
本文就Pandas的運行效率作一個對比的測試,來探討用哪些方式,會使得運行效率較好。 ...
本文就Pandas的運行效率作一個對比的測試,來探討用哪些方式,會使得運行效率較好。
測試環境如下:
- windows 7, 64位
- python 3.5
- pandas 0.19.2
- numpy 1.11.3
- jupyter notebook
需要說明的是,不同的系統,不同的電腦配置,不同的軟體環境,運行結果可能有些差異。就算是同一臺電腦,每次運行時,運行結果也不完全一樣。
1 測試內容
測試的內容為,分別用三種方法來計算一個簡單的運算過程,即 a*a+b*b 。
三種方法分別是:
- python的for迴圈
- Pandas的Series
- Numpy的ndarray
首先構造一個DataFrame,數據量的大小,即DataFrame的行數,分別為10, 100, 1000, … ,直到10,000,000(一千萬)。
然後在jupyter notebook中,用下麵的代碼分別去測試,來查看不同方法下的運行時間,做一個對比。
import pandas as pd
import numpy as np
# 100分別用 10,100,...,10,000,000來替換運行
list_a = list(range(100))
# 200分別用 20,200,...,20,000,000來替換運行
list_b = list(range(100,200))
print(len(list_a))
print(len(list_b))
df = pd.DataFrame({'a':list_a, 'b':list_b})
print('數據維度為:{}'.format(df.shape))
print(len(df))
print(df.head())
100
100
數據維度為:(100, 2)
100
a b
0 0 100
1 1 101
2 2 102
3 3 103
4 4 104
-
執行運算, a*a + b*b
-
Method 1: for迴圈
%%timeit
# 當DataFrame的行數大於等於1000000時,請用 %%time 命令
for i in range(len(df)):
df['a'][i]*df['a'][i]+df['b'][i]*df['b'][i]
100 loops, best of 3: 12.8 ms per loop
- Method 2: Series
type(df['a'])
pandas.core.series.Series
%%timeit
df['a']*df['a']+df['b']*df['b']
The slowest run took 5.41 times longer than the fastest. This could mean that an intermediate result is being cached.
1000 loops, best of 3: 669 µs per loop
- Method 3: ndarray
type(df['a'].values)
numpy.ndarray
%%timeit
df['a'].values*df['a'].values+df['b'].values*df['b'].values
10000 loops, best of 3: 34.2 µs per loop
2 測試結果
運行結果如下:
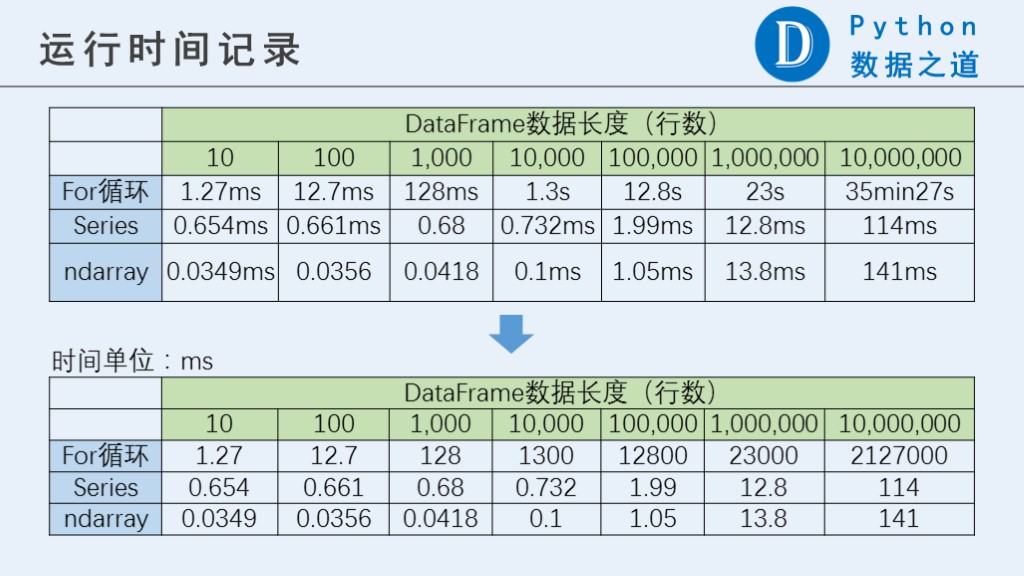
從運行結果可以看出,for迴圈明顯比Series和ndarray要慢很多,並且數據量越大,差異越明顯。當數據量達到一千萬行時,for迴圈的表現也差一萬倍以上。 而Series和ndarray之間的差異則沒有那麼大。
