
-- 修改欄位 alter table emp MODIFY dept_id int; -- 刪除欄位 alter table emp drop COLUMN dept_id; 之前就當是 熱身了,跟著這個老師 你會覺得 真的能學到很多東西。要好好努力了! 上面兩個語句是通用性很強的語句。是 在 o
-- 修改欄位
alter table emp MODIFY dept_id int;
-- 刪除欄位
alter table emp drop COLUMN dept_id;
之前就當是 熱身了,跟著這個老師 你會覺得 真的能學到很多東西。要好好努力了!
上面兩個語句是通用性很強的語句。是 在 oracle 裡面也支持的語法。
今天要練習的點:
主外鍵, 多表聯查,內連接 外鏈接 -左外鏈接 右外鏈接 全外鏈接
以及一些 通用性語法規則。感覺點不是特別多。應該 可以的。
給不會的點,做標記就可以了。
Point 1:
這個裡面varchar 和 char 兩種方式 都是代表字元串,varchar 可變長度字元串。char 不可變長度字元串。
兩者各有優勢,char 不可變則可以讓 查詢速度更快。
Varchar 長度可變,所以可以節省空間,但是 查詢速度會相應降低
舉例:
Create table stu(
Name char(10);
);
Create table stu(
Name varchar(10);
);
Insert into stu values ('nihao');
在char類型中仍然占用10個字元。
但是varchar裡面只占用5個字元。
所以結果是char中更浪費空間,但是查詢效率更高,因為在
varchar裡面是按位 n i h a o 就是 一個 字元 一個 字元 來進行比較,所以查詢效率會很低。
modify只能用來更改欄位屬性。
而change 既可以更改欄位名 也可以為欄位更改欄位類型 以及欄位的約束。
2015.10.27練習題:
一、
1、創建emp表:
emp_id int, 員工編號
emp_name varchar(20),員工姓名
emp_age int,員工年齡
emp_address varchar(50),員工住址
emp_date varchar(20)入職時間
2、刪除該表 (因為
規範的命名是:資料庫尾碼名為:db 表名尾碼名是 tb
欄位名的前部分是表名 ,後部分是屬性名中間用 下劃線鏈接。舉例
emp_tb_id
emp_tb_name)
3、重新添加該表,表名為emp_tb
4、為了操作方便,為表改名 為emp。
5、創建dept表:
dept_id int,
dept_name varchar(20)
6、添加欄位 為emp表 添加一個 dept_id 欄位。
7、修改此欄位為 varchar(20)。利用 modify關鍵字
8、將此欄位屬性值改回為int類型。利用change關鍵字
區別:
modify只能用來更改欄位屬性。
而change 既可以更改欄位名 也可以為欄位更改 欄位類型 以及欄位的約束。
9、*刪除欄位 刪除 入職時間列。
最好是用alter table emp drop column 列名。這個 column在mysql裡面可寫可不寫,但是但是在其他語法結構裡面,就十分重要。所以最好記住這個關鍵字。
10、插入數據:
![]()

11、修改數據:
(1)將地址為空的員工的地址改為北京,(2)部門號設置為2.
12、刪除數據:
二、
我們常見的約束有哪些?至少寫出6個。行級約束和列級約束分別指什麼,請對這六個約束,進行相應分類。約束的意義在哪裡?
三、
Char 和 varchar 有什麼異同點?
四、約束的三種添加方式?
-- 1
create table emp(
emp_id int,
emp_name varchar(20),
emp_age int,
emp_address varchar(20),
emp_date date
);
-- 2
drop table emp;
-- 3
create table emp_tb(
emp_id int,
emp_name varchar(20),
emp_age int,
emp_address varchar(20),
emp_date date
);
-- 4
alter table emp_tb rename emp;
-- 5
create table dept(
dept_id int,
dept_name varchar(20)
);
-- 6
alter table emp add column dept_id int;
-- 7
alter table emp modify dept_id varchar(20);
-- 8
alter table emp change dept_id dept_id int;
-- 9
alter table emp drop column emp_date;
-- 10
SELECT * from emp;
insert into emp (emp_id,emp_name, emp_age, emp_address)values (1,'張三',23,'北京');
insert into emp (emp_id,emp_name,emp_age) values (2,'wangwu',45)
-- 11
update emp set emp_address='北京' where emp_address is null;
update emp set dept_id=2;
-- 12
delete from emp;
資料庫的約束操作:為了保持數據的完整性:
我們知道的關鍵字有:
not null, primary key, unique foreign key default CHECK(這個 mysql語法裡面沒有)
他們可以分成行級約束 和列級約束。
兩者的區別在於,行級約束是指,行與行之間存在制約關係,即:某一行取值為a 另一行的取值收到a的制約,不可以再為a。這就屬於行級約束。
列級約束,是相對於自身的一種約束,比如 不能為空,即 只跟自己有關係的約束條件。
根據這種定義:我們可以將上面六種關鍵字進行如下分類:
行級約束:primary key;unique
列級約束:not null;foreign key;default;CHECK
針對約束有兩種添加方式,有一種我們已經熟知的直接在屬性後面添加。
舉例:
Create table student(
Stuid int primary key,
Stuname varchar(20)
);
第二種,在創建表的最後一行進行添加。
Create table student(
Stuid int,
Stuname varchar (20),
Constraint pk_student_id primary key (stuid)
);
四個部分來修飾 括弧 千萬萬千 註意了!
