
jdk1.7.0_79 眾所周知,Java是一門不用程式員手動管理記憶體的語言,全靠JVM自動管理記憶體,既然是自動管理,那必然有一個垃圾記憶體的回收機制或者回收演算法。本文將介紹幾種常見的垃圾回收(下文簡稱GC)演算法。 在Java堆上分配一個記憶體給實例對象時,此時在虛擬機棧上引用型變數就會存放這個實例對象 ...
jdk1.7.0_79
眾所周知,Java是一門不用程式員手動管理記憶體的語言,全靠JVM自動管理記憶體,既然是自動管理,那必然有一個垃圾記憶體的回收機制或者回收演算法。本文將介紹幾種常見的垃圾回收(下文簡稱GC)演算法。
在Java堆上分配一個記憶體給實例對象時,此時在虛擬機棧上引用型變數就會存放這個實例對象的起始地址。
Object obj = new Object();
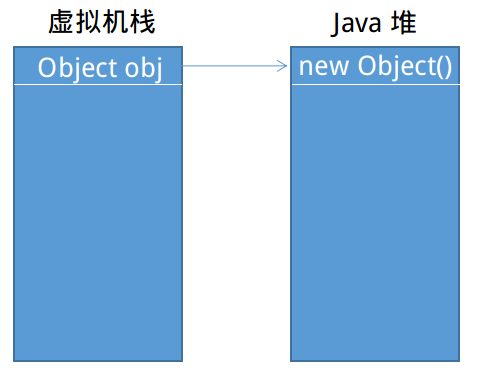
現在如果我們將變數賦值為null。
obj = null;

此時可以看到Java堆上的實例對象無法再次引用它,那麼它就是被GC的對象,我們稱之為對象“已死”。那虛擬機棧上的obj變數呢?上文《JVM入門——運行時數據區》提到過,虛擬機棧是線程獨占的,也就是說隨著線程初始而初始,消亡而消亡,當線程被銷毀後,虛擬機棧上的記憶體自然會被回收,也就是說虛擬機棧上的這塊記憶體空間不在虛擬機GC範圍。下圖展示了垃圾回收的記憶體範圍:

1.對象是否“已死”演算法——引用計數器演算法
對象中添加一個引用計數器,如果引用計數器為0則表示沒有其它地方在引用它。如果有一個地方引用就+1,引用失效時就-1。看似搞笑且簡單的一個演算法,實際上在大部分Java虛擬機中並沒有採用這種演算法,因為它會帶來一個致命的問題——對象迴圈引用。對象A指向B,對象B反過來指向A,此時它們的引用計數器都不為0,但它們倆實際上已經沒有意義因為沒有任何地方指向它們。所以又引出了下麵的演算法。
2.對象是否“已死”演算法——可達性分析演算法
這種演算法可以有效地避免對象迴圈引用的情況,整個對象實例以一個樹呈現,根節點是一個稱為“GC Roots”的對象,從這個對象開始向下搜索並作標記,遍歷完這棵樹過後,未被標記的對象就會判斷“已死”,即為可被回收的對象。

GC演算法
1.標記-清除演算法
等待被回收對象的“標記”過程在上文已經提到過,如果在被標記後直接對對象進行清除,會帶來另一個新的問題——記憶體碎片化。如果下次有比較大的對象實例需要在堆上分配較大的記憶體空間時,可能會出現無法找到足夠的連續記憶體而不得不再次觸發垃圾回收。
2.複製演算法(Java堆中新生代的垃圾回收演算法)
此GC演算法實際上解決了標記-清除演算法帶來的“記憶體碎片化”問題。首先還是先標記處待回收記憶體和不用回收的記憶體,下一步將不用回收的記憶體複製到新的記憶體區域,這樣舊的記憶體區域就可以全部回收,而新的記憶體區域則是連續的。它的缺點就是會損失掉部分系統記憶體,因為你總要騰出一部分記憶體用於複製。
在上文《JVM入門——運行時數據區》提到過在Java堆中被分為了新生代和老年代,這樣的劃分是方便GC。Java堆中的新生代就使用了GC複製演算法。在新生代中又分為了三個區域:Eden 空間、To Survivor空間、From Survivor空間。不妨將註意力回到這張圖的左邊新生代部分:
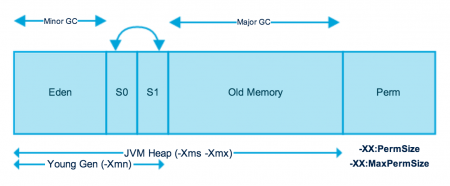
新的對象實例被創建的時候通常在Eden空間,發生在Eden空間上的GC稱為Minor GC,當在新生代發生一次GC後,會將Eden和其中一個Survivor空間的記憶體複製到另外一個Survivor中,如果反覆幾次有對象一直存活,此時記憶體對象將會被移至老年代。可以看到新生代中Eden占了大部分,而兩個Survivor實際上占了很小一部分。這是因為大部分的對象被創建過後很快就會被GC(這裡也許運用了是二八原則)。
3.標記-壓縮演算法(或稱為標記-整理演算法,Java堆中老年代的垃圾回收演算法)
對於新生代,大部分對象都不會存活,所以在新生代中使用複製演算法較為高效,而對於老年代來講,大部分對象可能會繼續存活下去,如果此時還是利用複製演算法,效率則會降低。標記-壓縮演算法首先還是“標記”,標記過後,將不用回收的記憶體對象壓縮到記憶體一端,此時即可直接清除邊界處的記憶體,這樣就能避免複製演算法帶來的效率問題,同時也能避免記憶體碎片化的問題。老年代的垃圾回收稱為“Major GC”。