PS: 1000萬行時,for迴圈運行耗時特別長,各位如果要測試,需要註意下,請用 %%time 命令(只測試一次)。
下麵通過圖表來對比下Series和ndarray之間的表現。
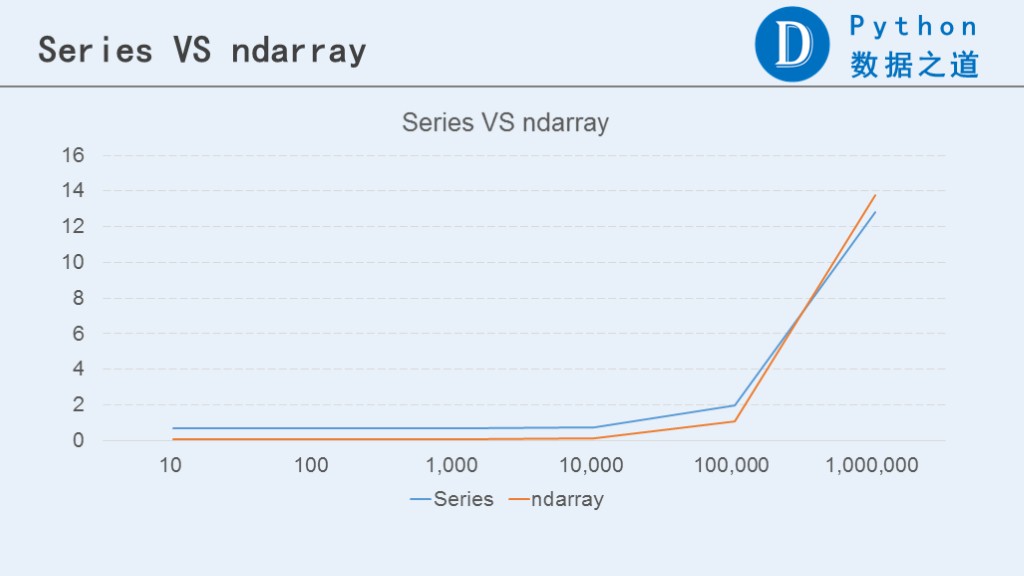
從上圖可以看出,當數據小於10萬行時,ndarray的表現要比Series好些。而當數據行數大於100萬行時,Series的表現要稍微好於ndarray。當然,兩者的差異不是特別明顯。
所以一般情況下,個人建議,for迴圈,能不用則不用,而當數量不是特別大時,建議使用ndarray(即df[‘col’].values)來進行計算,運行效率相對來說要好些。


更多相關文章
-
Django添加靜態文件有兩種方法: 首先setting.py配置文件中添加靜態文件的路徑: STATICFILES_DIRS = [ os.path.join(BASE_DIR, "statics"),] statices為你所建立的存放靜態文件的文件夾名 然後進行引用。 1、html 文件中通過 ...
-
頁面效果 實現步驟 1.Jsp頁面要求 2.VO對象中添加非持久化javabean屬性 3.兩種文件下載方式 方式一:不使用struts2提供的文件下載(普通方式) Action類中添加方法: 方式二:使用struts2提供的文件下載 第一步:配置struts.xml 第二步:VO對象中,添加Inp ...
-
php-ml是一個使用PHP編寫的機器學習庫。雖然我們知道,python或者是C++提供了更多機器學習的庫,但實際上,他們大多都略顯複雜,配置起來讓很多新手感到絕望。php-ml這個機器學習庫雖然沒有特別高大上的演算法,但其具有最基本的機器學習、分類等演算法,我們的小公司做一些簡單的數據分析、預測等等都 ...
-
jdk1.7.0_79 眾所周知,Java是一門不用程式員手動管理記憶體的語言,全靠JVM自動管理記憶體,既然是自動管理,那必然有一個垃圾記憶體的回收機制或者回收演算法。本文將介紹幾種常見的垃圾回收(下文簡稱GC)演算法。 在Java堆上分配一個記憶體給實例對象時,此時在虛擬機棧上引用型變數就會存放這個實例對象 ...
-
10.文件和異常 學習處理文件,讓程式快速的分析大量數據,學習處理錯誤,避免程式在面對意外時崩潰。學習異常,異常是python創建的特殊對象,用於管理程式運行時出現的錯誤,提高程式的適用性,可用性,和穩定性。 學習模塊json,json可以用於保存用戶數據,避免程式意外停止運行時丟失。 學習處理文件 ...
-
今天在windows下使用notepad++寫了個python腳本,傳到linux伺服器執行後提示:-bash: ./logger.py: usr/bin/python^M: bad interpreter: No such file or directory 1.原因分析 這是不同系統編碼格式引起 ...
-
數據分頁 ID 姓名 年齡 專業 pageCount ? pageCount : currPage; PreparedStatement pst = conn.prepareStatement("select * from studen... ...
-
1.postForObject :傳入一個業務對象,返回是一個String 調用方: BaseUser baseUser=new BaseUser(); baseUser.setUserid(userid); baseUser.setPass(pass); String postForObject ... ...
