
目錄 · 概況 · 原理 · HDFS 架構 · 塊 · NameNode · SecondaryNameNode · fsimage與edits合併 · DataNode · 數據讀寫 · 容錯機制 · 數據完整性 · NameNode HA · NameNode Federation · HDF ...
目錄
· 概況
· 原理
· HDFS 架構
· 塊
· NameNode
· DataNode
· 數據讀寫
· 容錯機制
· 數據完整性
· 操作
· API
概況
1. 文件系統抽象類FileSystem
a) 源碼
1 public abstract class FileSystem extends Configured implements Closeable { 2 // ... 3 }
b) 實現類
|
文件系統 |
URI方案 |
Java實現 |
定義 |
|
Local |
file |
org.apache.hadoop.fs.LocalFileSystem |
已使用客戶端校驗的本地文件系統。未使用校驗的本地磁碟文件系統由RawLocalFileSystem實現。 |
|
HDFS |
hdfs |
org.apache.hadoop.hdfs.DistributedFileSystem |
Hadoop分散式文件系統 |
|
HFTP |
hftp |
org.apache.hadoop.hdfs.web.HftpFileSystem |
支持通過HTTP方式以只讀方式訪問HDFS,通常和distcp命令結合使用。 |
|
HSFTP |
hsftp |
org.apache.hadoop.hdfs.web.HsftpFileSystem |
支持通過HTTPS方式以只讀方式訪問HDFS。 |
|
HAR |
har |
org.apache.hadoop.fs.HarFileSystem |
構建在Hadoop文件系統之上,對文件歸檔。Hadoop歸檔文件主要用來減少NameNode記憶體使用。 |
|
FTP |
ftp |
org.apache.hadoop.fs.ftp.FtpFileSystem |
由FTP伺服器支持的文件系統。 |
|
S3(原生) |
s3n |
org.apache.hadoop.fs.s3native.NativeS3FileSystem |
基於Amazon S3的文件系統。 |
|
S3(基於塊) |
s3 |
org.apache.hadoop.fs.s3.S3FileSystem |
基於Amazon S3的文件系統,解決S3的5GB文件大小限制。 |
2. HDFS特點
a) 適合存儲超大文件:存儲在HDFS的文件大多在GB、TB級別,甚至PB級別。
b) 運行於廉價硬體之上:設計時已考慮集群規模足夠大時,節點故障是常態。HDFS無需運行在高可靠且昂貴的伺服器,普通的PC伺服器即可。
c) 流式數據訪問:HDFS認為一次寫入、多次讀取時最高效的訪問模式。數據集生成後,會長時間在此數據集上進行各種分析,每次分析都將設計該數據集的大部分甚至全部數據。
3. HDFS缺點
a) 實時數據訪問弱:HDFS針對數據吞吐量做了優化,而犧牲了讀取效率,無法做到秒級或毫秒級響應。
b) 大量小文件:HDFS啟動時,NameNode將全部元數據載入到記憶體,而一般一個HDFS文件、目錄和數據塊的存儲信息約150位元組,因此文件個數受限於NameNode節點記憶體。過多小文件很快達到上限。
c) 多用戶寫入,任意修改文件:HDFS文件同時只能有一個寫入者,且寫操作總在文件末。
原理
HDFS 架構
1. 架構圖

2. 守護進程
|
名稱 |
集群中數目 |
作用 |
|
NameNode |
1(預設) |
存儲文件系統元數據,存儲文件與數據塊映射,並提供文件系統全景圖 |
|
SecondaryNameNode |
1 |
備份NameNode數據,並負責鏡像與NameNode日誌數據合併 |
|
DataNode |
多個(至少1個) |
存儲塊數據 |
塊
1. 文件系統塊:塊大小是磁碟塊大小的整數倍,如ext3為4KB,NTFS為4KB。
2. HDFS塊
a) HDFS文件:被劃分為塊大小的多個分塊。
b) 預設大小:64MB。
c) 較大原因:最小化定址開銷(塊足夠大,從磁碟傳輸數據塊的時間明顯大於定位塊開始位置所需的時間)。
d) 配置:hdfs-site.xml的參數“dfs.block.size”。
3. 副本
a) 含義:每個HDFS塊在集群中保存的份數,預設為3。
b) 效果:值越高,冗餘性越好,占用存儲越多。
c) 配置:hdfs-site.xml的參數“dfs.replication”。
4. 塊分佈示例
a) 環境:文件大小150MB,塊大小64MB,副本數2。
b) 分佈:第1塊64MB,第2塊64MB,第3塊22MB。
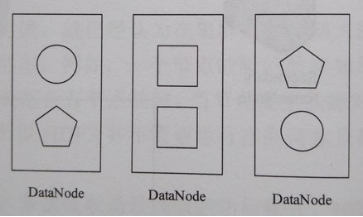
5. 塊佈局策略
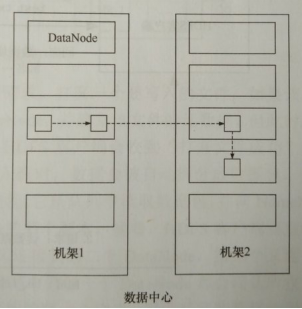
a) 第1個副本:如果HDFS客戶端在集群內,預設佈局在客戶端所在節點;否則隨機選擇一個節點,但會儘量避免存儲太滿或太忙的節點。
b) 第2個副本:與第1個副本不同且隨機另外機架中的節點。
c) 第3個副本:與第2個副本相同機架且隨機選擇另外一個節點。
