
先聊聊業務。我們媒資這邊目前的核心數據是樂視視頻的樂視meta和專門存儲電視劇,綜藝節目,體育賽事這種長視頻的作品庫。樂視視頻的數據都是多方審核的,需要很多運營。但是作品庫部分卻是弱運營的,運營都不超過10個人。結果做了兩個app,日活都有四五百萬的樣子。我們其實都有各樣的技術儲備,很容易可以抓取人 ...
先聊聊業務。我們媒資這邊目前的核心數據是樂視視頻的樂視meta和專門存儲電視劇,綜藝節目,體育賽事這種長視頻的作品庫。樂視視頻的數據都是多方審核的,需要很多運營。但是作品庫部分卻是弱運營的,運營都不超過10個人。結果做了兩個app,日活都有四五百萬的樣子。我們其實都有各樣的技術儲備,很容易可以抓取人家數據,自己套上一個殼子線上解碼。但是我們逼格很高,都不這麼做的。樂視是個非常註重版權的公司。我名下都有近百個專利了。
撇開這個項目,先看這邊一般web項目的常用JVM配置。
<jvm-arg>-Xms4g</jvm-arg>
<jvm-arg>-Xmx4g</jvm-arg>
<jvm-arg>-Xss1m</jvm-arg>
<jvm-arg>-Xmn1g</jvm-arg>
<jvm-arg>-XX:MaxPermSize=128M</jvm-arg>
<jvm-arg>-XX:MaxTenuringThreshold=3</jvm-arg>
這個配置resin的伺服器業務不是特別複雜的情況下,承載單台QPS4k的併發是不成問題的。下麵的圖拿來只是覺得我們鄒老師畫的好看,裡面涵蓋了很多系統,只要是web server這個配置都是夠用的。我們線上機器都是32G24核高配物理機。其實負載都在2點多。就是說用8G4核虛擬機完全夠用。但是我們的服務相當重要,運維哥哥那邊虛擬化做的不太好,不是很穩定的,線上我們都不這麼用。所以,JVM配置基本上多一點少一點點線上效果不是很明顯。
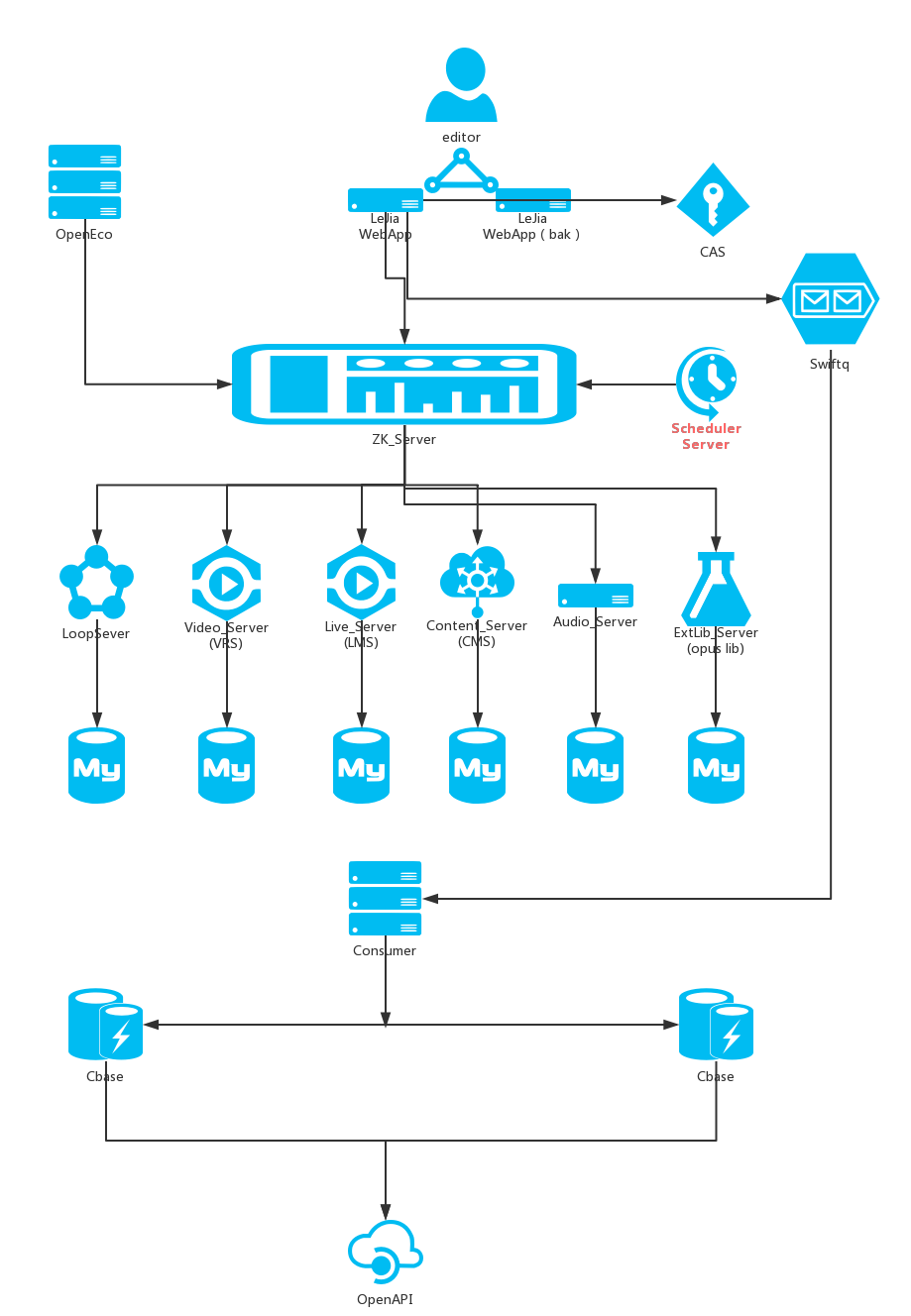
離線數據是推送給樂視視頻的搜索部門,樂視視頻的日活是千萬級。當然搜索哥哥那邊也在搞全網搜索,覆蓋廣,再加上快和準是他們的目標。但是最最基本的視頻內容來源是我這邊出的。下麵圖是整體業務架構,下麵標的技術是主要的性能消耗點。有些紅色的線是我兒子畫的,不想這麼浪費一張A4紙就當手稿用了。提倡環保,人人有責。
