
最近在學習Oracle的統計信息這一塊,收集統計信息的方法如下: DBMS_STATS.GATHER_TABLE_STATS ( ownname VARCHAR2, 所有者名字 tabname VARCHAR2, 表名 partname VARCHAR2 DEFAULT NULL, 要分析的分區名 ...
最近在學習Oracle的統計信息這一塊,收集統計信息的方法如下:
DBMS_STATS.GATHER_TABLE_STATS ( ownname VARCHAR2, ---所有者名字 tabname VARCHAR2, ---表名 partname VARCHAR2 DEFAULT NULL, ---要分析的分區名 estimate_percent NUMBER DEFAULT NULL, ---採樣的比例 block_sample BOOLEAN DEFAULT FALSE, ---是否塊分析 method_opt VARCHAR2 DEFAULT ‘FOR ALL COLUMNS SIZE 1’,---分析的方式 degree NUMBER DEFAULT NULL, ---分析的並行度 granularity VARCHAR2 DEFAULT ‘DEFAULT’, ---分析的粒度 cascade BOOLEAN DEFAULT FALSE, ---是否分析索引 stattab VARCHAR2 DEFAULT NULL, ---使用的性能表名 statid VARCHAR2 DEFAULT NULL, ---性能表標識 statown VARCHAR2 DEFAULT NULL, ---性能表所有者 no_invalidate BOOLEAN DEFAULT FALSE, ---是否驗證游標依存關係 force BOOLEAN DEFAULT FALSE); ---強制分析,即使鎖表本文主要對參數granularity進行了一下驗證,
granularity:數據分析的力度
--global ---全局
--partition ---只在分區級別做分析
--subpartition --只在子分區級別做分析
驗證步驟如下:
一、創建一個分區表並插入兩條數據,同時在欄位ID上創建索引 drop table test purge; create table test(id number) partition by range(id) (partition p1 values less than (5), partition p2 values less than (10) ) ; insert into test values(1); insert into test values(6); commit; create index ind_id on test(id); 二、收集表的統計信息 exec dbms_stats.gather_table_stats(user,'TEST',cascade=>true); 三、查詢表的統計信息 select num_rows,blocks,last_analyzed from user_tables where table_name = 'TEST'; 結果如下: num_rows:表數據行數
blocks:數據塊數
last_analyzed:最近分析時間
四、查詢表分區信息
select partition_name,num_rows,blocks,last_analyzed from dba_tab_partitions where table_name ='TEST';
num_rows:表數據行數
blocks:數據塊數
last_analyzed:最近分析時間
四、查詢表分區信息
select partition_name,num_rows,blocks,last_analyzed from dba_tab_partitions where table_name ='TEST';
 PARTITION_NAME:分區名稱
NUM_ROWS:數據行數
BLOCKS:數據塊數
last_analyzed:最近分析時間
五、查詢索引統計信息
select num_rows,blevel,last_analyzed from user_indexes where index_name = 'IND_ID';
PARTITION_NAME:分區名稱
NUM_ROWS:數據行數
BLOCKS:數據塊數
last_analyzed:最近分析時間
五、查詢索引統計信息
select num_rows,blevel,last_analyzed from user_indexes where index_name = 'IND_ID';
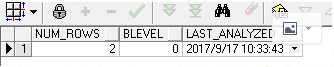 num_rows:索引數據行數
blevel:索引高度
last_analyzed:分析時間
六、新增一個分區
alter table test add partition pmax values less than(maxvalue);
七、往新的分區中插入10000條數據
begin for i in 1..10000 loop ---插入10000條數據
insert into test values(100);
end loop;
commit;
end;
八、創建一個傾斜度非常大的分區
update test set id=10000 where id=100 and rownum=1; ---創造一個非常傾斜的Pmax分區
Commit;
九、查詢分區數據
select id,count(*) from test partition(pmax) group by id;
num_rows:索引數據行數
blevel:索引高度
last_analyzed:分析時間
六、新增一個分區
alter table test add partition pmax values less than(maxvalue);
七、往新的分區中插入10000條數據
begin for i in 1..10000 loop ---插入10000條數據
insert into test values(100);
end loop;
