
DOM4J解析 特征: 1、JDOM的一種智能分支,它合併了許多超出基本XML文檔表示的功能。 2、它使用介面和抽象基本類方法。 3、具有性能優異、靈活性好、功能強大和極端易用的特點。 4、是一個開放源碼的文件 jar包:dom4j-1.6.1.jar 創建 book.xml: 運行結果: 解析 b ...
DOM4J解析
特征:
1、JDOM的一種智能分支,它合併了許多超出基本XML文檔表示的功能。
2、它使用介面和抽象基本類方法。
3、具有性能優異、靈活性好、功能強大和極端易用的特點。
4、是一個開放源碼的文件
jar包:dom4j-1.6.1.jar

創建 book.xml:
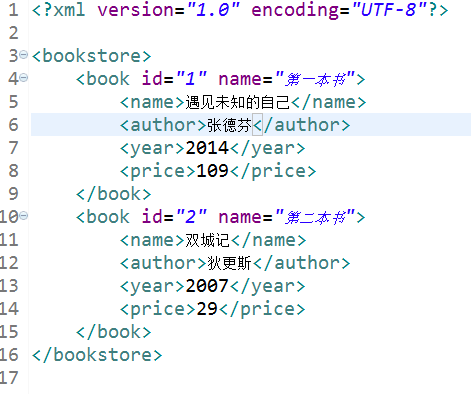
1 package com.example.xml.dom4j; 2 3 import java.io.FileWriter; 4 import org.dom4j.Document; 5 import org.dom4j.DocumentHelper; 6 import org.dom4j.Element; 7 import org.dom4j.io.OutputFormat; 8 import org.dom4j.io.XMLWriter; 9 /** 10 * dom4j創建xml文檔示例 11 * 12 */ 13 public class Dom4JTest4 { 14 public static void main(String[] args) throws Exception { 15 // 第二種方式:創建文檔並設置文檔的根元素節點 16 Element root2 = DocumentHelper.createElement("bookstore"); 17 Document document2 = DocumentHelper.createDocument(root2); 18 19 // 添加一級子節點:add之後就返回這個元素 20 Element book1 = root2.addElement("book"); 21 book1.addAttribute("id", "1"); 22 book1.addAttribute("name", "第一本書"); 23 // 添加二級子節點 24 book1.addElement("name").setText("遇見未知的自己"); 25 book1.addElement("author").setText("張德芬"); 26 book1.addElement("year").setText("2014"); 27 book1.addElement("price").setText("109"); 28 // 添加一級子節點 29 Element book2 = root2.addElement("book"); 30 book2.addAttribute("id", "2"); 31 book2.addAttribute("name", "第二本書"); 32 // 添加二級子節點 33 book2.addElement("name").setText("雙城記"); 34 book2.addElement("author").setText("狄更斯"); 35 book2.addElement("year").setText("2007"); 36 book2.addElement("price").setText("29"); 37 38 // 設置縮進為4個空格,並且另起一行為true 39 OutputFormat format = new OutputFormat(" ", true); 40 41 // 另一種輸出方式,記得要調用flush()方法,否則輸出的文件中顯示空白 42 XMLWriter xmlWriter3 = new XMLWriter(new FileWriter("book.xml"),format); 43 xmlWriter3.write(document2); 44 xmlWriter3.flush(); 45 // close()方法也可以 46 47 } 48 }
運行結果:
解析 book.xml:
1 package com.example.xml.dom4j; 2 3 import java.io.File; 4 import java.util.Iterator; 5 import java.util.List; 6 import org.dom4j.Attribute; 7 import org.dom4j.Document; 8 import org.dom4j.DocumentException; 9 import org.dom4j.Element; 10 import org.dom4j.io.SAXReader; 11 /** 12 * dom4j解析xml文檔示例 13 * 14 */ 15 public class Dom4JTest3 { 16 17 public static void main(String[] args) { 18 // 解析books.xml文件 19 // 創建SAXReader的對象reader 20 SAXReader reader = new SAXReader(); 21 try { 22 // 通過reader對象的read方法載入books.xml文件,獲取docuemnt對象。 23 Document document = reader.read(new File("book.xml")); 24 // 通過document對象獲取根節點bookstore 25 Element bookStore = document.getRootElement(); 26 System.out.println("根節點名:"+bookStore.getName()); 27 // 通過element對象的elementIterator方法獲取迭代器 28 Iterator it = bookStore.elementIterator(); 29 // 遍歷迭代器,獲取根節點中的信息(書籍) 30 while (it.hasNext()) { 31 System.out.println("=====開始遍歷子節點====="); 32 Element book = (Element) it.next(); 33 System.out.println("子節點名:"+book.getName()); 34 // 獲取book的屬性名以及 屬性值 35 List<Attribute> bookAttrs = book.attributes(); 36 for (Attribute attr : bookAttrs) { 37 System.out.println("屬性名:" + attr.getName() + "--屬性值:" 38 + attr.getValue()); 39 } 40 Iterator itt = book.elementIterator(); 41 while (itt.hasNext()) { 42 Element bookChild = (Element) itt.next(); 43 System.out.println("節點名:" + bookChild.getName() + "--節點值:" + bookChild.getStringValue()); 44 } 45 System.out.println("=====結束遍歷該節點====="); 46 } 47 } catch (DocumentException e) { 48 e.printStackTrace(); 49 } 50 } 51 52 }
運行結果:


