本文出處:http://www.cnblogs.com/wy123/p/7374078.html(保留出處並非什麼原創作品權利,本人拙作還遠遠達不到,僅僅是為了鏈接到原文,因為後續對可能存在的一些錯誤進行修正或補充,無他) ICP優化原理 Index Condition Pushdown (ICP) ...
本文出處:http://www.cnblogs.com/wy123/p/7374078.html
(保留出處並非什麼原創作品權利,本人拙作還遠遠達不到,僅僅是為了鏈接到原文,因為後續對可能存在的一些錯誤進行修正或補充,無他)
ICP優化原理
Index Condition Pushdown (ICP),也稱為索引條件下推,體現在執行計劃的上是會出現Using index condition(Extra列,當然Extra列的信息太多了,只能做簡單分析)
ICP原理通俗講就是,查詢過程中,直接在查詢引擎層的API獲取數據的時候實現"非直接索引"過濾條件的篩選,而不是查詢引擎層查詢出來之後在Server層篩選。
換句話說就是ICP在獲取數據的同時實現了where的次選條件中無法直接使用索引的情況下的篩選,避免了沒有ICP優化的時候分兩個步驟的實現(獲取數據的過程沒有做次選條件的過濾)
如果是非ICP優化查詢的話,是兩步,第一步是獲取數據,第二步是獲取的數據進行條件篩選。
顯然,相比後者,前者可以一步實現索引的查找Seek+filter,效率上更高。
適應的場景:
ICP的優化策略可用於range、ref、eq_ref、ref_or_null 類型的訪問數據方法
其實沒有實例不太好理解這種優化策略,還是舉兩個實際列子吧。
ICP優化實例
第一個例子在網上非常多,也非常容易理解.具體表結構見上文(http://www.cnblogs.com/wy123/p/7366486.html)
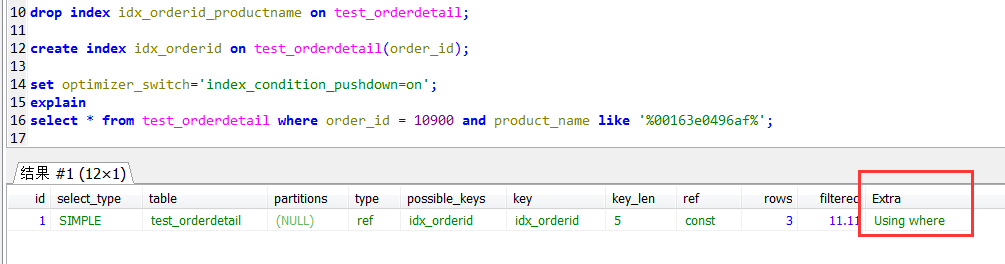
下麵用到的test_orderdetail表的索引為:create index idx_orderid_productname on test_orderdetail(order_id,product_name);
查詢語句為:select * from test_orderdetail where order_id = 10900 and product_name like '%00163e0496af%';
顯然,order_id = 10900是可以直接進行索引查找的,雖然product_name也包含在複合索引中,但是product_name like '%00163e0496af%'是無法使用索引的
