
今天和搜索部門一起做了一下MQ的遷移,順便交流一下業務和技術。發現現在90後小伙都挺不錯。我是指能力和探究心。我家男孩,不招女婿。 在前面的文章中也提到,我們有媒資庫(樂視視頻音頻本身內容)和全網作品庫(外部視頻音頻內容),數據量級都在千萬級。我們UV,PV,CV,VV都是保密的。所以作為一個合格的 ...
今天和搜索部門一起做了一下MQ的遷移,順便交流一下業務和技術。發現現在90後小伙都挺不錯。我是指能力和探究心。我家男孩,不招女婿。
在前面的文章中也提到,我們有媒資庫(樂視視頻音頻本身內容)和全網作品庫(外部視頻音頻內容),數據量級都在千萬級。我們UV,PV,CV,VV都是保密的。所以作為一個合格的員工來說………………數值我也不知道。總之,這些數據作為最終數據源,要走一個跨多個部門的工作流才最終出現在用戶點擊搜索按鈕出現的搜索框里。大體流程圖如下:
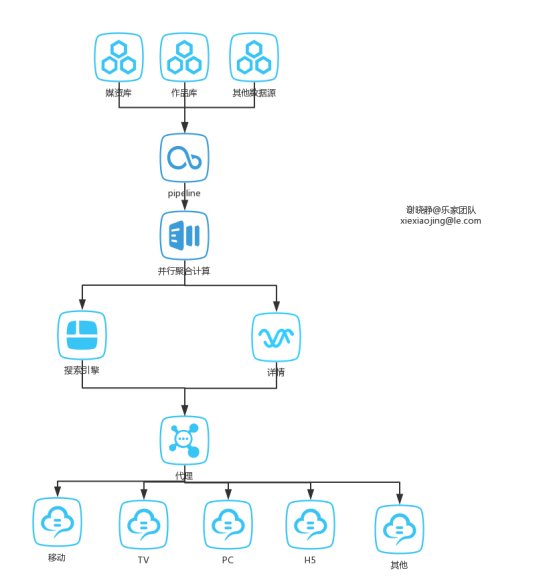
這個流程圖之所以沒像以往一樣手繪,嗯,那是因為:鋼筆放在公司了。
這裡面除了兩個庫都在我們這邊之外,其他的一個框是一個部門。我們這邊給pipeline的數據交付使用的是我開發的離線服務。pipeline將各個來源的數據做重覆歸併處理。就是一些視頻內容是一樣的,但是可能來源不同或者名稱有相似但可能不完全相同,而實際上是一個視頻。打個比方,大學時看過一個電影叫<a Cinderella story>翻譯成中文有的翻譯成《灰姑娘的故事》也有翻譯成《灰姑娘的玻璃手機》,但是可以根據其導演和演員表等判斷其實是同一個視頻。這些相同的視頻要聚合成一個專輯。推舉最優質的描述作為專輯的描述。展開詳情有各個來源的排序後視頻列表。

正常全網搜索也會將自家的視頻放在前面:
這個歸併處理大家可能也猜到了,並行計算嘛,用的是mapreduce。因為是視頻數的組合操作,數量級是蠻大的。搜索引擎返回的是數據都是ID,真正的數據從詳情部門返回。加個代理是啥意思?對調用端透明嘛,有修改只要改代理端。
搜索引擎是獨立的部門,沒打過交道。但是我在上家公司的公司主要負責全公司的垂直搜索,數據來源都是關係型資料庫,數據量不大,當時用的是搜索引擎用的是solr。分詞器用的是開源的IK分詞器。因為當時公司做的是面向企業家的高端人脈,搜索對人名,公司名等的檢索結果的排序有很多特殊的要求,所以當時研究過分詞器的源碼,也對分詞器進行了一些更加切合項目的改造。比如有個需求是過濾輸入的html標簽。但是在Solr中對索引讀入後的第一個操作就是分詞,使用Solr自帶的或者外部的分詞器。然後再對分好的詞進行更細節的過濾或者近義詞之類的。但是這第一步就直接破壞了文檔的結構,變成了一個個單詞,而不是html文檔形式。再去除很麻煩而且效率低。所以我當時的做法是直接修改了IK分詞器的源碼,讀入數據第一個操作先過濾標簽。apache有現成的工具類。這樣避免了讀入讀出帶來的性能損耗。當時也做過測試,迴圈跑10w次用我改造後的分詞器和不改造分詞器用solr過濾器過濾正則表達式的方式比的話,執行效率大約高出20倍。當時的還發現不管是solr還是ES,都是基於lucene的嘛,更適用於西文的一些檢索。像中文檢索不需要像西文那樣需要語言處理器變小寫然後再基於演算法或匹配進行詞根化。反而需要更多基於詞典的,包括同義詞,近義詞這些。所以從分詞這方面也是有很多的優化空間的。
個人覺得做搜索數據分析很重要。比如從日誌分析中可以發現有些用戶輸入搜索關鍵詞:賈躍亭,那麼他很有可能對包含“樂視”關鍵詞的信息也很有興趣。發現了這個問題之後,我就對這類數據做了一個詞庫,進行了搜索和索引上一些詞的雙向綁定。就是相當於一個同義詞的功能。建議將本文的題目放到幾個搜索引擎里搜索一下,對比看看結果,挺有意思。