調優之前先說說這個mysql從庫。因為這個項目是好多年前就開始做了,依然用的是一主多從的拓撲,binlog複製的集群模式。從庫用的是通知模式,時延也就是ms級都還好。寫數據QPS也就幾十,多加幾個從庫IO也不會瓶頸。主要問題是主庫單點,從庫的複製根據分散式系統的CAP理論,保證的是可用性和分區容忍性。一致性級別也就是個最終一致性。上學的時候都學過,單個資料庫事務用的是ACID模型,記得當年考試的必考點就是事務的原子性,一致性,隔離性,持久性。我竟然還記得。但是一說集群,特別是如今nosql時代,說的也就只能是BASE理論了。binlog採用的是DML語句複製和一旦發現DML語句無法精確複製時就會採用基於行的複製。記得出現過一次事故,資料庫表結構有更新,導致執行語句錯誤,數據同步停止。
我來公司後新開發的項目都是用的公司的雲資料庫。這個稍微高級一點,用的是Percona XtraDB Cluster做的集群。它是一個mysql高可用和可擴展的解決方案。可以同步複製,事務要麼在所有節點提交或不提交。多主複製,任意節點都可以寫操作。缺點,我沒測試過,從原理來說,寫肯定比傳統一主多從慢。因為從弱一致的非同步冗餘變成了強一致的同步冗餘了嘛。而且必須是innodb引擎。我們的所謂雲,也就是做了一個去中心化。
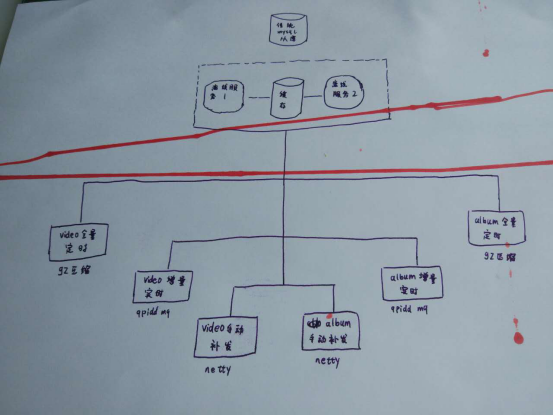
離線服務是用了兩台機器,用memcached緩存一個更新時間點的時間戳做增量實時的通訊,定時全量和手動補發是一個簡單兩台伺服器熱備。
說說緩存集群。memcached集群既然使用的moxi代理,那麼它的集群對客戶端來說就是透明的,客戶端沒有辦法自己修改其輪詢和容災策略。但是這種代理的有一個好處就是可以管道處理,合併重覆的key,一定程度上提高了效率。關於memcached集群,昨天我們大領導找來雲存儲的大神給我們講講視頻存儲是怎麼做的。其中提到了他們那邊用的SSDB的集群。和memcached集群是一樣的。先說說存儲那邊的大體邏輯,重新在大腦里膜拜一下大神。發現我兒子有當偵探的潛質,他的塗鴉讓我想起福爾摩斯<血字的研究>。
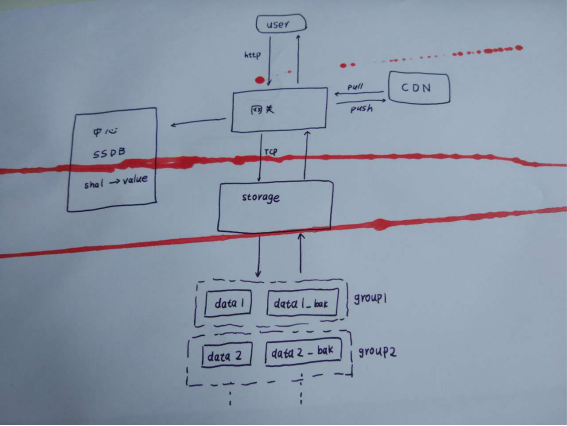
我們部門那邊上傳視頻到雲存儲,先要進行一個初始化。這個初始化會採用摘要演算法計算一下文件的sha1,如果視頻已經存在,直接返回狀態,這樣對於一些用戶就可以實現秒傳了。但是對於flash因為這個語言要計算其摘要必須將整個文件全都載入到記憶體,我們是用其他方法來生成sha1的。這個shal傳到雲存儲那邊通過SSDB經過二次開發自己實現的一個nosql資料庫,這些鍵值對的nosql資料庫查找,如果沒初始化過,返回初始化token。這個token里包含了上傳到哪個節點等信息。用戶上傳的介質就可以直接通過網關與存儲通信了。存儲那邊對於每個上產的視頻都有主備。一個主備作為一個組。組內自己有個程式做磁碟同步。會有磁碟檢查剩餘空間。新傳視頻會在未滿的集群中均勻分佈。上傳完成後一些熱點視頻會以推送的方法分發到CDN節點上,供CDN加速用。其他視頻需要CND自己來拉取。當然CDN那邊也有自己的策略。先在邊緣節點查找,找不到再來中心節點找,最後沒有在來存儲這邊。
大體流程就是這樣。問了下大神哥哥SSDB的集群是怎麼做的。他們也是通過代理的。代理上存有映射表。集群各個節點間本身不通信。需要進行一些哈希計算來找節點的bucket。如果需要添加節點,遷移過程中還是先打到原節點。等遷移完成,映射表更新再往新節點上分發。這樣做的好處是避免了rebalance的巨大開銷。在人人網的時候,7年前我們的memcached集群出過一次事故。當時我們leader升級了客戶端,演算法變了,導致全部緩存都不命中。所以這種基於演算法不實質上相互關聯的集群和gossip的集群不同,對客戶端有依賴。
qpidd的MQ集群。問過管理MQ的運維童鞋,為啥選這個。他說activeMq和rabbitMq太輕量,性能不行。Kafka又丟消息,所以才選的這個。不過去公司外面問問,貌似知道的人不多。我們部門要把支付的業務接過來,他們那邊是自己搭建了一個kafka的Mq用來集中處理日誌的。
netty部分我在前面的文章中很詳細的介紹了實戰經驗,有感興趣的可以自己找一下。
gz壓縮主要是遞歸操作,如果線程站開的特別大,壓縮過程中CPU上升會特別快,需要註意。


