
介紹 Kudu 是一個針對 Apache Hadoop 平臺而開發的列式存儲管理器。Kudu 共用 Hadoop 生態系統應用的常見技術特性: 它在 commodity hardware(商品硬體)上運行,horizontally scalable(水平可擴展),並支持 highly availab ...
介紹
Kudu 是一個針對 Apache Hadoop 平臺而開發的列式存儲管理器。Kudu 共用 Hadoop 生態系統應用的常見技術特性: 它在 commodity hardware(商品硬體)上運行,horizontally scalable(水平可擴展),並支持 highly available(高可用)性操作。此外,Kudu 還有更多優化的特點:
- OLAP 工作的快速處理。
- 與 MapReduce,Spark 和其他 Hadoop 生態系統組件集成。
- 與 Apache Impala(incubating)緊密集成,使其與 Apache Parquet 一起使用 HDFS 成為一個很好的可變的替代方案。
- 強大而靈活的一致性模型,允許您根據每個 per-request(請求選擇)一致性要求,包括 strict-- serializable(嚴格可序列化)一致性的選項。
- 針對同時運行順序和隨機工作負載的情況性能很好。
- 使用 Cloudera Manager 輕鬆維護和管理。
- High availability(高可用性)。Tablet server 和 Master 使用 Raft Consensus Algorithm 來保證節點的 -- 高可用,確保只要有一半以上的副本可用,該 tablet 便可用於讀寫。例如,如果 3 個副本中有 2 個或 5 個副本中的 3 個可用,則該 tablet 可用。即使在 leader tablet 出現故障的情況下,讀取功能也可以通過 read-only(只讀的)follower tablets 來進行服務。
- 結構化數據模型。
通過結合這些所有的特性,Kudu 的目標是支持應用家庭中那些難以在當前Hadoop 存儲技術中實現的應用。Kudu 常見的幾個應用場景:
- 實時更新的應用。剛剛到達的數據就馬上要被終端用戶使用訪問到。
時間序列相關的應用,需要同時支持:
根據海量歷史數據查詢。
必須非常快地返回關於單個實體的細粒度查詢。- 實時預測模型的應用,支持根據所有歷史數據周期地更新模型。
有關這些和其他方案的更多信息,請參閱 Example Use Cases。
Kudu-Impala 集成特性
CREATE/ALTER/DROP TABLE
Impala 支持使用 Kudu 作為持久層來 creating(創建),altering(修改)和 dropping(刪除)表。這些表遵循與 Impala 中其他表格相同的 Internal / external(內部 / 外部)方法,允許靈活的數據採集和查詢。
INSERT
數據可以使用與那些使用 HDFS 或 HBase 持久性的任何其他 Impala 表相同的語法插入 Impala 中的 Kudu 表。
UPDATE / DELETE
Impala 支持 UPDATE 和 DELETE SQL 命令逐行或批處理修改 Kudu 表中的已有的數據。選擇 SQL 命令的語法與現有標準儘可能相容。除了簡單 DELETE 或 UPDATE 命令之外,還可以 FROM 在子查詢中指定帶有子句的複雜連接。
Flexible Partitioning(靈活分區)
與 Hive 中的表分區類似,Kudu 允許您通過 hash 或範圍動態預分割成預定義數量的 tablets,以便在集群中均勻分佈寫入和查詢。您可以通過任意數量的 primary key(主鍵)列,任意數量的 hashes 和可選的 list of split rows 來進行分區。參見模式設計。
Parallel Scan(並行掃描)
為了在現代硬體上實現最高的性能,Impala 使用的 Kudu 客戶端可以跨多個 tablets 掃描。
High-efficiency queries(高效查詢)
在可能的情況下,Impala 將謂詞評估下推到 Kudu,以便使謂詞評估為儘可能接近數據。在許多任務中,查詢性能與 Parquet 相當。
有關使用 Impala 查詢存儲在 Kudu 中的數據的更多詳細信息,請參閱 Impala 文檔。
概念和術語
Columnar Data Store(列式數據存儲)
Kudu 是一個 columnar data store(列式數據存儲)。列式數據存儲在強類型列中。由於幾個原因,通過適當的設計,Kudu 對 analytical(分析)或 warehousing(數據倉庫)工作會非常出色。
Read Efficiency(高效讀取)
對於分析查詢,允許讀取單個列或該列的一部分同時忽略其他列,這意味著您可以在磁碟上讀取更少塊來完成查詢。與基於行的存儲相比,即使只返回幾列的值,仍需要讀取整行數據。
Data Compression(數據壓縮)
由於給定的列只包含一種類型的數據,基於模式的壓縮比壓縮混合數據類型(在基於行的解決方案中使用)時更有效幾個數量級。結合從列讀取數據的效率,壓縮允許您在從磁碟讀取更少的塊時完成查詢。請參閱 數據壓縮
Table(表)
一張 table 是數據存儲在 Kudu 的位置。表具有 schema 和全局有序的 primary key(主鍵)。table 被分成稱為 tablets 的 segments。
Tablet
一個 tablet 是一張 table 連續的 segment,與其它數據存儲引擎或關係型資料庫中的 partition(分區)相似。給定的 tablet 冗餘到多個 tablet 伺服器上,並且在任何給定的時間點,其中一個副本被認為是 leader tablet。任何副本都可以對讀取進行服務,並且寫入時需要在為 tablet 服務的一組 tablet server之間達成一致性。
Tablet Server
一個 tablet server 存儲 tablet 和為 tablet 向 client 提供服務。對於給定的 tablet,一個 tablet server 充當 leader,其他 tablet server 充當該 tablet 的 follower 副本。只有 leader 服務寫請求,然而 leader 或 followers 為每個服務提供讀請求。leader 使用 Raft Consensus Algorithm 來進行選舉 。一個 tablet server 可以服務多個 tablets ,並且一個 tablet 可以被多個 tablet servers 服務著。
Master
該 master 保持跟蹤所有的 tablets,tablet servers,Catalog Table 和其它與集群相關的 metadata。在給定的時間點,只能有一個起作用的 master(也就是 leader)。如果當前的 leader 消失,則選舉出一個新的 master,使用 Raft Consensus Algorithm 來進行選舉。master 還協調客戶端的 metadata operations(元數據操作)。例如,當創建新表時,客戶端內部將請求發送給 master。 master 將新表的元數據寫入 catalog table,並協調在 tablet server 上創建 tablet 的過程。所有 master 的數據都存儲在一個 tablet 中,可以複製到所有其他候選的 master。tablet server 以設定的間隔向 master 發出心跳(預設值為每秒一次)。
