
目錄 · 概況 · 原理 · MapReduce編程模型 · MapReduce過程 · 容錯機制 · API · 概況 · WordCount示例 · Writable介面 · Mapper類 · Reducer類 · Partitioner抽象類 · WritableComparator介面 · ...
目錄
· 概況
· 原理
· 容錯機制
· API
· 概況
· Mapper類
· Reducer類
· 示例:連接
· 示例:二次排序
概況
1. 起源:一篇Google論文。
2. 特點
a) 開發簡單:用戶可不考慮進程通信、套接字編程,無需高深技巧,只需符合MapReduce編程模型。
b) 伸縮性:當集群資源無法滿足計算需求時,可通過增加節點達到線性伸縮集群的目的。
c) 容錯性:節點故障導致的作業失敗,計算框架自動將作業安排到健康節點重新執行,直到任務完成。
3. MapReduce含義:MapReduce編程模型;MapReduce運行環境(YARN)。
4. 局限性
a) 執行速度慢:普通MapReduce作業一般分鐘級別完成,複雜作業或數據量更大時可能花費一小時或更多。MapReduce通常時數據密集型作業,大量中間結果寫到磁碟並通過網路傳輸,消耗大量時間。
b) 過於底層:與SQL相比,過於底層。對於習慣關係資料庫的用戶,或數據分析師,編寫map和reduce函數無疑頭疼。
c) 無法實現所有演算法。
原理
MapReduce編程模型
1. Map與Reduce起源:LISP和其他函數式編程語言中的古老映射和化簡操作。
2. MapReduce操作數據最小單位:鍵值對。
3. MapReduce模型執行過程
(Key1, Value1) → (Key1, List<Value2>) → (Key3, Value3)
a) 將數據抽象為鍵值對形式作為map函數輸入;
b) 經過map函數處理,生成一系列新鍵值對作為中間結果輸出到本地;
c) 計算框架自動將中間結果按鍵聚合,並將鍵相同的數據分發到reduce函數,以鍵和對應指的集合作為reduce函數輸入;
d) 經過reduce函數處理,生成一系列鍵值對作為最終輸出。
4. WordCount舉例
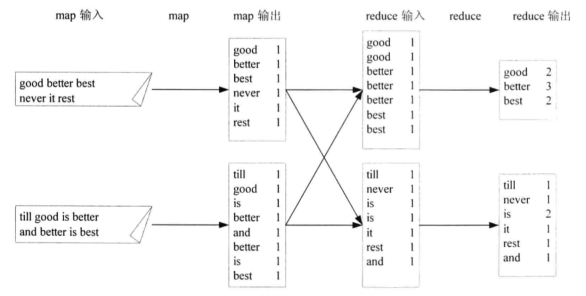
MapReduce過程
1. 過程描述:input、map、combine、reduce和output五個階段,其中combine階段不一定發生,map函數輸出的中間結果被被分發到reduce函數的過程稱為shuffle,shuffle階段還會發生copy和sort。

1. Map與Reduce任務:一個作業被分成Map和Reduce計算兩個階段,分別由一個或多個Map任務和Reduce任務組成。
2. input階段
a) input過程:如果使用HDFS上文件作為MapReduce輸入,計算框架以“org.apache.hadoop.mapreduce.InputFormat”抽象類的子類“org.apache.hadoop.mapreduce.lib.input.FileInputFormat”作為該文件的InputSplit,每個InputSplit作為一個Map任務的輸入,再將InputSplit解析成鍵值對。
b) InputSplit對數據影響:InputSplit只在邏輯上對數據切分,不影響磁碟上存儲的文件。
c) InputSplit包含信息:分片的元數據信息,包括起始位置、長度和所在節點列表等。
1 package org.apache.hadoop.mapreduce.lib.input; 2 3 // ... 4 5 public class FileSplit extends InputSplit implements Writable { 6 7 // ... 8 9 /** Constructs a split with host information 10 * 11 * @param file the file name 12 * @param start the position of the first byte in the file to process 13 * @param length the number of bytes in the file to process 14 * @param hosts the list of hosts containing the block, possibly null 15 */ 16 public FileSplit(Path file, long start, long length, String[] hosts) { 17 this.file = file; 18 this.start = start; 19 this.length = length; 20 this.hosts = hosts; 21 } 22 23 // ... 24 }
d) InputSplit大小計算:minSize取自mapred-site.xml參數“mapreduce.input.fileinputformat.split.minsize”,預設1;maxSize取自mapred-site.xml參數“mapreduce.input.fileinputformat.split.maxsize”,預設Long.MAX_VALUE;blockSize取自hdfs-site.xml參數“dfs.block.size”。所以,使用預設配置時,InputSplit大小為塊大小。
1 package org.apache.hadoop.mapreduce.lib.input; 2 3 // ... 4 5 public abstract class FileInputFormat<K, V> extends InputFormat<K, V> { 6 7 // ... 8 9 protected long computeSplitSize(long blockSize, long minSize, 10 long maxSize) { 11 return Math.max(minSize, Math.min(maxSize, blockSize)); 12 } 13 14 // ... 15 }
e) input數量計算:文件大小÷InputSplit大小。
f) 對齊:任務調度時,優先考慮本節點的數據,如果本節點沒有可處理的數據或還需其他節點數據,Map任務所在節點會從其他節點將數據網路傳輸給自己。當InputSplit大小大於塊大小時,Map任務會從其他節點讀取一部分數據,就無法實現完全數據本地化,所以InputSplit大小應等於塊大小。
g) map函數輸入:通過InputFormat.createRecordReader()方法將InputSplit解析為鍵值對。
1 package org.apache.hadoop.mapreduce.lib.input; 2 3 // ... 4 5 public class TextInputFormat extends FileInputFormat<LongWritable, Text> { 6 7 // ... 8 9 @Override 10 public RecordReader<LongWritable, Text> 11 createRecordReader(InputSplit split, 12 TaskAttemptContext context) { 13 String delimiter = context.getConfiguration().get( 14 "textinputformat.record.delimiter"); 15 byte[] recordDelimiterBytes = null; 16 if (null != delimiter) 17 recordDelimiterBytes = delimiter.getBytes(Charsets.UTF_8); 18 return new LineRecordReader(recordDelimiterBytes); 19 } 20 21 // ... 22 }
4. map階段
a) 寫緩衝區:map函數輸出時,先寫到記憶體環形緩衝區,並做一次預排序;每個Map任務都有一個環形緩衝區,大小取自mapred-site.xml參數“mapreduce.task.io.sort.mb”,預設100MB。
b) 緩衝區溢寫磁碟:當環形緩衝區達到閥值(mapred-site.xml參數“mapreduce.map.sort.spill.percent”,預設0.80)時,一個後臺線程將緩衝區內容溢寫(spill)到磁碟mapred-site.xml參數“mapreduce.cluster.local.dir”指定的目錄,預設${hadoop.tmp.dir}/mapred/local。
c) 溢寫磁碟前排序:溢寫磁碟前,線程根據數據要傳送的Reducer對緩衝區數據分區(預設按鍵),每個分區內再按鍵排序。
d) Combiner:當已指定Combiner且溢寫次數至少3次時,在溢寫磁碟前執行Combiner;效果是對map函數輸出的中間結果進行一次合併,作用與reduce函數一樣;目的是降低中間結果數據量(中間結果要寫磁碟且通過網路傳至Reducer),提升運行效率。
e) 壓縮:對中間結果壓縮,目的與Combiner相同;mapred-site.xml參數“mapreduce.map.output.compress”,預設false,參數“mapreduce.map.output.compress.codec”。
|
壓縮格式 |
演算法 |
文件擴展名 |
可切分 |
codec類 |
說明 |
|
Deflate |
Deflate |
.deflate |
否 |
org.apache.hadoop.io.compress.DeflateCodec |
|
|
gzip |
Deflate |
.gz |
否 |
org.apache.hadoop.io.compress.GzipCodec |
|
|
bzip2 |
bzip2 |
.bz2 |
是 |
org.apache.hadoop.io.compress.BZip2Codec |
|
|
LZO |
LZOP |
.lzo |
否 |
com.hadoop.compression.lzo.LzopCodec |
|
|
Snappy |
Snappy |
.snappy |
否 |
org.apache.hadoop.io.compress.SnappyCodec |
高壓縮、高速,推薦 |
f) 中間結果傳輸:中間結果通過HTTP方式傳至Reducer,傳輸工作線程數配置mapred-site.xml參數“mapreduce.tasktracker.http.threads”,預設40。
5. shuffle階段
a) copy:一個Reduce任務可能需多個Map任務輸出,而每個Map任務完成時間很可能不同,當只要有一個Map任務完成,Reduce任務即開始複製其輸出;複製線程數配置mapred-site.xml參數“mapreduce.reduce.shuffle.parallelcopies”,預設5。
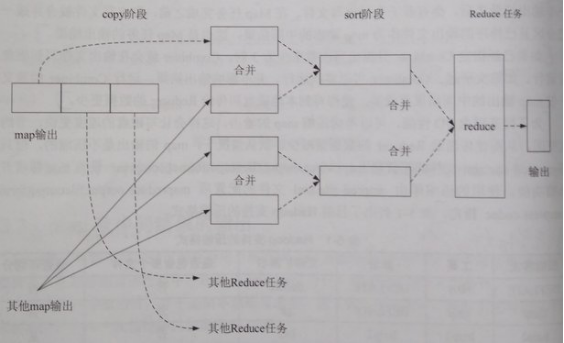
b) copy的緩衝區:如果map輸出相當小,數據先被覆制到Reducer所在節點的記憶體緩衝區(大小配置mapred-site.xml參數“mapreduce.reduce.shuffle.input.buffer.percent”,預設0.70),當記憶體緩衝區大小達到閥值(mapred-site.xml參數“mapreduce.reduce.shuffle.merge.percent”,預設0.66)或記憶體緩衝區文件數達到閥值(mapred-site.xml參數“mapreduce.reduce.merge.inmem.threshold”,預設1000)時,則合併後溢寫磁碟。否則,map輸出被覆制到磁碟。
c) copy的合併:隨複製到磁碟的文件增多,後臺線程將其合併為更大、有序的文件,為後續合併節約時間。合併時,壓縮的中間結果將在記憶體中解壓縮。
d) sort:複製完成所有map輸出後,合併map輸出文件並歸併排序。
e) sort的合併:將map輸出文件合併,直至≤合併因數(mapred-site.xml參數“mapreduce.task.io.sort.factor”,預設10)。例如,有50個map輸出文件,進行5次合併,每次將10各文件合併成一個文件,最後5個文件。
6. reduce階段
a) reduce函數輸入:經過shuffle的文件都是按鍵分區且有序,相同分區的文件調用一次reduce函數。
b) reduce函數輸出:一般為HDFS。
7. 排序
a) MapReduce中的排序演算法:快速排序、歸併排序。
b) MapReduce發生的3次排序:map階段的緩衝區排序(快速排序演算法);map階段溢寫磁碟前,對溢寫文件合併時的排序(歸併排序演算法);shuffle階段的文件合併sort(歸併排序演算法)。
容錯機制
1. 任務錯誤:對錯誤任務不斷重試,直到總嘗試次數超過N次認為徹底失敗;Map任務、Reduce任務總嘗試次數分別為mapred-site.xml參數“mapreduce.map.maxattempts”和“mapreduce.reduce.maxattempts”,預設均為4。
2. ApplicationMaster錯誤:通過YARN容錯機制完成。
3. NodeManager錯誤:通過YARN容錯機制完成。
4. ResourceManager錯誤:通過YARN容錯機制完成。
API
概況
1. 新舊API
a) 舊API包:org.apache.hadoop.mapred
b) 新API包:org.apache.hadoop.mapreduce
2. Maven依賴
1 <dependency> 2 <groupId>org.apache.hadoop</groupId> 3 <artifactId>hadoop-client</artifactId> 4 <version>2.6.5</version> 5 </dependency>
WordCount示例
1. Mapper類
1 package mr.wordcount; 2 3 import java.io.IOException; 4 import java.util.StringTokenizer; 5 import org.apache.hadoop.io.IntWritable; 6 import org.apache.hadoop.io.LongWritable; 7 import org.apache.hadoop.io.Text; 8 import org.apache.hadoop.mapreduce.Mapper; 9 10 public class TokenizerMapper extends Mapper<LongWritable, Text, Text, IntWritable> { 11 12 private final static IntWritable one = new IntWritable(1); 13 14 private Text word = new Text(); 15 16 @Override 17 protected void map(LongWritable key, Text value, 18 Mapper<LongWritable, Text, Text, IntWritable>.Context context) 19 throws IOException, InterruptedException { 20 StringTokenizer stringTokenizer = new StringTokenizer(value.toString()); 21 while (stringTokenizer.hasMoreTokens()) { 22 word.set(stringTokenizer.nextToken()); 23 context.write(word, one); 24 } 25 } 26 27 }
2. Reducer類
1 package mr.wordcount; 2 3 import java.io.IOException; 4 import org.apache.hadoop.io.IntWritable; 5 import org.apache.hadoop.io.Text; 6 import org.apache.hadoop.mapreduce.Reducer; 7 8 public class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> { 9 10 private IntWritable result = new IntWritable(); 11 12 @Override 13 protected void reduce(Text key, Iterable<IntWritable> values, 14 Reducer<Text, IntWritable, Text, IntWritable>.Context context) 15 throws IOException, InterruptedException { 16 int sum = 0; 17 for (IntWritable value : values) { 18 sum += value.get(); 19 } 20 result.set(sum); 21 context.write(key, result); 22 } 23 24 }
3. main方法
1 package mr.wordcount; 2 3 import org.apache.hadoop.conf.Configuration; 4 import org.apache.hadoop.fs.Path; 5 import org.apache.hadoop.io.IntWritable; 6 import org.apache.hadoop.io.Text; 7 import org.apache.hadoop.mapreduce.Job; 8 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 9 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 10 11 public class WordCount { 12 13 public static void main(String[] args) throws Exception { 14 if (args.length != 2) { 15 System.err.println("Usage: wordcount <in> <out>"); 16 System.exit(2); 17 } 18 19 Configuration conf = new Configuration(); 20 Job job = Job.getInstance(conf, "WordCount"); 21 job.setJarByClass(WordCount.class); 22 job.setMapperClass(TokenizerMapper.class); 23 job.setCombinerClass(IntSumReducer.class); 24 job.setReducerClass(IntSumReducer.class); 25 job.setOutputKeyClass(Text.class); 26 job.setOutputValueClass(IntWritable.class); 27 FileInputFormat.addInputPath(job, new Path(args[0])); 28 FileOutputFormat.setOutputPath(job, new Path(args[1])); 29 System.exit(job.waitForCompletion(true) ? 0 : 1); 30 } 31 32 }
4. 執行命令
hadoop jar wordcount.jar mr.wordcount.WordCount /test/wordcount/in /test/wordcount/out hadoop fs -ls /test/wordcount/out hadoop fs -cat /test/wordcount/out/part-r-00000
Writable介面
1. 職責:Hadoop序列化格式。
2. Hadoop序列化場景:IPC(進程間通信)、數據持久化。
3. 源碼(2個重要方法)
1 package org.apache.hadoop.io; 2 3 // ... 4 5 public interface Writable { 6 /** 7 * Serialize the fields of this object to <code>out</code>. 8 * 9 * @param out <code>DataOuput</code> to serialize this object into. 10 * @throws IOException 11 */ 12 void write(DataOutput out) throws IOException; 13 14 /** 15 * Deserialize the fields of this object from <code>in</code>. 16 * 17 * <p>For efficiency, implementations should attempt to re-use storage in the 18 * existing object where possible.</p> 19 * 20 * @param in <code>DataInput</code> to deseriablize this object from. 21 * @throws IOException 22 */ 23 void readFields(DataInput in) throws IOException; 24 }
4. 內置實現類
a) 包:org.apache.hadoop.io。
b) 類圖
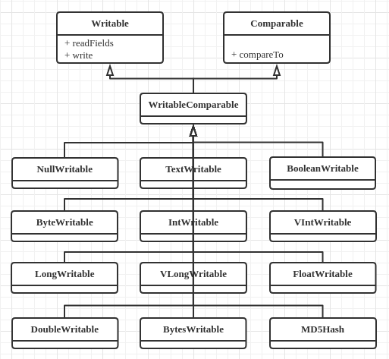
c) 與Java類型對照
|
Java類型 |
Writable實現 |
備註 |
|
null |
NullWritable |
序列化長度為0,充當占位符 |
|
String |
Text |
|
|
boolean |
BooleanWritable |
|
|
byte |
ByteWritable |
|
|
int |
IntWritable、VIntWritable |
V開頭表示變長,否則定長 |
|
long |
LongWritable、VLongWritable |
V開頭表示變長,否則定長 |
|
float |
FloatWritable |
|
|
double |
DoubleWritable |
5. 自定義實現類
1 import java.io.DataInput; 2 import java.io.DataOutput; 3 import java.io.IOException; 4 import org.apache.hadoop.io.Text; 5 import org.apache.hadoop.io.WritableComparable; 6 7 public class TextPair implements WritableComparable<TextPair> { 8 9 private Text first; 10 11 private Text second; 12 13 public TextPair() { 14 this(new Text(), new Text()); 15 } 16 17 public TextPair(Text first, Text second) { 18 this.first = first; 19 this.second = second; 20 } 21 22 public void write(DataOutput out) throws IOException { 23 first.write(out); 24 second.write(out); 25 } 26 27 public void readFields(DataInput in) throws IOException { 28 first.readFields(in); 29 second.readFields(in); 30 } 31 32 // 用於MapReduce過程中的排序 33 public int compareTo(TextPair o) { 34 int result = first.compareTo(o.first); 35 if (result == 0) { 36 result = second.compareTo(o.second); 37 } 38 return result; 39 } 40 41 public Text getFirst() { 42 return first; 43 } 44 45 public void setFirst(Text first) { 46 this.first = first; 47 } 48 49 public Text getSecond() { 50 return second; 51 } 52 53 public void setSecond(Text second) { 54 this.second = second; 55 } 56 57 }
Mapper類
1. 源碼(4個重要方法)
1 package org.apache.hadoop.mapreduce; 2 3 // ... 4 5 public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> { 6 7 /** 8 * The <code>Context</code> passed on to the {@link Mapper} implementations. 9 */ 10 public abstract class Context 11 implements MapContext<KEYIN,VALUEIN,KEYOUT,VALUEOUT> { 12 } 13 14 /** 15 * Called once at the beginning of the task. 16 */ 17 protected void setup(Context context 18 ) throws IOException, InterruptedException { 19 // NOTHING 20 } 21 22 /** 23 * Called once for each key/value pair in the input split. Most applications 24 * should override this, but the default is the identity function. 25 */ 26 @SuppressWarnings("unchecked") 27 protected void map(KEYIN key, VALUEIN value, 28 Context context) throws IOException, InterruptedException { 29 context.write((KEYOUT) key, (VALUEOUT) value); 30 } 31 32 /** 33 * Called once at the end of the task. 34 */ 35 protected void cleanup(Context context 36 ) throws IOException, InterruptedException { 37 // NOTHING 38 } 39 40 /** 41 * Expert users can override this method for more complete control over the 42 * execution of the Mapper. 43 * @param context 44 * @throws IOException 45 */ 46 public void run(Context context) throws IOException, InterruptedException { 47 setup(context); 48 try { 49 while (context.nextKeyValue()) { 50 map(context.getCurrentKey(), context.getCurrentValue(), context); 51 } 52 } finally { 53 cleanup(context); 54 } 55 } 56 }