觀察其執行計劃,發現Extra中是Using index condition。
ICP在這裡的優化原理就是,
在利用第一個條件 order_id = 10900 進行索引查找的過程中,同時使用product_name like '%00163e0496af%'這個無法直接使用索引查找的條件進行過濾。
最終一步就可以篩選出來結果。

對比關閉ICP優化的情況
如果關閉ICP優化,執行計劃的Extra顯示為Using where,
意味著使用order_id = 10900進行索引查找之後,再對結果集進行product_name like '%00163e0496af%'的篩選

第二個例子是後面自己想的,為了驗證ICP的出現場景,以及確實優於非ICP優化的情況
這一次使用的表是test_order,test_order上的索引為create index idx_userid_order_id_createdate on test_order(user_id,order_id,create_date);
查詢語句為:select * from test_order where user_id = 500 and create_date > '2015-1-1';
與上面的例子一樣,第二個篩選條件是無法直接使用索引的
首先看兩者的執行計劃在ICP優化上的區別

關閉ICP之後的執行計劃

然後分別執在打開與關閉ICP的情況下,觀察其執行過程中的profile信息
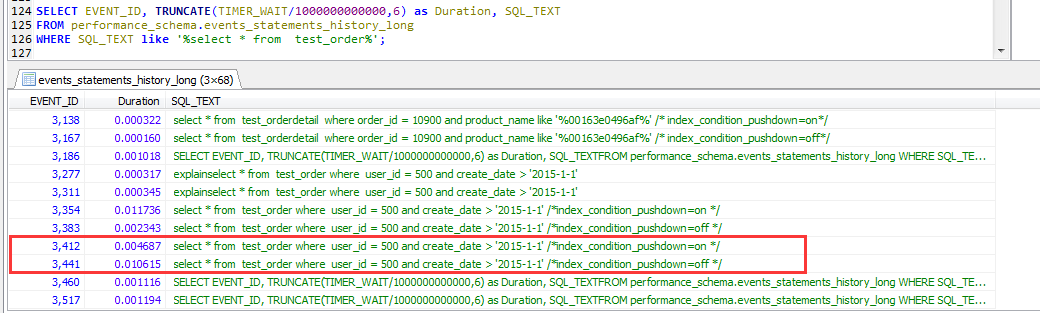
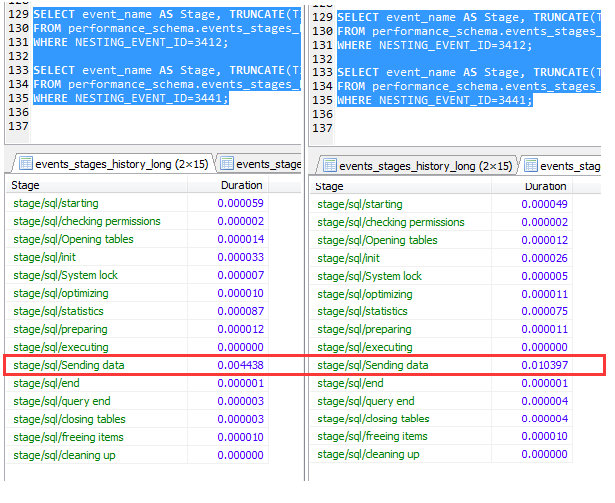
查看兩個sql執行的詳細信息,也即分別在打開與關閉ICP優化的情況下,如下,在stage/sql/Sending data環節有超過一個數量級的差異。
也就意味著通過ICP機制的優化,server 層和 engine 層之間數據交互的次數減少。
引用MySQL · 特性分析 · Index Condition Pushdown (ICP)中的一句話:
在二級索引是複合索引且前面的條件過濾性較低的情況下,打開 ICP 可以有效的降低 server 層和 engine 層之間交互的次數,從而有效的降低在運行時間。
最後,再思考一個問題,
對於select * from test_orderdetail where order_id = 10900 and product_name like '%00163e0496af%';這個查詢,
如果order_id 包含在一個二級索引中,但是product_name 沒有包含在這個二級索引中,MySQL會不會採用ICP的方式進行優化?