Raft Consensus Algorithm
Kudu 使用 Raft consensus algorithm 作為確保常規 tablet 和 master 數據的容錯性和一致性的手段。通過 Raft,tablet 的多個副本選舉出 leader,它負責接受以及複製到 follower 副本的寫入。一旦寫入的數據在大多數副本中持久化後,就會向客戶確認。給定的一組 N 副本(通常為 3 或 5 個)能夠接受最多(N - 1)/2 錯誤的副本的寫入。
Catalog Table(目錄表)
catalog table 是 Kudu 的 metadata(元數據中)的中心位置。它存儲有關 tables 和 tablets 的信息。該 catalog table(目錄表)可能不會被直接讀取或寫入。相反,它只能通過客戶端 API 中公開的元數據操作訪問。catalog table 存儲兩類元數據:
- Tables
table schemas, locations, and states(表結構,位置 和狀態)
- Tablets
現有 tablet 的列表,每個 tablet 的副本所在哪些 tablet server,tablet 的當前狀態以及開始和結束的 keys(鍵)。
Logical Replication(邏輯複製)
Kudu 複製操作,不是磁碟上的數據。這被稱為 logical replication(邏輯複製),而不是 physical replication(物理複製)。這有幾個優點 :
- 雖然 insert(插入)和 update(更新)確實通過網路傳輸數據,deletes(刪除)不需要移動任何數據。delete(刪除)操作被髮送到每個 tablet server,它在本地執行刪除。
- 物理操作,如 compaction,不需要通過 Kudu 的網路傳輸數據。這與使用 HDFS 的存儲系統不同,其中 blocks (塊)需要通過網路傳輸以滿足所需數量的副本。
- tablet 不需要在同一時間或相同的時間表上執行壓縮,或者在物理存儲層上保持同步。這會減少由於壓縮或大量寫入負載而導致所有 tablet server 同時遇到高延遲的機會。
架構概述
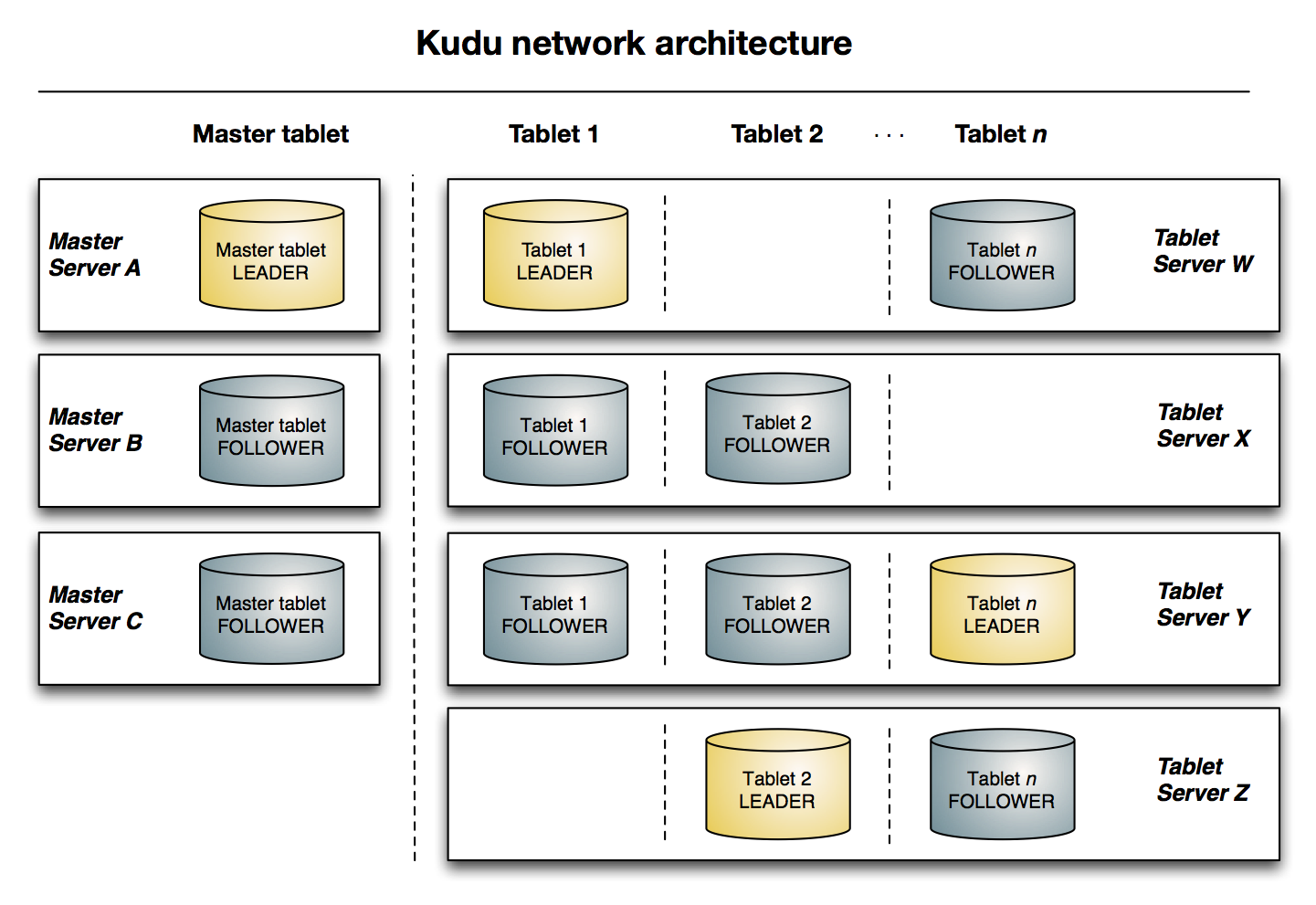
下圖顯示了一個具有三個 master 和多個 tablet server 的 Kudu 集群,每個伺服器都支持多個 tablet。它說明瞭如何使用 Raft 共識來允許 master 和 tablet server 的 leader 和 follow。此外,tablet server 可以成為某些 tablet 的 leader,也可以是其他 tablet 的 follower。leader 以金色顯示,而 follower 則顯示為藍色。
使用場景
Streaming Input with Near Real Time Availability(具有近實時可用性的流輸入)
數據分析中的一個共同挑戰就是新數據快速而不斷地到達,同樣的數據需要靠近實時的讀取,掃描和更新。Kudu 通過高效的列式掃描提供了快速插入和更新的強大組合,從而在單個存儲層上實現了實時分析用例。
Time-series application with widely varying access patterns(具有廣泛變化的訪問模式的時間序列應用)
