
前言 因為比賽的限制是使用Hadoop2.7.2,估在此文章下麵的也是使用Hadoop2.7.2,具體下載地址為 "Hadoop2.7.2" 開始的準備 目前在我的實驗室上有三台Linux主機,因為需要參加一個關於spark數據分析的比賽,所以眼見那幾台伺服器沒有人用,我們團隊就拿來配置成集群。具體 ...
前言
因為比賽的限制是使用Hadoop2.7.2,估在此文章下麵的也是使用Hadoop2.7.2,具體下載地址為Hadoop2.7.2
開始的準備
目前在我的實驗室上有三台Linux主機,因為需要參加一個關於spark數據分析的比賽,所以眼見那幾台伺服器沒有人用,我們團隊就拿來配置成集群。具體打算配置如下的集群
| 主機名 | IP地址(內網) |
|---|---|
| SparkMaster | 10.21.32.106 |
| SparkWorker1 | 10.21.32.109 |
| SparkWorker2 | 10.21.32.112 |
首先進行的是ssh免密碼登錄的操作
具體操作在上一篇學習日記當中已經寫到了,在此不再詳細說。
配置Java環境
因為我那三臺電腦也是配置好了JDK了,所以在此也不詳細說。
配置好Java的機子可以使用
java -version來查看Java的版本
下載Hadoop2.7.2
因為我最後的文件是放在/usr/local下麵的,所以我也直接打開/usr/local文件夾下。直接
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.7.2/hadoop-2.7.2.tar.gz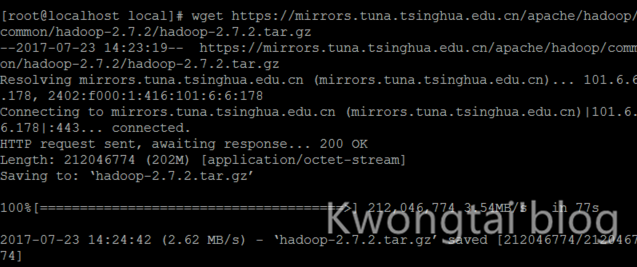
安裝Hadoop以及配置Hadoop環境
解壓
tar -zxvf hadoop-2.7.2.tar.gz刪除
rm -rf hadoop-2.7.2.tar.gz解壓刪除之後打開hadoop-2.7.2文件夾,在etc/hadoop/hadoop-env.sh中配置JDK的信息
先查看本機的jdk目錄地址在哪裡
echo $JAVA_HOME
vi etc/hadoop/hadoop-env.sh將
export JAVA_HOME=${JAVA_HOME}改為
export JAVA_HOME=/usr/java/jdk1.8.0_131
為了方便我們以後開機之後可以立刻使用到Hadoop的bin目錄下的相關命令,可以把hadoop文件夾下的bin和sbin目錄配置到/etc/profile文件中。
vi /etc/profile添加
export PATH=$PATH:/usr/local/hadoop-2.7.2/bin:/usr/local/hadoop-2.7.7/sbin按一下esc,按著shift+兩次z鍵保存
使用
source /etc/profile
使得命令配置信息生效,是否生效可以通過
hadoop version查看
配置Hadoop分散式集群
前言
考慮是為了建立
spark集群,所以主機命名為SparkMasterSparkWorker1SparkWorker2
修改主機名
vi /etc/hostname修改裡面的名字為SprakMaster,按一下esc,按著shift+兩次z鍵保存。

設置hosts文件使得主機名和IP地址對應關係
vi /etc/hosts
配置主機名和IP地址的對應關係。

Ps:其他兩台slave的主機也修改對應的SparkWorker1 SparkWorker2,如果修改完主機名字之後戶籍的名字沒有生效,那麼重啟系統便可以。三台機子的hostname與hosts均要修改

在==三台==機子的總的hadoop-2.7.2文件夾下建立如下四個文件夾
- 目錄/tmp,用來存儲臨時生成的文件
- 目錄/hdfs,用來存儲集群數據
- 目錄hdfs/data,用來存儲真正的數據
- 目錄hdfs/name,用來存儲文件系統元數據
mkdir tmp hdfs hdfs/data hdfs/name配置hadoop文件
在此先修改SparkMaster的配置文件,然後修改完畢後通過
rsync命令複製到其他節點電腦上。
修改core-site.xml
vi etc/hadoop/core-site.xml具體修改如下:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://SparkMaster:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop-2.7.2/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>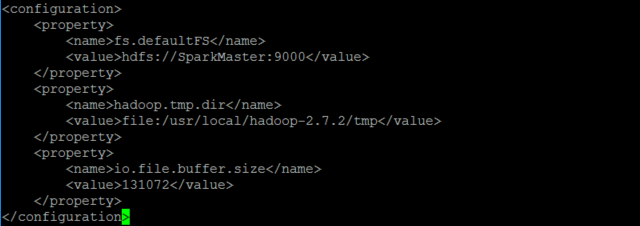
變數fs.defaultFS保存了NameNode的位置,HDFS和MapReduce組件都需要它。這就是它出現在core-site.xml文件中而不是hdfs-site.xml文件中的原因。
修改marpred-site.xml
具體修改如下
首先我們需要的是將marpred-site.xml複製一份:
cp etc/hadoop/marpred-site.xml.template etc/hadoop/marpred-site.xmlvi etc/hadoop/marpred-site.xml.template 此處修改的是
marpred-site.xml,不是marpred-site.xml.template。
具體修改如下
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>SparkMaster:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>SparkMaster:19888</value>
</property>
</configuration>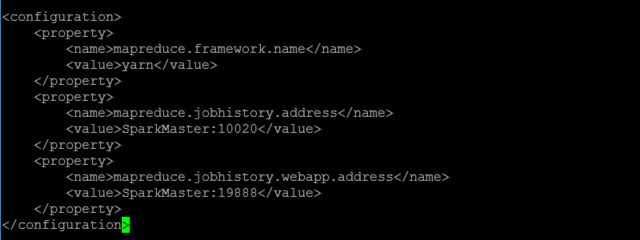
修改hdfs-site.xml
vi etc/hadoop/hdfs-site.xml具體修改如下
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop-2.7.2/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop-2.7.2/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>SparkMaster:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>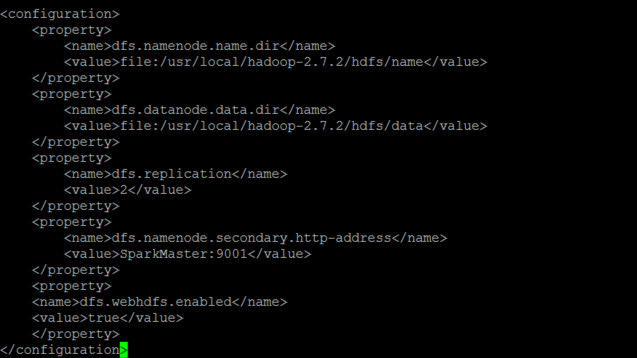
PS:變數dfs.replication指定了每個HDFS數據塊的複製次數,即HDFS存儲文件的副本個數.我的實驗環境只有一臺Master和兩台Worker(DataNode),所以修改為2。
配置yarn-site.xml
vi etc/hadoop/yarn-site.xml
具體配置如下:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>SparkMaster:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>SparkMaster:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>SparkMaster:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>SparkMaster:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>SparkMaster:8088</value>
</property>
</configuration>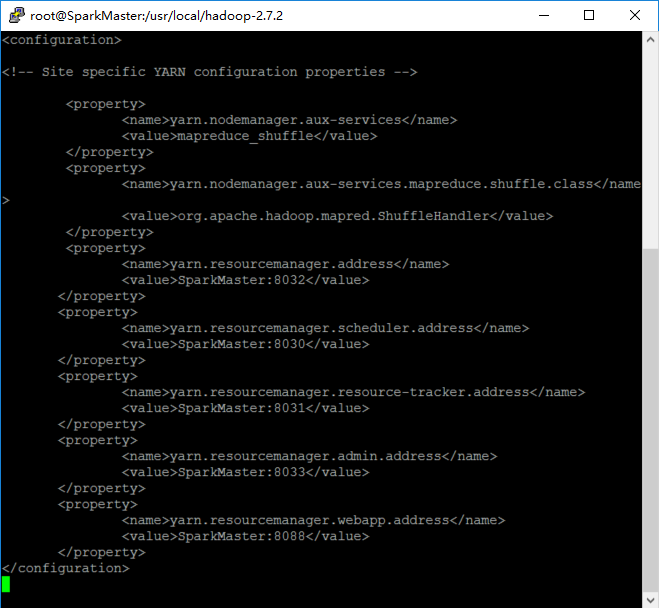
修改slaves的內容
將localhost修改成為SparkWorker1、SparkWorker2

將SparkMaster節點的`hadoop-2.7.2/etc/下麵的文件通過以下方式放去其他節點
rsync -av /usr/local/hadoop-2.7.2/etc/ SparkWorker1:/usr/local/hadoop-2.7.2/etc/rsync -av /usr/local/hadoop-2.7.2/etc/ SparkWorker1:/usr/local/hadoop-2.7.2/etc/完成之後可以查看SparkWorker1、SparkWorker2下麵的文件是否變了
啟動hadoop分散式集群
在SparkMaster節點格式化集群的文件系統
輸入
hadoop namenode -format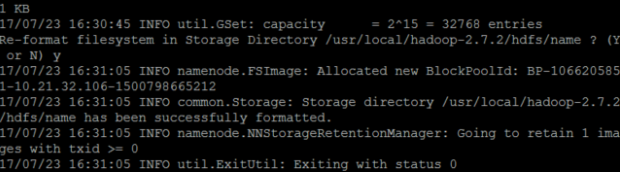
啟動Hadoop集群
start-all.sh
查看各個節點的進程信息
使用
jps查看各節點的進程信息
可以看到



此時分散式的hadoop集群已經搭好了
在瀏覽器輸入
SparkMaster_IP:50070SparkMaster_IP:8088看到以下界面代表Hadoop集群已經開啟了
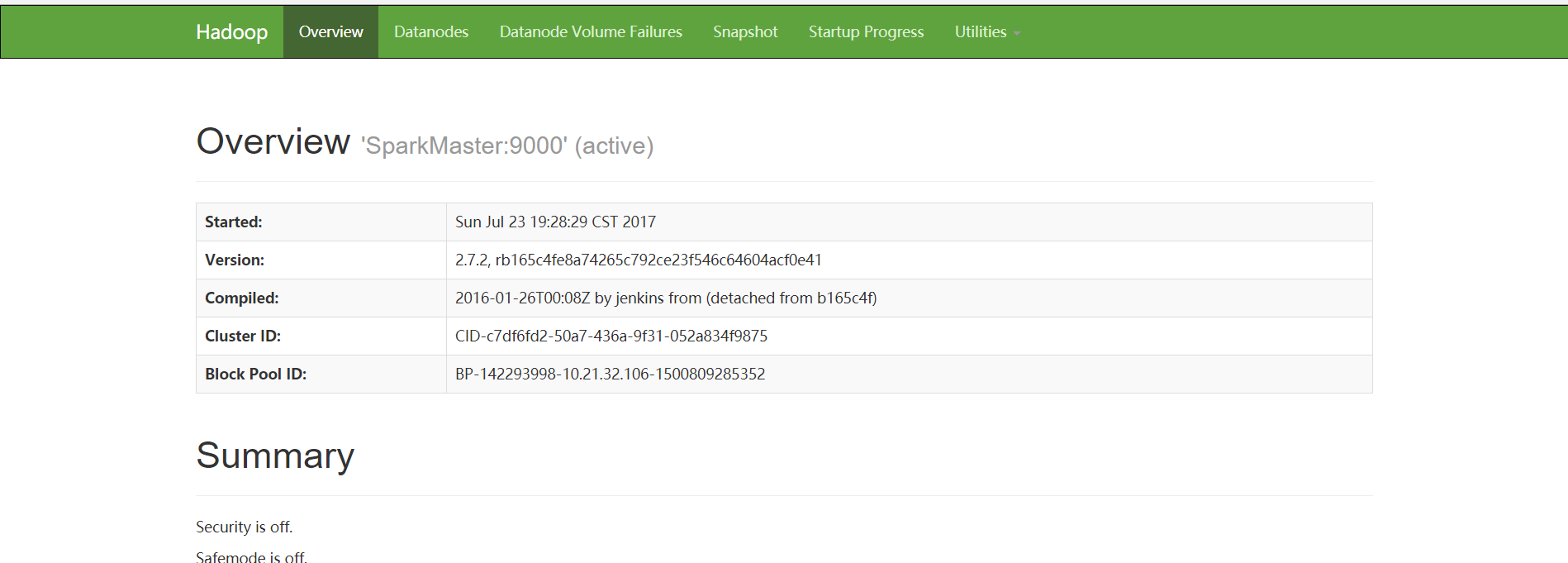

結言
到此Hadoop的分散式集群就搭好了。這個Spark運行的基礎。
參見:CentOS 6.7安裝Hadoop 2.7.2
++王家林/王雁軍/王家虎的《Spark 核心源碼分析與開發實戰》++
文章出自kwongtai'blog,轉載請標明出處!