答案是否定的。
因為ICP的前提兩個查詢條件包被索引覆蓋,但是次選條件無法直接使用索引查找,如果次選條件沒有被索引覆蓋,是無法得知次選條件的值的,也就無從 索引條件下推優化了。
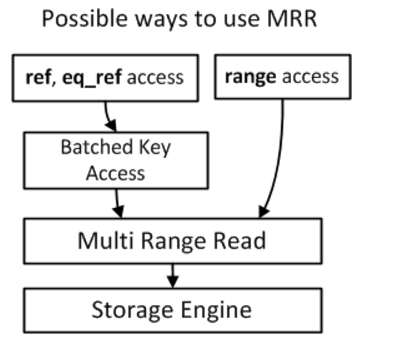
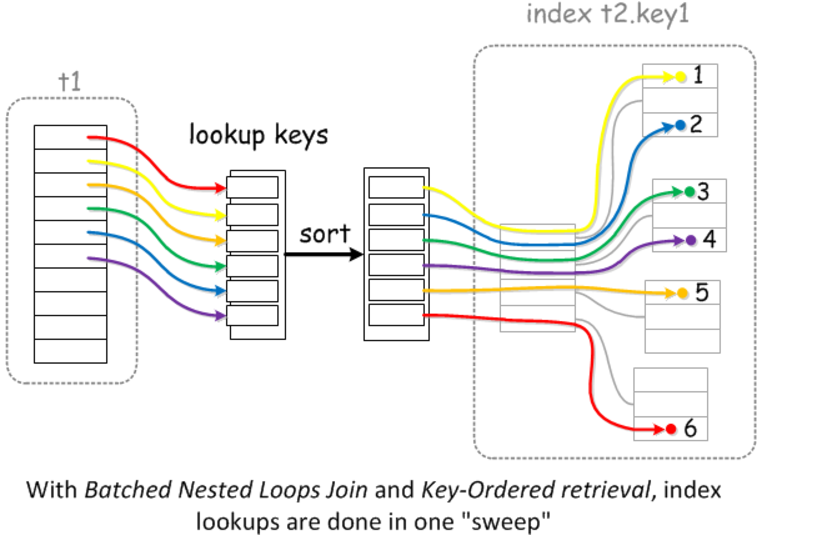
Multi-Range Read(MRR)
非MRR優化下存在的問題:
首先瞭解一點背景知識:MySQL的Innodb表都是聚集索引表,沒有顯式指定聚集索引的情況下,會自動生成一個聚集索引。
在使用二級索引(或者說是非聚集索引)進行範圍查詢的條件下,二級索引會根據其B樹結構的葉子節點存儲的聚集索引進行數據的查找(回表操作),
但是符合條件的數據(二級索引超找的數據)有可能是隨機分佈在聚集索引B樹的任何一個部分,這樣就可能存在表上過多的隨機IO。
當表非常大的時候,每一行的查找過程都需要在磁碟上隨機進行,可能會對性能造成影響。
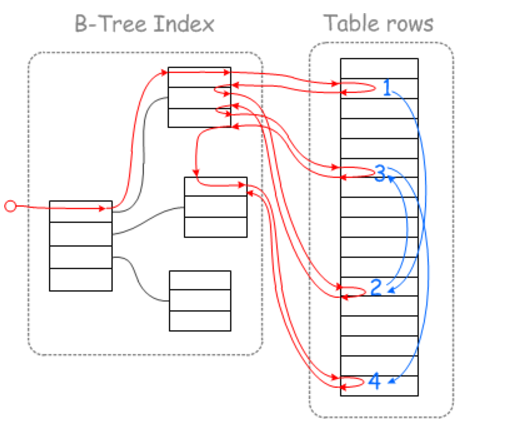
舉個例子,
如下圖,參考藍線的移動軌跡,二級索引查找到的目標數據行的物理位置為1,2,3,4(主要的是以何種順序去獲取這四個位置的數據,可以隨機的方式獲取,也可以順序的方式獲取,講究就在這一點)
在查找這四個位置的數據的時候,如果直接按照二級索引對應的聚集索引的順序查找,
由於二級索引排序的情況下,其對應的聚集索引的順序可能是隨機的,那麼其對應的數據的物理位置也就是隨機的了
如果按照二級索引的順去回表超找對應的數據行,那麼這個過程就需要隨機IO查找。
這種查詢方式的缺點,可以理解為在查詢這四行數據的過程中,在物理位置差異較大的情況下,需要磁頭來回擺臂來實現(隨機IO讀取)。
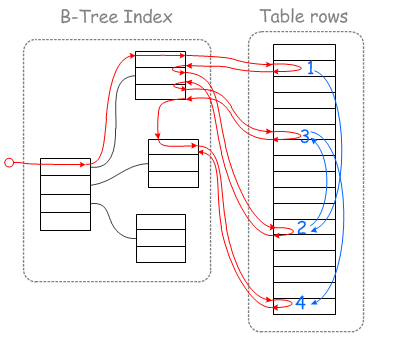