d) 其他副本(副本數>3):集群隨機選擇節點,但會儘量避免在相同機架上佈局太多副本。
e) 由NameNode選擇節點。
f) 示意圖:副本數為3。
NameNode
1. 職責:HDFS主從(Master/Slave)架構的主角色。
2. NameNode存儲的文件
a) fsimage:HDFS元數據的完整快照,每次NameNode啟動時,預設載入最新的fsimage。
b) edits:fsimage的編輯日誌。
SecondaryNameNode
1. 職責:定期合併fsimage和edits的輔助守護進程。
2. 部署:生產環境一般單獨部署在一臺伺服器。
fsimage與edits合併
1. 不直接更新fsimage的原因:fsimage是一個大型文件,如果頻繁執行寫操作,會使系統運行極慢。
2. 定期合併的原因
a) 隨時間推移,edits越來越大,一旦發生故障,回滾時間非常長。
b) 如果由NameNode合併,則NameNode可能無法提供足夠資源為集群服務,所以由SecondaryNameNode合併。
3. 定期合併的過程
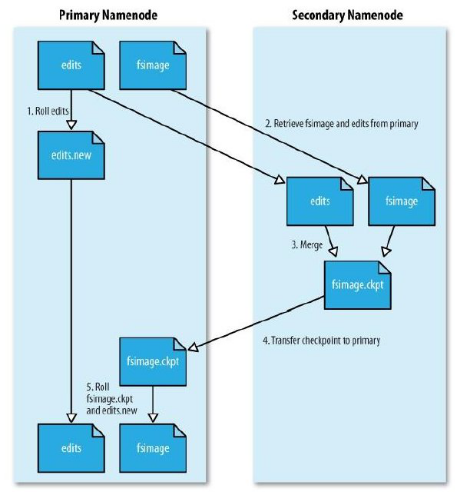
a) SecondaryNameNode通知NameNode準備提交edits文件,此時NameNode產生edits.new;
b) SecondaryNameNode通過HTTP GET方式獲取NameNode的fsimage與edits文件(在SecondaryNameNode的current同級目錄下可見 temp.check-point或者previous-checkpoint目錄,這些目錄中存儲著從NameNode拷貝來的鏡像文件);
c) SecondaryNameNode開始合併獲取的上述兩個文件,產生一個新的fsimage文件fsimage.ckpt;
d) SecondaryNameNode用HTTP POST方式發送fsimage.ckpt至NameNode;
e) NameNode將fsimage.ckpt與edits.new文件分別重命名為fsimage與edits,然後更新fstime,整個checkpoint過程結束。
4. 定期合併的預設時機
a) 每小時一次;
b) 或當NameNode edits文件達到預設的64MB時。
DataNode
1. 職責:HDFS主從(Master/Slave)架構的從角色。
2. 塊文件:每個塊都是一個文件,預設位於參數“dfs.data.dir”目錄的current目錄下,文件名blk_blkID。
3. 上報:DataNode啟動時,向NameNode上報塊信息(Block Report)。
數據讀寫
1. 文件讀取過程
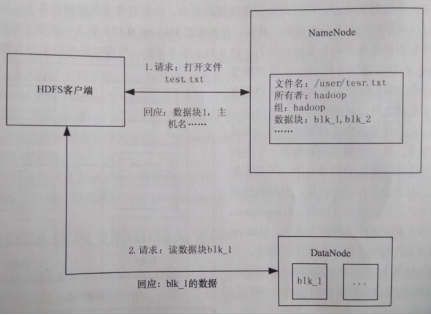
a) HDFS對客戶端身份驗證,兩種方式:通過信任的客戶端,由其指定用戶名;諸如Kerberos等強制驗證機制。
b) 客戶端告知NameNode要讀取的文件。當文件存在且用戶有訪問許可權時,NameNode告知客戶端該文件第1個塊的標號以及保存該塊的DataNode列表(按DataNode與客戶端距離排序)。
c) 客戶端直接訪問最適合的DataNode讀取塊,該過程一直重覆直到文件所有塊讀取完成或客戶端主動關閉文件流。
d) 特殊情況,客戶端是DataNode時,將從本地DataNode讀取數據。
2. 文件寫入過程
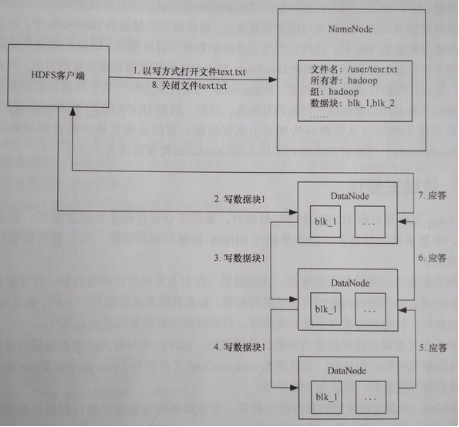
a) 客戶端發送請求,打開一個要寫入的文件。如果客戶端有寫入許可權,則請求被送達NameNode,並建立該文件的元數據,但該文件元數據未和任何資料庫關聯。
b) 客戶端收到“打開文件成功”響應後開始將數據寫入流,數據被自動拆分成數據包,並將數據包保存在記憶體隊列。
c) 客戶端一個獨立線程從隊列讀取數據包,並向NameNode請求一組DataNode列表,以便寫入下一個塊的多個副本。客戶端直接連接到列表中第1個DataNode,而該DataNode又連接到第2個DataNode,第2個又連接到第3各,如此建立塊的複製管道。各DataNode都會確認收到的數據包成功寫入磁碟。客戶端維護著一個列表,記錄由尚未收到確認信息的數據包。
d) 當塊被寫入一組DataNode後,客戶端重新向NameNode申請下一組DataNode。
e) 最終,全部數據包寫入,關閉數據管道並通知NameNode寫操作完成。
容錯機制
1. 心跳機制:當NameNode未收到DataNode心跳包時,NameNode認為該DataNode上的數據無效。新的IO操作將不會派發給該DataNode;如果塊副本數小於hdfs-site.xml的參數“dfs.replication.min”,則開始自動複製新副本到其他DataNode節點。
2. 塊完整性校驗:HDFS記錄文件所有塊的校驗和,當確認校驗和不一致時,會從其他DataNode節點獲取塊的副本。
3. 集群負載均衡:節點失效或增加可能導致數據分佈不均,當某個DataNode空閑空間大於臨界值時,HDFS自動從其他DataNode遷移數據保持平衡。
4. fsimage與edits:如果NameNode單點部署,fsimage、edits文件損壞時,可手工從SecondaryNameNode定期備份手工恢復。
5. 文件刪除:刪除並未從NameNode移除,而是存放在/trash目錄可隨時恢復,直到超過hdfs-site.xml的參數“fs.trash.interval”的值(秒)。
數據完整性
1. 寫入時校驗:客戶端將數據及其校驗和發送到一組DataNode組成複製管道,管道最後一個DataNode負責驗證校驗和,如果錯誤,客戶端便收到ChecksumException。
2. 讀取時校驗:客戶端對比讀取數據與DataNode存儲的校驗和,驗證成功後告知DataNode,DataNode記錄到驗證校驗和日誌(包括每個塊的最後驗證時間)。
3. 後臺定期校驗:每個DataNode後臺有一個DataBlockScanner線程,定期驗證Data上所有數據塊。
4. 塊修複:NameNode將塊標記為已損壞,之後安排該塊的一個副本複製到另一DataNode以達到預設副本數,最後刪除已損壞的塊。
NameNode HA
1. 場景
a) NameNode的熱備(SecondaryNameNode是NameNode的冷備)。
b) 生產環境必備功能。
2. NameNode HA架構
a) 一個NameNode處於主狀態(Active),處理客戶端和DataNode請求,並把edits寫入本地和共用編輯日誌(NFS或QJM等)。
b) 另一個NameNode處於從狀態(StandBy),啟動時載入fsimage文件,然後周期性從共用編輯日誌獲取edits,保持與主NameNode同步。
c) 為實現主節點宕機後從節點迅速提供服務,DataNode需同時向兩個NameNode彙報(Block Report)。

NameNode Federation
1. 解決問題:解決NameNode伸縮性、隔離性,以及單NameNode性能方面的問題。
2. 場景:集群規模在1000台以下時,幾乎無需NameNode Federation。

HDFS Snapshots
1. 原理:HDFS Snapshots是一個只讀的基於時間點的文件系統副本,快照可以時整個文件系統也可以是其中一部分。
2. 場景:常用來作為數據備份,防止用戶誤操作和容災。
操作
1. HDFS文件系統命令
|
命令 |
功能 |
舉例 |
|
hadoop dfs -ls <path> |
列出文件或目錄內容 |
hadoop dfs -ls / |
|
hadoop dfs -lsr <path> |
遞歸列出目錄內容 |
hadoop dfs -lsr / |
|
hadoop dfs -df <path> |
查看目錄使用情況 |
hadoop dfs -df / |
|
hadoop dfs -du <path> |
顯示目錄中所有文件及目錄的大小 |
hadoop dfs -du / |
|
hadoop dfs -dus <path> |
顯示目錄總大小 |
hadoop dfs -dus / |
|
hadoop dfs -count [-q] <path> |
顯示目錄下目錄數及文件數,格式為“目錄數 文件數 大小 文件名”,-q指查看文件索引 |
hadoop dfs -count / |
|
hadoop dfs -mv <src> <dst> |
將HDFS文件移動到目標目錄 |
hadoop dfs -mv /user/hadoop/a.txt /user/test |
|
hadoop dfs -rm [-skipTrash] <path> |
將HDFS文件移動到回收站,-skipTrash指直接刪除 |
hadoop dfs -rm /text.txt |
|
hadoop dfs -rmr [-skipTrash] <path> |
將HDFS目錄移動到回收站,-skipTrash指直接刪除 |
hadoop dfs -rmr /text |
|
hadoop dfs -expunge |
清空回收站 |
hadoop dfs -expunge |
|
hadoop dfs -put <localsrc> ... <dst> |
將本地文件上傳到HDFS目錄 |
hadoop dfs -put /home/hadoop/test.txt /user/hadoop |
|
hadoop dfs -copyFromLocal <localsrc> ... <dst> |
類似-put |
hadoop dfs -copyFromLocal /home/hadoop/test.txt /user/hadoop |
|
hadoop dfs -moveFromLocal <localsrc> ... <dst> |
將本地文件移動到HDFS目錄 |
hadoop dfs -moveFromLocal /home/hadoop/test.txt /user/hadoop |
|
hadoop dfs -get [-ignoreCrc] [-crc] <src> <localdst> |
將HDFS文件下載到本地目錄,-ignoreCrc指忽略CRC校驗失敗,-crc指下載文件及CRC信息 |
hadoop dfs -get /user/hadoop/a.txt /home/hadoop |
|
hadoop dfs -getmerge <src> <localdst> [addnl] |
將HDFS目錄下所有文件按文件名排序合併成一個文件下載到本地目錄,addnl指每個文件結尾添加一個換行符 |
hadoop dfs -getmerge /user/test /home/hadoop/o |
|
