
繼承PagingAndSortingRepository 我們可以看到,BlogRepository定義了這樣一個方法:Page<Blog> findByDeletedFalse(Pageable pageable);,我們主要關註它的參數以及返回值。 Pageable 是Spring Data庫中 ...
繼承PagingAndSortingRepository
我們可以看到,BlogRepository定義了這樣一個方法:Page<Blog> findByDeletedFalse(Pageable pageable);,我們主要關註它的參數以及返回值。
- Pageable 是Spring Data庫中定義的一個介面,該介面是所有分頁相關信息的一個抽象,通過該介面,我們可以得到和分頁相關所有信息(例如
pageNumber、pageSize等),這樣,Jpa就能夠通過pageable參數來得到一個帶分頁信息的Sql語句。 - Page類也是Spring Data提供的一個介面,該介面表示一部分數據的集合以及其相關的下一部分數據、數據總數等相關信息,通過該介面,我們可以得到數據的總體信息(數據總數、總頁數...)以及當前數據的信息(當前數據的集合、當前頁數等)
Spring Data Jpa除了會通過命名規範幫助我們擴展Sql語句外,還會幫助我們處理類型為Pageable的參數,將pageable參數轉換成為sql'語句中的條件,同時,還會幫助我們處理類型為Page的返回值,當發現返回值類型為Page,Spring Data Jpa將會把數據的整體信息、當前數據的信息,分頁的信息都放入到返回值中。這樣,我們就能夠方便的進行個性化的分頁查詢。
分頁:
package org.springdata.repository;
import org.springdata.domain.Employee;
import org.springframework.data.repository.PagingAndSortingRepository;
/**
*/
public interface EmployeePadingAndSortingResponstory extends PagingAndSortingRepository<Employee,Integer> {
}
編寫測試類
package org.springdata.crudservice;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import org.springdata.domain.Employee;
import org.springdata.repository.EmployeePadingAndSortingResponstory;
import org.springdata.service.CrudEmployeeService;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Pageable;
import java.util.List;
/**
*/
public class PagingAndSortingRespositoryTest {
private ApplicationContext ctx = null;
private EmployeePadingAndSortingResponstory employeePadingAndSortingResponstory = null;
@Before
public void setup(){
ctx = new ClassPathXmlApplicationContext("beans_news.xml");
employeePadingAndSortingResponstory = ctx.getBean(EmployeePadingAndSortingResponstory.class);
System.out.println("setup");
}
@After
public void tearDown(){
ctx = null;
System.out.println("tearDown");
}
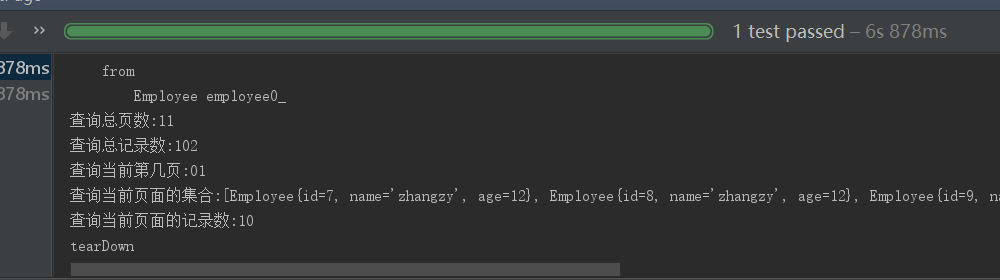
@Test
public void testPage(){
//index 1 從0開始 不是從1開始的
Pageable page = new PageRequest(0,10);
Page<Employee> employeeList = employeePadingAndSortingResponstory.findAll(page);
System.out.println("查詢總頁數:"+employeeList.getTotalPages());
System.out.println("查詢總記錄數:"+employeeList.getTotalElements());
System.out.println("查詢當前第幾頁:"+employeeList.getNumber()+1);
System.out.println("查詢當前頁面的集合:"+employeeList.getContent());
System.out.println("查詢當前頁面的記錄數:"+employeeList.getNumberOfElements());
}
}
查詢結果 咱們先在Employee 實體類 重寫下toString()方法 才能列印集合數據
排序:
基於上面的查詢集合 我們新建一個測試方法
@Test
public void testPageAndSord(){
//根據id 進行降序
Sort.Order order = new Sort.Order(Sort.Direction.DESC,"id");
Sort sort = new Sort(order);
//index 1 從0開始 不是從1開始的
Pageable page = new PageRequest(0,10,sort);
Page<Employee> employeeList = employeePadingAndSortingResponstory.findAll(page);
System.out.println("查詢總頁數:"+employeeList.getTotalPages());
System.out.println("查詢總記錄數:"+employeeList.getTotalElements());
System.out.println("查詢當前第幾頁:"+employeeList.getNumber()+1);
System.out.println("查詢當前頁面的集合:"+employeeList.getContent());
System.out.println("查詢當前頁面的記錄數:"+employeeList.getNumberOfElements());
}
 我們可以看到 最大id 排前面了
我們可以看到 最大id 排前面了