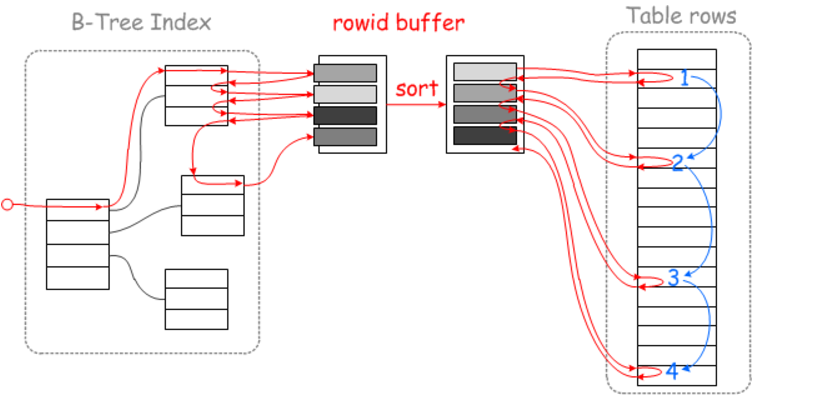
MRR多範圍讀取優化的目的是通過對記錄的讀取請求進行排序,然後再讀取數據行的時候以順序IO的方式進行,避免隨機IO
究竟是對哪個欄位排序?個人認為可以理解成二級索引範圍查找到的對應的聚集索引的key值進行排序。
有序掃描的過程可以認為是:
(1)通過非聚集索引找到目標數據的聚集索引的key值
(2)對通過二級索引找到的目標數據的聚集索引的key值排序,此時聚集索引與物理位置一一對應。
(3)(回表的過程)通過二級索引對應的有序的聚集索引,執行一個有序的磁碟掃描來獲取數據,從而來加快讀取數據的速度。
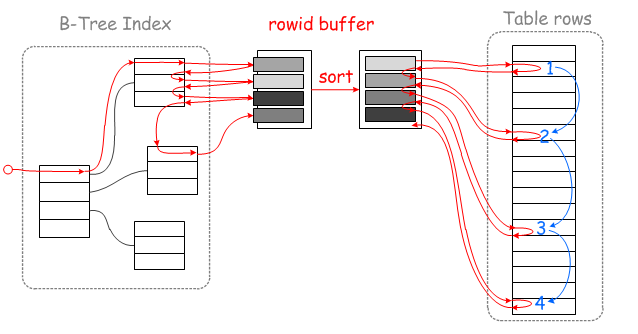
順序讀磁碟通常會更快,當然也不是說這種方式的效率總是較高的,凡事有利必有弊,也有例外的情況
1,如果掃描的是一個較小的數據範圍,並且目標數據已經在磁碟的緩存當中,MRR的唯一影響是為了緩衝/排序額外的增加了一些CPU開銷。
2,order by *** LIMIT n查詢,當n值比較小的時候,可能會變的更慢,
原因是 MRR試圖通過順序讀盤的方式(來或取數據),可能一開始讀取到的數據並非總是排在(order by ***)符合前N條的。
3,MRR是一個實現過程,個人理解,極端情況下,如果MySQL不知道目標數據的行數,
如果僅僅只有一行,依然要進行排序操作,然後回表讀取數據行,這種情況下也是得不償失的。
打開MRR優化
set global optimizer_switch = 'mrr=on,mrr_cost_based=off';
啟用MRR優化的前提是要進行書簽超找,也即要回表,如果不需要回表的話,二級索引本身就可以查詢出來需要的欄位了,沒有隨機IO的機會的所謂了。

如下截圖,如果去掉order_status,也就意味著無需回表查詢,那麼就不會出現MRR優化了。