詳情數據也是存在文檔型資料庫里,其實用mangoDB挺合適的。但是公司有統一的cbase集群,就直接放到cbase里了。我經常需要跟人家解釋半天:cbase,couchbase,memcached都是啥關係。memcached大家都很熟悉。但是memcached不支持持久化。如果使用單純的memcached集群,節點失效時沒有任何的容錯。應對措施需要交由用戶處理。所以就產生了一個加強版的memcached集群:couchbase。數據層以memcached API對數據進行交互,系統在memcached程式中嵌入持久化引擎代碼對數據進行緩存,複製,持久化等操作,非同步隊列的形式將數據同步到CouchDB中。由於它實現了數據自動在多個節點本分,單節點失效不影響業務。支持自動分片,很容易線上維護集群。cbase又是啥東西呢?這是我司對couchbase進行了一個二次開發,主要的改進點是對value的最大值進行了強行擴容:本來memcached最大Value設定是1M。我們給擴容到4M。但是慎用大的value。value值從1K到不超過1M平均分佈時,實際使用容量不超過50%時性能較好。如果大value很多,達不到這個值性能就會急劇下降。
早在08年,09年的時候。facebook,mixi等國外知名互聯網公司為了減少資料庫訪問次數,提高動態網頁的訪問速度,提高可擴展性,開始使用memcached。作為以facebook為標桿的人人網,這種技術也很快在其內部各個部門得到了普及。因為memcached集群採用的是伺服器間互不通信的分散式方式。客戶端和伺服器端的通信採用的是分散式演算法。這就是所說的節點失效時沒有任何的容錯。
這裡提一個概念,就是常見的容錯機制。我知道的,主要是6種。
☆ failover:失敗自動切換
當出現失敗,重試其他伺服器,通常用於讀操作,重試會帶來更長延遲。
像我們的MQ客戶端配置,採用是failover為roundrobin。採用輪詢調度演算法來容錯。
☆ failfast:快速失敗
只發起一次調用,失敗立即報錯,通常用於非冪等性的寫操作。如果有機器正在重啟,可能會出現調用失敗。
我們的一個資料庫雖然升級成了mariaDB。但是還是一主多從。這時候寫入主庫失敗採用的就是failfast方式。
☆ failsafe:失敗安全
出現異常時,直接忽略,通常用於寫入日誌等操作。
☆ failback:失敗自動恢復
後臺記錄失敗請求,定時重發。通常用於消息通知操作。不可靠,重啟丟失。
☆ forking:並行調用多個伺服器
只要一個成功即返回,通常用於實時性要求較高的讀操作。需要浪費更多服務資源。
☆ broadcast
廣播調用,所有提供逐個調用,任意一臺報錯則報錯。通常用於更新提供方本地狀態,速度慢,任意一臺報錯則報錯。
讀過《java併發編程實踐》的朋友看到容錯機制很容易會聯想到java的fail-fast和fail-safe。周五和90後小伙子交流技術也正好聊到集合類的相關問題。有一個問題是在AbstractList的迭代器中,set操作做了expectedModCount = modCount。按理說不需要改變長度,為啥也要做這個操作。而實現它的子類set中都沒有實現這個操作。我的想法是有一些實現set的方法有可能是通過添加刪除來變相實現的。總之,繼續於這個AbstractList的實現類都會檢查這個expectedModCount 和 modCount的一致性。不一樣會即可拋出併發修改異常,這就是failfast。而像CopyOnWriteArrayList這種的,寫操作是在複製的集合上進行修改,不會拋出併發修改異常是failsafe的。