commit;
end;
八、創建一個傾斜度非常大的分區
update test set id=10000 where id=100 and rownum=1; ---創造一個非常傾斜的Pmax分區
Commit;
九、查詢分區數據
select id,count(*) from test partition(pmax) group by id;
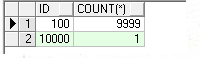 十、不做分析,再次查詢表的統計信息
select num_rows,blocks,last_analyzed from user_tables where table_name = 'TEST';
十、不做分析,再次查詢表的統計信息
select num_rows,blocks,last_analyzed from user_tables where table_name = 'TEST';
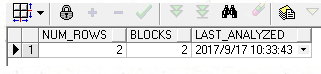 發現數據行數量和數據塊數量沒有發現變化
十一、查詢id=100時執行計劃
set autotrace traceonly
set linesize 1000
select * from test where id=100;
發現數據行數量和數據塊數量沒有發現變化
十一、查詢id=100時執行計劃
set autotrace traceonly
set linesize 1000
select * from test where id=100;
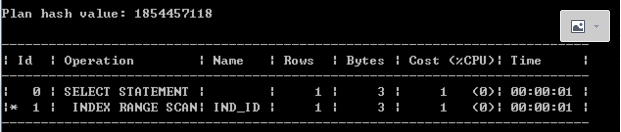 發現走了索引,正常情況下,因為id=100的數據在一個傾斜度非常高的分區pmax中,id為100的數據有9999條,走索引的代價會比走全表的代價還要高(因為走索引需要回表),如果統計信息正確,優化器應該會選擇走全表,但是這裡沒走全表而是走了索引,這裡懷疑是統計信息不正確導致,後面驗證
十二、收集分區統計信息
exec dbms_stats.gather_table_stats(user,'TEST',partname => 'PMAX',granularity => 'PARTITION');
十三、再次查詢表的統計信息和分區統計信息
select partition_name,num_rows,blocks,last_analyzed from dba_tab_partitions where table_name ='TEST';
發現走了索引,正常情況下,因為id=100的數據在一個傾斜度非常高的分區pmax中,id為100的數據有9999條,走索引的代價會比走全表的代價還要高(因為走索引需要回表),如果統計信息正確,優化器應該會選擇走全表,但是這裡沒走全表而是走了索引,這裡懷疑是統計信息不正確導致,後面驗證
十二、收集分區統計信息
exec dbms_stats.gather_table_stats(user,'TEST',partname => 'PMAX',granularity => 'PARTITION');
十三、再次查詢表的統計信息和分區統計信息
select partition_name,num_rows,blocks,last_analyzed from dba_tab_partitions where table_name ='TEST';
 發現和步驟四比較,分區信息有了變化,說明對分區進行統計信息收集後,分區信息進行了更新
select num_rows,blocks,last_analyzed from user_tables where table_name = 'TEST';
發現和步驟四比較,分區信息有了變化,說明對分區進行統計信息收集後,分區信息進行了更新
select num_rows,blocks,last_analyzed from user_tables where table_name = 'TEST';
 發現和步驟三想比,表的統計信息並沒有發生變化,說明統計了分區信息後,表的統計信息麽有更新
發現和步驟三想比,表的統計信息並沒有發生變化,說明統計了分區信息後,表的統計信息麽有更新
十四、再次查詢id=100的數據
 仍然走索引,說明在評估查詢的時候,表的統計信息依然陳舊
十五、查詢索引的統計信息
select num_rows,blevel,last_analyzed from user_indexes where index_name = 'IND_ID';
仍然走索引,說明在評估查詢的時候,表的統計信息依然陳舊
十五、查詢索引的統計信息
select num_rows,blevel,last_analyzed from user_indexes where index_name = 'IND_ID';
 發現索引統計信息較步驟五沒有變化,說明收集了分區的統計信息後,表的索引信息沒有更新
發現索引統計信息較步驟五沒有變化,說明收集了分區的統計信息後,表的索引信息沒有更新
十六、重新再次收集表的統計信息 exec dbms_stats.gather_table_stats(user,'TEST',cascade =>true); 十七、查詢表的統計信息以及索引的統計信息 select num_rows,blocks,last_analyzed from user_tables where table_name = 'TEST';
 表的統計信息已經更新
select num_rows,blevel,last_analyzed from user_indexes where index_name = 'IND_ID';
表的統計信息已經更新
select num_rows,blevel,last_analyzed from user_indexes where index_name = 'IND_ID';
 索引的統計信息也已經更新
十八、再次查詢id=100的執行計劃
索引的統計信息也已經更新
十八、再次查詢id=100的執行計劃
 這次發現走了全表,說明收集了全局的統計信息後,表的統計信息準確了,評估也就準確了。
這次發現走了全表,說明收集了全局的統計信息後,表的統計信息準確了,評估也就準確了。