time-series(時間序列)模式是根據其發生時間組織和鍵入數據點的模式。這可以用於隨著時間的推移調查指標的性能,或者根據過去的數據嘗試預測未來的行為。例如,時間序列的客戶數據可以用於存儲購買點擊流歷史並預測未來的購買,或由客戶支持代表使用。雖然這些不同類型的分析正在發生,插入和更換也可能單獨和批量地發生,並且立即可用於讀取工作負載。Kudu 可以用 scalable (可擴展)和 efficient (高效的)方式同時處理所有這些訪問模式。由於一些原因,Kudu 非常適合時間序列的工作負載。隨著 Kudu 對基於 hash 的分區的支持,結合其對複合 row keys(行鍵)的本地支持,將許多伺服器上的表設置成很簡單,而不會在使用範圍分區時通常觀察到“hotspotting(熱點)”的風險。Kudu 的列式存儲引擎在這種情況下也是有益的,因為許多時間序列工作負載只讀取了幾列,而不是整行。 過去,您可能需要使用多個數據存儲來處理不同的數據訪問模式。這種做法增加了應用程式和操作的複雜性,並重覆了數據,使所需存儲量增加了一倍(或更糟)。Kudu 可以本地和高效地處理所有這些訪問模式,而無需將工作卸載到其他數據存儲。
Predictive Modeling(預測建模)
數據科學家經常從大量數據中開發預測學習模型。模型和數據可能需要在學習發生時或隨著建模情況的變化而經常更新或修改。此外,科學家可能想改變模型中的一個或多個因素,看看隨著時間的推移會發生什麼。在 HDFS 中更新存儲在文件中的大量數據是資源密集型的,因為每個文件需要被完全重寫。在 Kudu,更新發生在近乎實時。科學家可以調整值,重新運行查詢,並以秒或分鐘而不是幾小時或幾天刷新圖形。此外,批處理或增量演算法可以隨時在數據上運行,具有接近實時的結果。
Combining Data In Kudu With Legacy Systems(結合 Kudu 與遺留系統的數據)
公司從多個來源生成數據並將其存儲在各種系統和格式中。例如,您的一些數據可能存儲在 Kudu,一些在傳統的 RDBMS 中,一些在 HDFS 中的文件中。您可以使用 Impala 訪問和查詢所有這些源和格式,而無需更改舊版系統。
安裝前提和準備
硬體:
- 一臺或者多台機器跑kudu-master。建議跑一個master(無容錯機制)、三個master(允許一個節點運行出錯)或者五個master(允許兩個節點出錯)。
- 一臺或者多台機器跑kudu-tserver。當需要使用副本,至少需要三個節點運行kudu-tserver服務。
操作系統(主要是linux系統,windows系統不支持):
- RHEL 6, RHEL 7, CentOS 6, CentOS 7, Ubuntu 14.04 (Trusty), Ubuntu 16.04 (Xenial), Debian 8 (Jessie), or SLES 12.
- 內核和文件系統支持 hole punching 選項。
- ntp服務。
- xfs or ext4 formatted drives
存儲:
- 儘量使用固態存儲,將顯著提高kudu性能。
管理
- 如果你使用的是CDH,需要Cloudera Manager 5.4.3及以上的版本。
環境說明
- os:centos 6.7
- kudu版本:kudu-1.2.0+cdh5.10.0(這裡使用的是cdh5.10的kudu,對應版本為1.2,下載地址:http://archive.cloudera.com/kudu/redhat/6/x86_64/kudu/5.10.0/RPMS/x86_64/)
- 組件安排如下:

安裝ntp服務
# cat /etc/ntp.conf
restrict default kod nomodify notrap nopeer noquery #拒絕IPV4用戶
restrict -6 default kod nomodify notrap nopeer noquery #拒絕ipV6用戶
restrict 127.0.0.1
restrict -6 ::1
restrict 172.31.217.0 mask 255.255.255.0 nomodify notrap #本地網段授權訪問
server 172.31.217.173 #指定上級更新伺服器
server 0.centos.pool.ntp.org
server 1.centos.pool.ntp.org
server 2.centos.pool.ntp.org
server 172.31.217.173 # local clock
fudge 172.31.217.173 stratum 10
# /etc/init.d/ntpd start 各個節點檢查啟動成功,否則啟動kudu相關服務會報錯安裝kudu
安裝kudu-master
安裝
# yum install kudu kudu-master kudu-client0 kudu-client-devel -y基本配置
# cat /etc/kudu/conf/master.gflagfile # Do not modify these two lines. If you wish to change these variables, # modify them in /etc/default/kudu-master. --fromenv=rpc_bind_addresses --fromenv=log_dir --fs_wal_dir=/opt/kudu/master --fs_data_dirs=/opt/kudu/master設置許可權
# mkdir /opt/kudu && chown kudu:kudu /opt/kudu啟動
# /etc/init.d/kudu-master start
安裝kudu-tserver
安裝
# yum install kudu kudu-tserver kudu-client0 kudu-client-devel -y基本配置
# cat /etc/kudu/conf/tserver.gflagfile # Do not modify these two lines. If you wish to change these variables, # modify them in /etc/default/kudu-tserver. --fromenv=rpc_bind_addresses --fromenv=log_dir --fs_wal_dir=/opt/kudu/tserver --fs_data_dirs=/opt/kudu/tserver --tserver_master_addrs=bd-dev-ops-173:7051設置許可權
# mkdir /opt/kudu && chown kudu:kudu /opt/kudu啟動
# /etc/init.d/kudu-tserver start圖形界面
通過master端的web界面觀察運行情況:http://172.31.217.173:8051

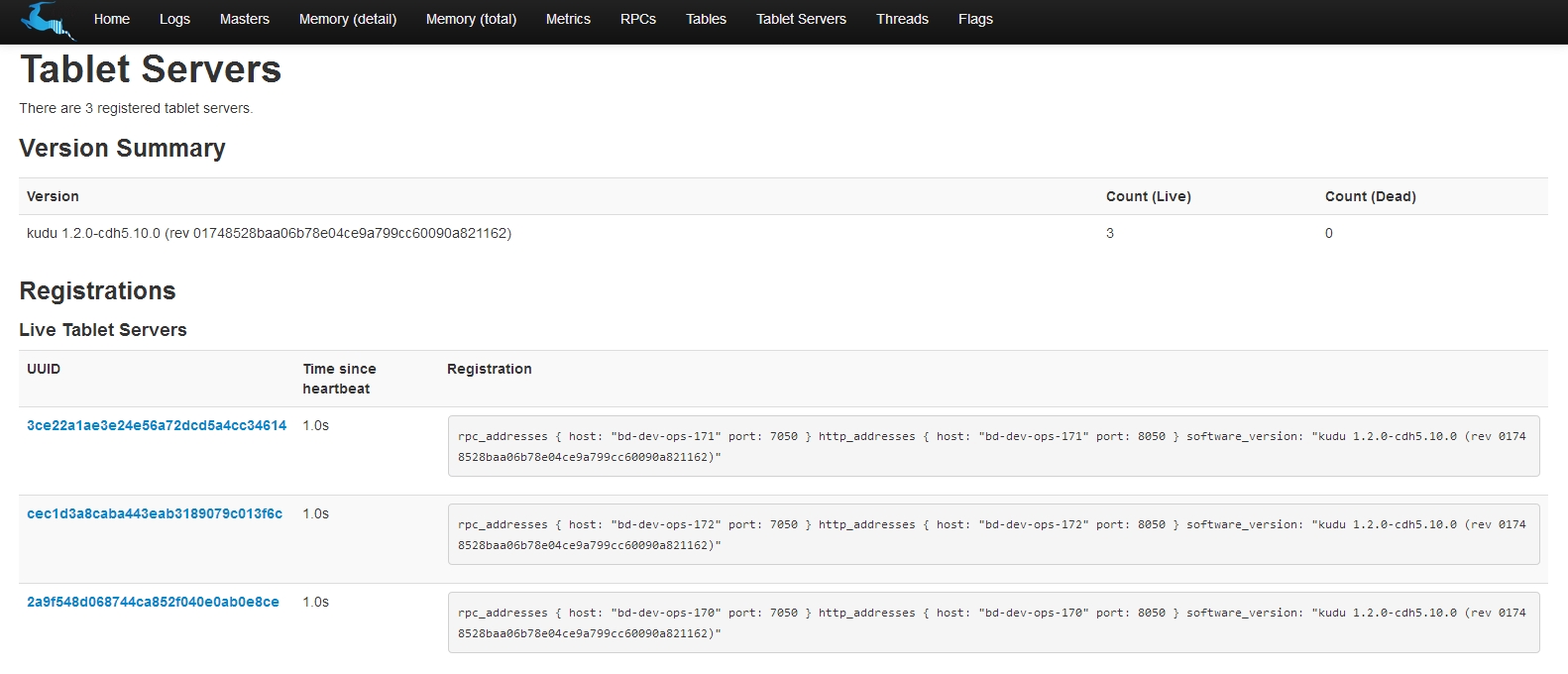
可以看到所有組件都已安裝完畢了。
參考資料
http://kudu.apache.org/docs/index.html