hadoop dfs -cat <src> |
瀏覽HDFS文件內容 |
hadoop dfs -cat /user/hadoop/test.txt |
|
hadoop dfs -text <src> |
以文本方式瀏覽HDFS文件 |
hadoop dfs -text /user/test.txt |
|
hadoop dfs -copyToLocal [-ignoreCrc] [-crc] <src> <localdst> |
類似-get |
hadoop dfs -copyToLocal /user/hadoop/a.txt /home/hadoop |
|
hadoop dfs -moveToLocal [-crc] <src> <localdst> |
將HDFS文件移動到本地目錄 |
hadoop dfs -moveToLocal /user/hadoop/a.txt /home/hadoop |
|
hadoop dfs -mkdir <path> |
創建HDFS目錄 |
hadoop dfs -mkdir /user/test |
|
hadoop dfs -setrep [-R] [-w] <rep> <path/file> |
設置文件副本數,-R指遞歸執行 |
hadoop dfs -setrep 5 -R /user/test |
|
hadoop dfs -touchz <path> |
創建0位元組的HDFS空文件 |
hadoop dfs -touchz /user/hadoop/test |
|
hadoop dfs -test -[ezd] <path> |
檢查HDFS文件,-e指檢查存在(存在返回0),-z指檢查0位元組(是返回0),-d指檢查目錄(是返回1,否返回0) |
hadoop dfs -test -e /user/test.txt |
|
hadoop dfs -stat [format] <path> |
顯示HDFS文件或目錄統計信息 |
hadoop dfs -stat /user/test |
|
hadoop dfs -tail [-f] <file> |
瀏覽HDFS文件最後1KB內容,-f指隨文件內容更新而更新 |
hadoop dfs -tail -f /user/test.txt |
|
hadoop dfs -chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH... |
修改HDFS文件許可權,-R指遞歸執行 |
hadoop dfs -chmod -R +r /user/test |
|
hadoop dfs -chown [-R] [OWNER][:[GROUP]] PATH... |
修改HDFS文件所屬用戶,-R指遞歸執行 |
hadoop dfs -chown -R hadoop:hadoop /user/test |
|
hadoop dfs -chgrp [-R] GROUP PATH... |
修改HDFS文件所屬組別,-R指遞歸執行 |
hadoop dfs -chgrp -R hadoop /user/test |
|
hadoop dfs -help |
顯示所有dfs命令幫助 |
hadoop dfs -help |
2. HDFS其他命令參考官方文檔。
API
1. HDFS客戶端要求:
a) 配置文件hdfs-site.xml;
b) Maven依賴
1 <dependency> 2 <groupId>org.apache.hadoop</groupId> 3 <artifactId>hadoop-client</artifactId> 4 <version>2.6.5</version> 5 </dependency>
2. 示例執行方法
hadoop jar hdfs-test.jar hdfs.ReadFile
3. 讀取文件
1 package hdfs; 2 3 import java.io.IOException; 4 import java.io.InputStream; 5 6 import org.apache.hadoop.conf.Configuration; 7 import org.apache.hadoop.fs.FileSystem; 8 import org.apache.hadoop.fs.Path; 9 import org.apache.hadoop.io.IOUtils; 10 11 public class ReadFile { 12 13 public static void main(String[] args) throws IOException { 14 String uri = "hdfs://centos1:9000/test/README.txt"; 15 Configuration conf = new Configuration(); 16 17 FileSystem fs = null; 18 InputStream in = null; 19 try { 20 fs = FileSystem.get(conf); 21 in = fs.open(new Path(uri)); 22 IOUtils.copyBytes(in, System.out, 4096, false); 23 } finally { 24 IOUtils.closeStream(in); 25 if (fs != null) { 26 fs.close(); 27 } 28 } 29 } 30 31 }
