile
2)在尾行添加
#set java environment
JAVA_HOME=/usr/local/src/java/jdk1.7.0_51
PATH=$JAVA_HOME/bin:$PATH
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JAVA_HOMEPATH CLASSPATH
保存退出
3)source /etc/profile 使更改的配置立即生效
4)java -version 查看JDK版本信息。如顯示1.7.0證明成功。
6.上傳和解壓hadoop安裝包
執行:tar -xvf hadoop……(包名)
目錄說明:
bin目錄:命令腳本
etc/hadoop:存放hadoop的配置文件
lib目錄:hadoop運行的依賴jar包
sbin目錄:啟動和關閉hadoop等命令都在這裡
libexec目錄:存放的也是hadoop命令,但一般不常用
最常用的就是bin和etc目錄
7.配置hadoop-env.sh
這個文件里寫的是hadoop的環境變數,主要修改hadoop的java_home路徑
切換到 etc/hadoop(cd etc/hadoop)目錄
執行:vim hadoop-env.sh
修改java_home路徑和hadoop_conf_dir 路徑(自己本機的安裝目錄)
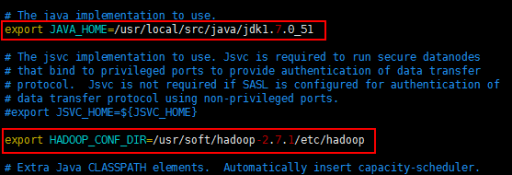
然後執行:source hadoop-env.sh 讓配置立即生效
8.修改core-site.xml
在 etc/hadoop 目錄下
執行:vim core-site.xml
配置如下:
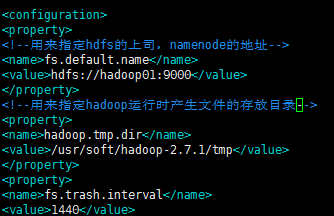
<configuration>
<!--用來指定hdfs的上司,namenode的地址-->
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop01:9000<value>
</property>
<!--用來指定hadoop運行時產生文件的存放目錄-->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/soft/hadoop-2.7.1/tmp</value>
</property>
</configuration>
9.修改vim hdfs-site .xml
配置如下:
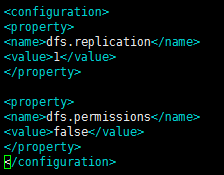
<configuration>
<!--指定hdfs保存數據副本的數量,包括自己,預設值是3-->
<!--如果是偽分佈模式,此值是1-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!--設置 hdfs 的操作許可權, false 表示任何用戶都可以在 hdfs 上操作文件-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
10.修改vim mapred-site.xml
這個文件初始時是沒有的,有的是模板文件,mapred-site.xml.template
所以需要拷貝一份,並重命名為mapred-site.xml
執行:cp mapred-site.xml.template mapred-site.xml
配置如下:
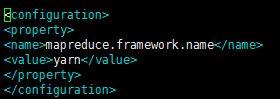
<configuration>
<property>
<!--指定mapreduce運行在yarn上-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn是資源協調工具,
11.修改vim yarn-site.xml
配置如下:

<configuration>
<!--Site specific YARN configuration properties -->
<property>
<!--指定yarn的老大resoucemanager的地址-->
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<!--NodeManager獲取數據的方式-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
12.配置vim slaves文件

13.配置hadoop的環境變數
配置代碼:vim /etc/profile

HADOOP_HOME=/usr/soft/hadoop-2.7.1JAVA_HOME=/usr/local/src/java/jdk1.7.0_51
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export JAVA_HOME PATH CLASSPATH HADOOP_HOME
14.格式化namenode
為什麼要格式化?
執行:hadoop namenode -format
如果不好使,可以重啟linux
當出現:successfully,證明格式化成功

15.啟動Hadoop
cd hadoop-2.7.1/sbin (進入hadoop安裝目錄後執行)
./start-dfs.sh或者sh start-dfs.sh
16.停止Hadoop
./stop-dfs.sh 或者sh stop-dfs.sh
註:如果在啟動時,報錯:Cannot find configuration directory: /etc/hadoop
解決辦法:
編輯etc/hadoop下的hadoop-env.sh 文件,添加如下配置信息:

export HADOOP_CONF_DIR=/home/software/hadoop-2.7.1/etc/hadoop
然後執行source hadoop-env.sh 使配置立即生效
執行:start-yarn.sh 啟動yarn相關的服務
在瀏覽器訪問:
192.168.161.41:50070 來訪問 hadoop 的管理頁面(必須是自己本機的ip)
大家若感興趣,轉載本文,請註明出處

