
Spark對很多種文件格式的讀取和保存方式都很簡單。Spark會根據文件擴展名選擇對應的處理方式。 Spark支持的一些常見文件格式如下: 1、文本文件 使用文件路徑作為參數調用SparkContext中的textFile()函數,就可以讀取一個文本文件。也可以指定minPartitions控制分區 ...
Spark對很多種文件格式的讀取和保存方式都很簡單。Spark會根據文件擴展名選擇對應的處理方式。
Spark支持的一些常見文件格式如下:

1、文本文件
使用文件路徑作為參數調用SparkContext中的textFile()函數,就可以讀取一個文本文件。也可以指定minPartitions控制分區數。傳遞目錄作為參數,會把目錄中的各部分都讀取到RDD中。例如:
val input = sc.textFile("E:\\share\\new\\chapter5")
input.foreach(println)
chapter目錄有三個txt文件,內容如下:
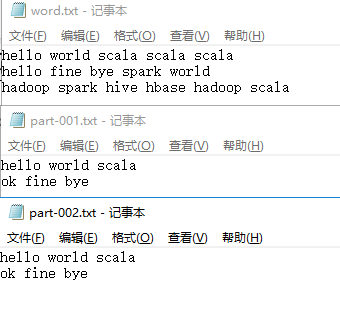
輸出結果:

用SparkContext.wholeTextFiles()也可以處理多個文件,該方法返回一個pair RDD,其中鍵是輸入文件的文件名。
例如:
val input = sc.wholeTextFiles("E:\\share\\new\\chapter5")
input.foreach(println)
輸出結果:

保存文本文件用saveAsTextFile(outputFile)
- JSON
JSON是一種使用較廣的半結構化數據格式,這裡使用json4s來解析JSON文件。
如下:
import org.apache.spark.{SparkConf, SparkContext}
import org.json4s.ShortTypeHints
import org.json4s.jackson.JsonMethods._
import org.json4s.jackson.Serialization
object TestJson {
case class Person(name:String,age:Int)
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("JSON")
val sc = new SparkContext(conf)
implicit val formats = Serialization.formats(ShortTypeHints(List()))
val input = sc.textFile("E:\\share\\new\\test.json")
input.collect().foreach(x => {var c = parse(x).extract[Person];println(c.name + "," + c.age)})
}
}
json文件內容:
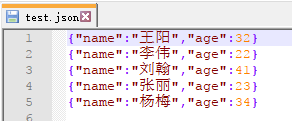
輸出結果:

保存JSON文件用saveASTextFile(outputFile)即可
如下:
val datasave = input.map { myrecord =>
implicit val formats = DefaultFormats
val jsonObj = parse(myrecord)
jsonObj.extract[Person]
}
datasave.saveAsTextFile("E:\\share\\spark\\savejson")
輸出結果:

- CSV文件
讀取CSV文件和讀取JSON數據相似,都需要先把文件當作普通文本文件來讀取數據,再對數據進行處理。
如下:
import org.apache.spark.{SparkConf, SparkContext}
import java.io.StringReader
import au.com.bytecode.opencsv.CSVReader
object DataReadAndSave {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("CSV")
val sc = new SparkContext(conf)
val input = sc.textFile("E:\\share\\spark\\test.csv")
input.foreach(println)
val result = input.map{
line =>
val reader = new CSVReader(new StringReader(line))
reader.readNext()
}
for(res <- result){
for(r <- res){
println(r)
}
}
}
}
test.csv內容:

輸出結果:

保存csv
如下:
val inputRDD = sc.parallelize(List(Person("Mike", "yes")))
inputRDD.map(person => List(person.name,person.favoriteAnimal).toArray)
.mapPartitions { people =>
val stringWriter = new StringWriter()
val csvWriter = new CSVWriter(stringWriter)
csvWriter.writeAll(people.toList)
Iterator(stringWriter.toString)
}.saveAsTextFile("E:\\share\\spark\\savecsv")
- SequenceFile
SequenceFile是由沒有相對關係結構的鍵值對文件組成的常用Hadoop格式。是由實現Hadoop的Writable介面的元素組成,常見的數據類型以及它們對應的Writable類如下:

讀取SequenceFile
調用sequenceFile(path , keyClass , valueClass , minPartitions)
保存SequenceFile
調用saveAsSequenceFile(outputFile)
- 對象文件
對象文件使用Java序列化寫出,允許存儲只包含值的RDD。對象文件通常用於Spark作業間的通信。
保存對象文件調用 saveAsObjectFile 讀取對象文件用SparkContext的objectFile()函數接受一個路徑,返回對應的RDD
- Hadoop輸入輸出格式
Spark可以與任何Hadoop支持的格式交互。
讀取其他Hadoop輸入格式,使用newAPIHadoopFile接收一個路徑以及三個類,第一個類是格式類,代表輸入格式,第二個類是鍵的類,最後一個類是值的類。
hadoopFile()函數用於使用舊的API實現的Hadoop輸入格式。
KeyValueTextInputFormat 是最簡單的 Hadoop 輸入格式之一,可以用於從文本文件中讀取鍵值對數據。每一行都會被獨立處理,鍵和值之間用製表符隔開。
例子:
import org.apache.hadoop.io.{IntWritable, LongWritable, MapWritable, Text}
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
import org.apache.spark._
import org.apache.hadoop.mapreduce.Job
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat
object HadoopFile {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("hadoopfile").setMaster("local")
val sc = new SparkContext(conf)
val job = new Job()
val data = sc.newAPIHadoopFile("E:\\share\\spark\\test.json" ,
classOf[KeyValueTextInputFormat],
classOf[Text],
classOf[Text],
job.getConfiguration)
data.foreach(println)
data.saveAsNewAPIHadoopFile(
"E:\\share\\spark\\savehadoop",
classOf[Text],
classOf[Text],
classOf[TextOutputFormat[Text,Text]],
job.getConfiguration)
}
}
輸出結果:
讀取

保存

若使用舊API如下:
val input = sc.hadoopFile[Text, Text, KeyValueTextInputFormat]("E:\\share\\spark\\test.json
").map { case (x, y) => (x.toString, y.toString) } input.foreach(println)
- 文件壓縮
對數據進行壓縮可以節省存儲空間和網路傳輸開銷,Spark原生的輸入方式(textFile和sequenFile)可以自動處理一些類型的壓縮。在讀取壓縮後的數據時,一些壓縮編解碼器可以推測壓縮類型。