4. 寫入文件
1 package hdfs; 2 3 import java.io.BufferedInputStream; 4 import java.io.FileInputStream; 5 import java.io.IOException; 6 import java.io.InputStream; 7 import java.io.OutputStream; 8 9 import org.apache.hadoop.conf.Configuration; 10 import org.apache.hadoop.fs.FileSystem; 11 import org.apache.hadoop.fs.Path; 12 import org.apache.hadoop.io.IOUtils; 13 14 public class WriteFile { 15 16 public static void main(String[] args) throws IOException { 17 String source = "/opt/app/hadoop-2.6.5/NOTICE.txt"; 18 String destination = "hdfs://centos1:9000/test/NOTICE.txt"; 19 Configuration conf = new Configuration(); 20 21 InputStream in = null; 22 FileSystem fs = null; 23 OutputStream out = null; 24 try { 25 in = new BufferedInputStream(new FileInputStream(source)); 26 fs = FileSystem.get(conf); 27 out = fs.create(new Path(destination)); 28 IOUtils.copyBytes(in, out, 4096, true); 29 } finally { 30 IOUtils.closeStream(out); 31 if (fs != null) { 32 fs.close(); 33 } 34 IOUtils.closeStream(in); 35 } 36 } 37 38 }
5. 創建目錄
1 package hdfs; 2 3 import java.io.IOException; 4 5 import org.apache.hadoop.conf.Configuration; 6 import org.apache.hadoop.fs.FileSystem; 7 import org.apache.hadoop.fs.Path; 8 9 public class CreateDirectory { 10 11 public static void main(String[] args) throws IOException { 12 String uri = "hdfs://centos1:9000/test/testdir"; 13 Configuration conf = new Configuration(); 14 15 FileSystem fs = null; 16 try { 17 fs = FileSystem.get(conf); 18 Path dir = new Path(uri); 19 fs.mkdirs(dir); 20 } finally { 21 if (fs != null) { 22 fs.close(); 23 } 24 } 25 } 26 27 }
6. 刪除目錄
1 package hdfs; 2 3 import java.io.IOException; 4 5 import org.apache.hadoop.conf.Configuration; 6 import org.apache.hadoop.fs.FileSystem; 7 import org.apache.hadoop.fs.Path; 8 9 public class RemoveDirectory { 10 11 public static void main(String[] args) throws IOException { 12 String uri = "hdfs://centos1:9000/test/testdir"; 13 Configuration conf = new Configuration(); 14 15 FileSystem fs = null; 16 try { 17 fs = FileSystem.get(conf); 18 Path dir = new Path(uri); 19 boolean deleted = fs.delete(dir, true); // 遞歸刪除,也可刪除文件 20 System.out.println(deleted); 21 } finally { 22 if (fs != null) { 23 fs.close(); 24 } 25 } 26 } 27 28 }
7. 檢查文件存在
