
什麼叫做覆蓋索引? 解釋一: 就是select的數據列只用從索引中就能夠取得,不必從數據表中讀取,換句話說查詢列要被所使用的索引覆蓋。 解釋二: 索引是高效找到行的一個方法,當能通過檢索索引就可以讀取想要的數據,那就不需要再到數據表中讀取行了。如果一個索引包含了(或覆蓋了)滿足查詢語句中欄位與條件的 ...
什麼叫做覆蓋索引?
- 解釋一: 就是select的數據列只用從索引中就能夠取得,不必從數據表中讀取,換句話說查詢列要被所使用的索引覆蓋。
- 解釋二: 索引是高效找到行的一個方法,當能通過檢索索引就可以讀取想要的數據,那就不需要再到數據表中讀取行了。如果一個索引包含了(或覆蓋了)滿足查詢語句中欄位與條件的數據就叫做覆蓋索引。
- 解釋三:是非聚集組合索引的一種形式,它包括在查詢里的Select、Join和Where子句用到的所有列(即建立索引的欄位正好是覆蓋查詢語句[select子句]與查詢條件[Where子句]中所涉及的欄位,也即,索引包含了查詢正在查找的所有數據)。
不是所有類型的索引都可以成為覆蓋索引。覆蓋索引必須要存儲索引的列,而哈希索引、空間索引和全文索引等都不存儲索引列的值,所以MySQL只能使用B-Tree索引做覆蓋索引
當發起一個被索引覆蓋的查詢(也叫作索引覆蓋查詢)時,在EXPLAIN的Extra列可以看到“Using index”的信息

幾種優化場景:
1.無WHERE條件的查詢優化:
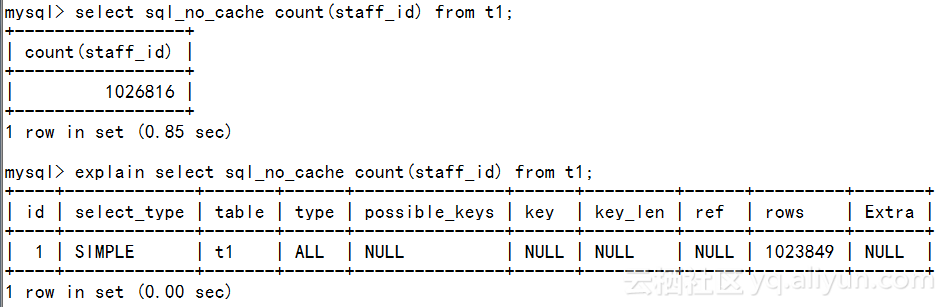
執行計劃中,type 為ALL,表示進行了全表掃描
如何改進?優化措施很簡單,就是對這個查詢列建立索引。如下,
ALERT TABLE t1 ADD KEY(staff_id);
- 再看一下執行計劃
explain select sql_no_cache count(staff_id) from t1\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: t1 type: index possible_keys: NULL key: staff_id key_len: 1 ref: NULL rows: 1023849
Extra: Using index
1 row in set (0.00 sec)
possible_key: NULL,說明沒有WHERE條件時查詢優化器無法通過索引檢索數據,這裡使用了索引的另外一個優點,即從索引中獲取數據,減少了讀取的數據塊的數量。 無where條件的查詢,可以通過索引來實現索引覆蓋查詢,但前提條件是,查詢返回的欄位數足夠少,更不用說select *之類的了。畢竟,建立key length過長的索引,始終不是一件好事情。
- 查詢消耗

從時間上看,小了0.13 sec
2、二次檢索優化
如下這個查詢:
select sql_no_cache rental_date from t1 where inventory_id<80000; … … | 2005-08-23 15:08:00 | | 2005-08-23 15:09:17 | | 2005-08-23 15:10:42 | | 2005-08-23 15:15:02 | | 2005-08-23 15:15:19 | | 2005-08-23 15:16:32 | +---------------------+ 79999 rows in set (0.13 sec)
執行計劃:
explain select sql_no_cache rental_date from t1 where inventory_id<80000\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: t1 type: range possible_keys: inventory_id key: inventory_id key_len: 3 ref: NULL rows: 153734 Extra: Using index condition 1 row in set (0.00 sec)
Extra:Using index condition 表示使用的索引方式為二級檢索,即79999個書簽值被用來進行回表查詢。可想而知,還是會有一定的性能消耗的
嘗試針對這個SQL建立聯合索引,如下:
alter table t1 add key(inventory_id,rental_date);
執行計劃:
explain select sql_no_cache rental_date from t1 where inventory_id<80000\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: t1 type: range possible_keys: inventory_id,inventory_id_2 key: inventory_id_2 key_len: 3 ref: NULL rows: 162884 Extra: Using index 1 row in set (0.00 sec)
Extra:Using index 表示沒有會標查詢的過程,實現了索引覆蓋
3、分頁查詢優化
如下這個查詢場景
select tid,return_date from t1 order by inventory_id limit 50000,10; +-------+---------------------+ | tid | return_date | +-------+---------------------+ | 50001 | 2005-06-17 23:04:36 | | 50002 | 2005-06-23 03:16:12 | | 50003 | 2005-06-20 22:41:03 | | 50004 | 2005-06-23 04:39:28 | | 50005 | 2005-06-24 04:41:20 | | 50006 | 2005-06-22 22:54:10 | | 50007 | 2005-06-18 07:21:51 | | 50008 | 2005-06-25 21:51:16 | | 50009 | 2005-06-21 03:44:32 | | 50010 | 2005-06-19 00:00:34 | +-------+---------------------+ 10 rows in set (0.75 sec)
在未優化之前,我們看到它的執行計劃是如此的糟糕
explain select tid,return_date from t1 order by inventory_id limit 50000,10\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: t1 type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 1023675 1 row in set (0.00 sec)
看出是全表掃描。加上而外的排序,性能消耗是不低的
如何通過覆蓋索引優化呢?
我們創建一個索引,包含排序列以及返回列,由於tid是主鍵欄位,因此,下麵的複合索引就包含了tid的欄位值
alter table t1 add index liu(inventory_id,return_date);
那麼,效果如何呢?
select tid,return_date from t1 order by inventory_id limit 50000,10; +-------+---------------------+ | tid | return_date | +-------+---------------------+ | 50001 | 2005-06-17 23:04:36 | | 50002 | 2005-06-23 03:16:12 | | 50003 | 2005-06-20 22:41:03 | | 50004 | 2005-06-23 04:39:28 | | 50005 | 2005-06-24 04:41:20 | | 50006 | 2005-06-22 22:54:10 | | 50007 | 2005-06-18 07:21:51 | | 50008 | 2005-06-25 21:51:16 | | 50009 | 2005-06-21 03:44:32 | | 50010 | 2005-06-19 00:00:34 | +-------+---------------------+ 10 rows in set (0.03 sec)
可以發現,添加複合索引後,速度提升0.7s! 我們看一下改進後的執行計劃
explain select tid,return_date from t1 order by inventory_id limit 50000,10\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: t1 type: index possible_keys: NULL key: liu key_len: 9 ref: NULL rows: 50010
Extra: Using index
1 row in set (0.00 sec)
執行計劃也可以看到,使用到了複合索引,並且不需要回表
對比一下如下的改寫SQL,思想是通過索引消除排序
select a.tid,a.return_date from t1 a inner join (select tid from t1 order by inventory_id limit 800000,10) b on a.tid=b.tid;
併在此基礎上,我們為inventory_id列創建索引,並刪除之前的覆蓋索引
alter table t1 add index idx_inid(inventory_id); drop index liu;
然後收集統計信息。
select a.tid,a.return_date from t1 a inner join (select tid from t1 order by inventory_id limit 800000,10) b on a.tid=b.tid; +--------+---------------------+ | tid | return_date | +--------+---------------------+ | 800001 | 2005-08-24 13:09:34 | | 800002 | 2005-08-27 11:41:03 | | 800003 | 2005-08-22 18:10:22 | | 800004 | 2005-08-22 16:47:23 | | 800005 | 2005-08-26 20:32:02 | | 800006 | 2005-08-21 14:55:42 | | 800007 | 2005-08-28 14:45:55 | | 800008 | 2005-08-29 12:37:32 | | 800009 | 2005-08-24 10:38:06 | | 800010 | 2005-08-23 12:10:57 | +--------+---------------------+
這種優化手段較前者時間多消耗了大約140ms。這種優化手段雖然使用索引消除了排序,但是還是要通過主鍵值回表查詢。因此,在select返回列較少或列寬較小的時候,我們可以通過建立複合索引的方式優化分頁查詢,效果更佳,因為它不需要回表!
參考文獻:
[1] 袋鼠雲技術團隊博客,https://yq.aliyun.com/articles/62419
[2] Baron Schwartz等 著,寧海元等 譯 ;《高性能MySQL》(第3版); 電子工業出版社 ,2013