同時,一旦出現MRR優化,查詢出來的結果的順序,必然是按照聚集索引來排序的,這個原理應該是不難理解的。
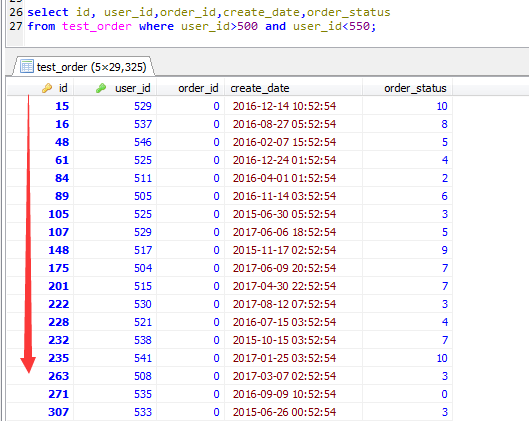
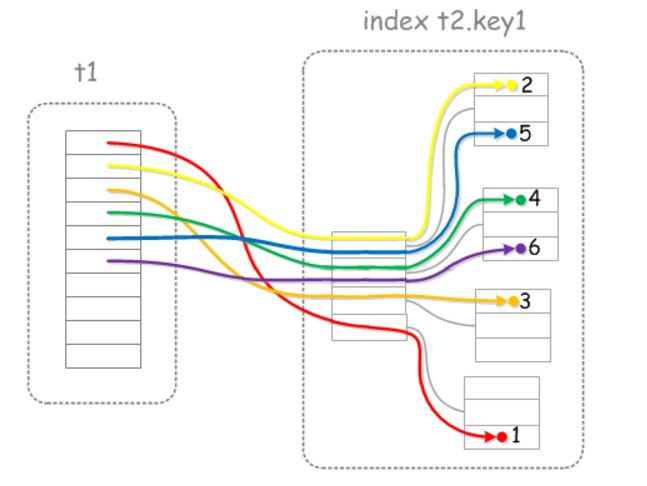
當然MRR優化也有在表關聯情況下的優化措施,原理大同小異。
總結:
Index Condition Pushdown(索引條件下推)和Multi-Range Read(多範圍讀)都是MySQL為了提高查詢優化而備用的選項,屬於MySQL5.6裡面的新特性。
無奈樓主接觸MySQL不久,見識不夠,很是覺得新鮮,高手勿噴。
兩者的共同的特點都是在使用索引超找(或者索引範圍掃描)的過程中的一些優化措施。
這些優化措施可以在二級索引查找(索引範圍掃描)的過程中優化查詢動作的行為,
當然這些優化措施並非總是萬能的,允許用戶顯式打開或者關閉,給用戶充分的自由,然而自由也並非完全沒有問題,這也要求用戶在做相關優化的時候需要進行充分的權衡和考慮。
參考:
https://mariadb.com/kb/en/mariadb/multi-range-read-optimization/
http://blog.itpub.net/22664653/viewspace-1673682/
http://blog.itpub.net/22664653/viewspace-1678779/
http://mysql.taobao.org/monthly/2015/12/08/
以及各種網上搜索……
最後,mariadb官方這幾張圖非常贊,對理解問題很有幫助,先盜下來,備用(無恥一笑,O(∩_∩)O~),
突然又想到做人了,為什麼一定要直來直去呢,很多時候是欲速則不達,迂迴一下,暫時停下來,好好計劃計劃再出發,未必是壞事。