1 package hdfs; 2 3 import java.io.IOException; 4 5 import org.apache.hadoop.conf.Configuration; 6 import org.apache.hadoop.fs.FileSystem; 7 import org.apache.hadoop.fs.Path; 8 9 public class CheckFileExistence { 10 11 public static void main(String[] args) throws IOException { 12 String uri = "hdfs://centos1:9000/test/NOTICE.txt"; 13 Configuration conf = new Configuration(); 14 15 FileSystem fs = null; 16 try { 17 fs = FileSystem.get(conf); 18 Path file = new Path(uri); 19 boolean exists = fs.exists(file); 20 System.out.println(exists); 21 } finally { 22 if (fs != null) { 23 fs.close(); 24 } 25 } 26 } 27 28 }
8. 列出子目錄和文件
1 package hdfs; 2 3 import java.io.IOException; 4 5 import org.apache.hadoop.conf.Configuration; 6 import org.apache.hadoop.fs.FileStatus; 7 import org.apache.hadoop.fs.FileSystem; 8 import org.apache.hadoop.fs.Path; 9 10 public class ListFiles { 11 12 public static void main(String[] args) throws IOException { 13 String uri = "hdfs://centos1:9000/test"; 14 Configuration conf = new Configuration(); 15 16 FileSystem fs = null; 17 try { 18 fs = FileSystem.get(conf); 19 Path dir = new Path(uri); 20 FileStatus[] files = fs.listStatus(dir); 21 for (FileStatus file : files) { 22 System.out.println(file.getPath()); 23 } 24 } finally { 25 if (fs != null) { 26 fs.close(); 27 } 28 } 29 } 30 31 }
9. 獲取塊位置信息
1 package hdfs; 2 3 import java.io.IOException; 4 5 import org.apache.commons.lang.StringUtils; 6 import org.apache.hadoop.conf.Configuration; 7 import org.apache.hadoop.fs.BlockLocation; 8 import org.apache.hadoop.fs.FileStatus; 9 import org.apache.hadoop.fs.FileSystem; 10 import org.apache.hadoop.fs.Path; 11 12 public class ObtainFileInfo { 13 14 public static void main(String[] args) throws IOException { 15 String uri = "hdfs://centos1:9000/test/NOTICE.txt"; 16 Configuration conf = new Configuration(); 17 18 FileSystem fs = null; 19 try { 20 fs = FileSystem.get(conf); 21 Path file = new Path(uri); 22 FileStatus fileStatus = fs.getFileStatus(file); 23 BlockLocation[] blockLocations = fs.getFileBlockLocations(fileStatus, 0, fileStatus.getLen()); 24 for (int index = 0, length = blockLocations.length; index < length; index++) { 25 System.out.println("block" + index + " " + StringUtils.join(blockLocations[index].getHosts(), ",")); 26 } 27 } finally { 28 if (fs != null) { 29 fs.close(); 30 } 31 } 32 } 33 34 }

