
jdk1.7.0_79 對於線程池大部分人可能會用,也知道為什麼用。無非就是任務需要非同步執行,再者就是線程需要統一管理起來。對於從線程池中獲取線程,大部分人可能只知道,我現在需要一個線程來執行一個任務,那我就把任務丟到線程池裡,線程池裡有空閑的線程就執行,沒有空閑的線程就等待。實際上對於線程池的執行 ...
jdk1.7.0_79
對於線程池大部分人可能會用,也知道為什麼用。無非就是任務需要非同步執行,再者就是線程需要統一管理起來。對於從線程池中獲取線程,大部分人可能只知道,我現在需要一個線程來執行一個任務,那我就把任務丟到線程池裡,線程池裡有空閑的線程就執行,沒有空閑的線程就等待。實際上對於線程池的執行原理遠遠不止這麼簡單。
在Java併發包中提供了線程池類——ThreadPoolExecutor,實際上更多的我們可能用到的是Executors工廠類為我們提供的線程池:newFixedThreadPool、newSingleThreadPool、newCachedThreadPool,這三個線程池並不是ThreadPoolExecutor的子類,關於這幾者之間的關係,我們先來查看ThreadPoolExecutor,查看源碼發現其一共有4個構造方法。
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue)
首先就從這幾個參數開始來瞭解線程池ThreadPoolExecutor的執行原理。
corePoolSize:核心線程池的線程數量
maximumPoolSize:最大的線程池線程數量
keepAliveTime:線程活動保持時間,線程池的工作線程空閑後,保持存活的時間。
unit:線程活動保持時間的單位。
workQueue:指定任務隊列所使用的阻塞隊列
corePoolSize和maximumPoolSize都在指定線程池中的線程數量,好像平時用到線程池的時候最多就只需要傳遞一個線程池大小的參數就能創建一個線程池啊,Java為我們提供了一些常用的線程池類就是上面提到的newFixedThreadPool、newSingleThreadExecutor、newCachedThreadPool,當然如果我們想要自己發揮創建自定義的線程池就得自己來“配置”有關線程池的一些參數。
當把一個任務交給線程池來處理的時候,線程池的執行原理如下圖所示參考自《Java併發編程的藝術》
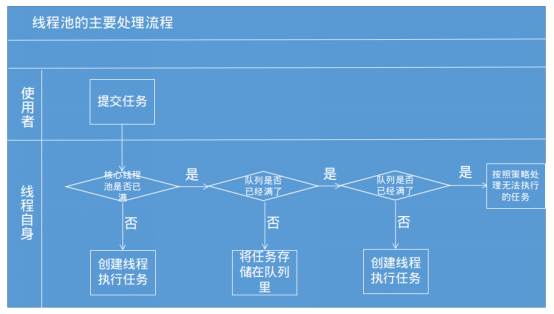
①首先會判斷核心線程池裡是否有線程可執行,有空閑線程則創建一個線程來執行任務。
②當核心線程池裡已經沒有線程可執行的時候,此時將任務丟到任務隊列中去。
③如果任務隊列(有界)也已經滿了的話,但運行的線程數小於最大線程池的數量的時候,此時將會新建一個線程用於執行任務,但如果運行的線程數已經達到最大線程池的數量的時候,此時將無法創建線程執行任務。
所以實際上對於線程池不僅是單純地將任務丟到線程池,線程池中有線程就執行任務,沒線程就等待。
為鞏固一下線程池的原理,現在再來瞭解上面提到的常用的3個線程池:
Executors.newFixedThreadPool:創建一個固定數量線程的線程池。
// Executors#newFixedThreadPool public static ExecutorService newFixedThreadPool(int nThreads) { return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); }
可以看到newFixedThreadPool中調用的是ThreadPoolExecutor類,傳遞的參數corePoolSize= maximumPoolSize=nThread。回顧線程池的執行原理,當一個任務提交到線程池中,首先判斷核心線程池裡有沒有空閑線程,有則創建線程,沒有則將任務放到任務隊列(這裡是有界阻塞隊列LinkedBlockingQueue)中,如果任務隊列已經滿了的話,對於newFixedThreadPool來說,它的最大線程池數量=核心線程池數量,此時任務隊列也滿了,將不能擴展創建新的線程來執行任務。
Executors.newSingleThreadExecutor:創建只包含一個線程的線程池。
//Executors# newSingleThreadExecutor public static ExecutorService newSingleThreadExecutor() { return new FinalizableDelegateExecutorService(new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>())); }
只有一個線程的線程池好像有點奇怪,並且並沒有直接將返回ThreadPoolExecutor,甚至也沒有直接將線程池數量1傳遞給newFixedThreadPool返回。那就說明這個只含有一個線程的線程池,或許並沒有隻包含一個線程那麼簡單。在其源碼註釋中這麼寫到:創建只有一個工作線程的線程池用於操作一個無界隊列(如果由於前驅節點的執行被終止結束了,一個新的線程將會繼續執行後繼節點線程)任務得以繼續執行,不同於newFixedThreadPool(1)不會有額外的線程來重新繼續執行後繼節點。也就是說newSingleThreadExecutor自始至終都只有一個線程在執行,這和newFixedThreadPool一樣,但如果線程終止結束過後newSingleThreadExecutor則會重新創建一個新的線程來繼續執行任務隊列中的線程,而newFixedThreaPool則不會。
Executors.newCachedThreadPool:根據需要創建新線程的線程池。
//Executors#newCachedThreadPool public static ExecutorService newCachedThreadPool() { return new ThreadPooExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>()); }
可以看到newCachedThread返回的是ThreadPoolExecutor,其參數核心線程池corePoolSize = 0, maximumPoolSize = Integer.MAX_VALUE,這也就是說當任務被提交到newCachedThread線程池時,將會直接把任務放到SynchronousQueue任務隊列中,maximumPool從任務隊列中獲取任務。註意SynchronousQueue是一個沒有容量的隊列,也就是說每個入隊操作必須等待另一個線程的對應出隊操作,如果主線程提交任務的速度高於maximumPool中線程處理任務的速度時,newCachedThreadPool會不斷創建線程,線程多並不是一件好事,嚴重會耗盡CPU和記憶體資源。
題外話:newFixedThreadPool、newSingleThreadExecutor、newCachedThreadPool,這三者都直接或間接調用了ThreadPoolExecutor,為什麼它們三者沒有直接是其子類,而是通過Executors來實例化呢?這是所採用的靜態工廠方法,在java.util.Connections介面中同樣也是採用的靜態工廠方法來創建相關的類。這樣有很多好處,靜態工廠方法是用來產生對象的,產生什麼對象沒關係,只要返回原返回類型或原返回類型的子類型都可以,降低API數目和使用難度,在《Effective Java》中的第1條就是靜態工廠方法。
回到ThreadPoolExecutor,首先來看它的繼承關係:

ThreadPoolExecutor它的頂級父類是Executor介面,只包含了一個方法——execute,這個方法也就是線程池的“執行”。
//Executor#execute public interface Executor { void execute(Runnable command); }
Executor#execute的實現則是在ThreadPoolExecutor中實現的:
//ThreadPoolExecutor#execute public void execute(Runnable command) { if (command == null) throw new NullPointerException(); int c = ctl.get(); … }
一來就碰到個不知所云的ctl變數它的定義:
private final AtomicInteger ctl = new AtlmicInteger(ctlOf(RUNNING, 0));
這個變數使用來幹嘛的呢?它的作用有點類似我們在《7.ReadWriteLock介面及其實現ReentrantReadWriteLock》中提到的讀寫鎖有讀、寫兩個同步狀態,而AQS則只提供了state一個int型變數,此時將state高16位表示為讀狀態,低16位表示為寫狀態。這裡的clt同樣也是,它表示了兩個概念:
- workerCount:當前有效的線程數
- runState:當前線程池的五種狀態,Running、Shutdown、Stop、Tidying、Terminate。
int型變數一共有32位,線程池的五種狀態runState至少需要3位來表示,故workCount只能有29位,所以代碼中規定線程池的有效線程數最多為229-1。
//ThreadPoolExecutor private static final int COUNT_BITS = Integer.SIZE – 3; //32-3=29,線程數量所占位數 private static final int CAPACITY = (1 << COUNT_BITS) – 1; //低29位表示最大線程數,229-1 //五種線程池狀態 private static final int RUNNING = -1 << COUNT_BITS; /int型變數高3位(含符號位)101表RUNING private static final int SHUTDOWN = 0 << COUNT_BITS; //高3位000 private static final int STOP = 1 << COUNT_BITS; //高3位001 private static final int TIDYING = 2 << COUNT_BITS; //高3位010 private static final int TERMINATED = 3 << COUNT_BITS; //高3位011
再次回到ThreadPoolExecutor#execute方法:
1 //ThreadPoolExecutor#execute 2 public void execute(Runnable command) { 3 if (command == null) 4 throw new NullPointerException(); 5 int c = ctl.get(); //由它可以獲取到當前有效的線程數和線程池的狀態 6 /*1.獲取當前正在運行線程數是否小於核心線程池,是則新創建一個線程執行任務,否則將任務放到任務隊列中*/ 7 if (workerCountOf(c) < corePoolSize){ 8 if (addWorker(command, tre)) //在addWorker中創建工作線程執行任務 9 return ; 10 c = ctl.get(); 11 } 12 /*2.當前核心線程池中全部線程都在運行workerCountOf(c) >= corePoolSize,所以此時將線程放到任務隊列中*/ 13 if (isRunning(c) && workQueue.offer(command)) { //線程池是否處於運行狀態,且是否任務插入任務隊列成功 14 int recheck = ctl.get(); 15 if (!isRunning(recheck) && remove(command)) //線程池是否處於運行狀態,如果不是則使剛剛的任務出隊 16 reject(command); //拋出RejectedExceptionException異常 17 else if (workerCountOf(recheck) == 0) 18 addWorker(null, false); 19 } 20 /*3.插入隊列不成功,且當前線程數數量小於最大線程池數量,此時則創建新線程執行任務,創建失敗拋出異常*/ 21 else if (!addWorker(command, false)){ 22 reject(command); //拋出RejectedExceptionException異常 23 } 24 }
上面代碼註釋第7行的即判斷當前核心線程池裡是否有空閑線程,有則通過addWorker方法創建工作線程執行任務。addWorker方法較長,篩選出重要的代碼來解析。
1 //ThreadPoolExecutor#addWorker 2 private boolean addWorker(Runnable firstTask, boolean core) { 3 /*首先會再次檢查線程池是否處於運行狀態,核心線程池中是否還有空閑線程,都滿足條件過後則會調用compareAndIncrementWorkerCount先將正在運行的線程數+1,數量自增成功則跳出迴圈,自增失敗則繼續從頭繼續迴圈*/ 4 ... 5 if (compareAndIncrementWorkerCount(c)) 6 break retry; 7 ... 8 /*正在運行的線程數自增成功後則將線程封裝成工作線程Worker*/ 9 boolean workerStarted = false; 10 boolean workerAdded = false; 11 Worker w = null; 12 try { 13 final ReentrantLock mainLock = this.mainLock; //全局鎖 14 w = new Woker(firstTask); //將線程封裝為Worker工作線程 15 final Thread t = w.thread; 16 if (t != null) { 17 mainLock.lock(); //獲取全局鎖 18 /*當持有了全局鎖的時候,還需要再次檢查線程池的運行狀態等*/ 19 try { 20 int c = clt.get(); 21 int rs = runStateOf(c); //線程池運行狀態 22 if (rs < SHUTDOWN || (rs == SHUTDOWN && firstTask == null)){ //線程池處於運行狀態,或者線程池關閉且任務線程為空 23 if (t.isAlive()) //線程處於活躍狀態,即線程已經開始執行或者還未死亡,正確的應線程在這裡應該是還未開始執行的 24 throw new IllegalThreadStateException(); 25 workers.add(w); //private final HashSet<Worker> wokers = new HashSet<Worker>();包含線程池中所有的工作線程,只有在獲取了全局的時候才能訪問它。將新構造的工作線程加入到工作線程集合中 26 int s = worker.size(); //工作線程數量 27 if (s > largestPoolSize) 28 largestPoolSize = s; 29 workerAdded = true; //新構造的工作線程加入成功 30 } 31 } finally { 32 mainLock.unlock(); 33 } 34 if (workerAdded) { 35 t.start(); //在被構造為Worker工作線程,且被加入到工作線程集合中後,執行線程任務,註意這裡的start實際上執行Worker中run方法,所以接下來分析Worker的run方法 36 workerStarted = true; 37 } 38 } 39 } finally { 40 if (!workerStarted) //未能成功創建執行工作線程 41 addWorkerFailed(w); //在啟動工作線程失敗後,將工作線程從集合中移除 42 } 43 return workerStarted; 44 }
在上面第35代碼中,工作線程被成功添加到工作線程集合中後,則開始start執行,這裡start執行的是Worker工作線程中的run方法。
//ThreadPoolExecutor$Worker,它繼承了AQS,同時實現了Runnable,所以它具備了這兩者的所有特性 private final class Worker extends AbstractQueuedSynchronizer implements Runnable { final Thread thread; Runnable firstTask; public Worker(Runnable firstTask) { setState(-1); //設置AQS的同步狀態為-1,禁止中斷,直到調用runWorker this.firstTask = firstTask; this.thread = getThreadFactory().newThread(this); //通過線程工廠來創建一個線程,將自身作為Runnable傳遞傳遞 } public void run() { runWorker(this); //運行工作線程 } }
ThreadPoolExecutor#runWorker,在此方法中,Worker在執行完任務後,還會迴圈獲取任務隊列里的任務執行(其中的getTask方法),也就是說Worker不僅僅是在執行完給它的任務就釋放或者結束,它不會閑著,而是繼續從任務隊列中獲取任務,直到任務隊列中沒有任務可執行時,它才退出迴圈完成任務。理解了以上的源碼過後,往後線程池執行原理的第二步、第三步的理解實則水到渠成。