約束 給出需要系統知道的名稱 約束類型 (列名)
constraint pk_emp_tb3_address default '北京' (emp_address) 結尾添加 預設值約束 並不容易。
資料庫錯誤 150 是什麼? 怎麼解決
constraint unique (emp_address) 這也是可行的。
外鍵約束添加方式:
好吧 也是 醉了 在外面可以 添加,在創建的裡面 就是 添加不上。
這個 地方還要多鞏固
約束 的添加方式
在表結尾 添加的方式
以及在表外添加的方式。
這裡寫筆記吧,我覺得 我會的!!!
emp_age Between A and B
等價於:emp_age >=A and emp_age<=B
Select * from emp where id in (20,8,4,2)
查詢emp中的所有信息 當id 為 20或者8或者 4或者 2 。
反向查詢 select * from emp where id not in (20,8, 4,2)
查詢emp表中 id 不等於 20 8 4 2 的員工的所有信息
Between and 和 in 之間 是有區別的。
Between and是一個 區間
In 是一個 我們自己定義的範圍
模糊查詢
Select * from emp where name like 'a%';
在emp表中查找 name 以a打頭的名字
Select * from emp where name like '%a'
在emp表中 查找 以a結尾的名字
Select * from emp where name like '%a%'
在emp表中 查找 名字中包含a的名字
Select * from emp where name like '_a%'
在emp表中 查找 名字為“空格a 噠噠噠”形式的名字
換句話說 “_” 是占位符
“%” 是通配符
通過 我們的理解易得:
Select from where 的查詢順序是:
From where select
Order by 的順序:
Select * from TABLE where COLUMN1=? Order by COLUMN2 desc,COLUMN3
Asc
從表中查找列名1等於問號 的所有信息 以COLUMN2 降序排序 當COLUMN2的值相等時,以COLUMN3 進行排序。
根據這個套路 所以 先做 select from where order by 四者的順序是
from where select order 進行的。
所以 現在給出這樣一張表:
Create table emp(
Emp_id int,
Emp_name varchar(20),
Salary int//月薪
);
現在題目為:按照年薪對emp查詢出的結果進行排序:
Select *,salary*12 年薪 from emp where 1=1 order by 年薪;
聚合函數:
Select count (*) from emp;查詢一共有多少條記錄
Select max(emp_age) from emp;查詢 員工的最大年齡
Select min(emp_age) from emp;查詢員工的最小年齡
Select avg(sal) from emp;查詢員工的平均工資
Select sum(sal),avg(sal) max(sal)from emp;查詢emp表中 的每月工資總和 平均工資 和工資最大值
!!!
如果有分組查詢 select 後面只能顯示 分組欄位 或者分組函數。
例如下麵這條語句:
Select avg(sal),max(sal),dept_id from emp group by dept_id;
查詢平均工資 和最大工資 還有部門編號 從員工表中,通過 部門編號進行分組。
![]() 際上並未擁有次最大工資,這樣在其他資料庫中認為是不安全的。當然最初設計這款資料庫的人認為,我就要顯示某個人舉例平均工資和最大工資的一個數量上的關係,可能這樣他就允許了這樣一種情況。
際上並未擁有次最大工資,這樣在其他資料庫中認為是不安全的。當然最初設計這款資料庫的人認為,我就要顯示某個人舉例平均工資和最大工資的一個數量上的關係,可能這樣他就允許了這樣一種情況。
其實,在mysql裡面是可以顯示*的。但是 這樣會出現奇怪的數據集合,在其他的資料庫裡面是不允許這樣的語句出現的。所以 在這裡 就要記住,如果有分組查詢那麼select後面只能顯示 分組欄位或者分組函數。
!!!
聚合和分組查詢一起使用的時候,函數計算數據是分組後的數據
舉例:
Select avg(sal),max(sal),dept_id from emp group by dept_id having avg(sal)>1800
從emp表中 查詢平均工資 最大工資 部門編號 通過 部門編號來分組 其中顯示 平均工資大於1800的數據。
什麼時候 會分組這個要多做一些練習才能分析出來
關於分組查詢的問題:
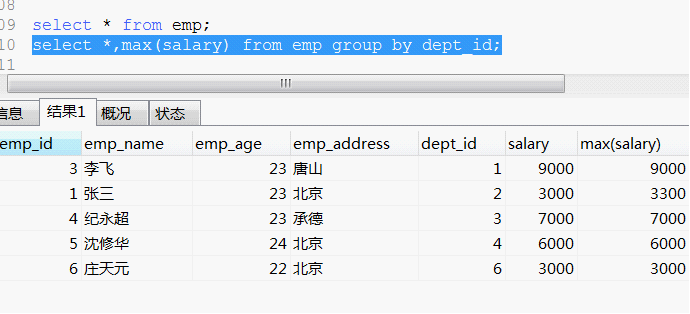
我們想要挑選不同部門的最大工資:然後發現在第二個部門裡面,最高工資是3300,如果此時 我們將salary列去掉。

就會發現張三得到了最高工資。這樣的語法結構在mysql裡面是被允許的。但是在其他資料庫系統裡面是不被允許的。其他資料庫認為這樣做 不安全。
所以 這可以算是一個語法特性。
所以這就是 我們記錄的筆記:
如果有分組查詢,那麼分組查詢的顯示條件只能有:分組欄位或者分組函數(聚合函數)
也即是 select 後面只能是 分組欄位 或者 分組函數或者叫聚合函數。
所以下麵這句話看著,就很順眼,也很好理解:
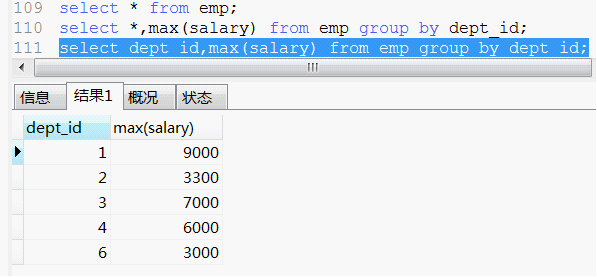
前面是部門編號 後面是部門對應的最高工資。
聚合函數 (分組函數)一起使用的時候函數計算數據是分組後的數據。
聚合函數 就是 分組函數
所以 我們可以排一下序了
From where group by having select order by

看到我們的排序,你發現 having 在select 前面,所以 在having 裡面不可能有 “平均工資” 這個 條目,這樣做是非法的。
也就是說: 這也是mysql的一個特性。在其他資料庫裡面,是不允許這樣做的。
而且 能很清晰的知道 這條語法的意義:
找到不同部門裡面的平均工資 和最高工資。
我們可以完善一下 對應一下部門表得到 完整的想要的 數據:
![]()
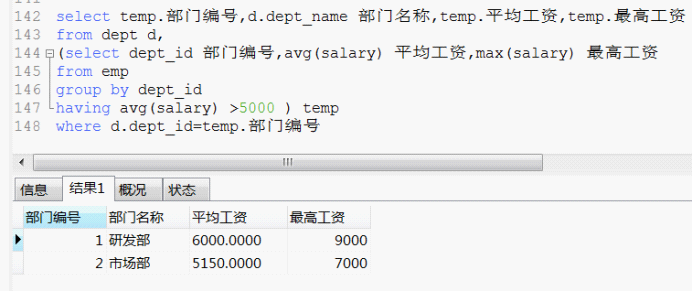
那種寫法並不存在,或者 就應該起一個別名。因為程式也不打算算兩次 既然我們在前面已經得到了相關數據的話。
後面用到的所有數據 應該是 已經出現過了的!!!
好吧 腦袋有點兒 漿糊了 主要是 太亂了,一直在吵吵,或者 一上午 都在乾同一件事,真的可能體力不支了。![]()
好吧 編一個 場景:
要舉辦聯誼會了,要求找到不同部門之間同年齡的員工。

最全查詢順序:
Select from where group by having order by limit
七者的執行順序:
From where group by having select order by limit
符合這個規範執行的就是 絕對通用的資料庫查詢與法。
其次加一個
分組查詢的顯示部分只能有 分組條件 或者分組函數。
內外聯:


