
英文分詞的第三方庫NLTK不錯,中文分詞工具也有很多(盤古分詞、Yaha分詞、Jieba分詞等)。但是從載入自定義字典、多線程、自動匹配新詞等方面來看。 大jieba 確實是中文分詞中的 戰鬥機 。 請隨意觀看表演 "安裝" "分詞" "自定義詞典" "延遲載入" "關鍵詞提取" "詞性標註" "詞 ...
英文分詞的第三方庫NLTK不錯,中文分詞工具也有很多(盤古分詞、Yaha分詞、Jieba分詞等)。但是從載入自定義字典、多線程、自動匹配新詞等方面來看。
大jieba確實是中文分詞中的戰鬥機。
請隨意觀看表演
安裝
- 使用pip包傻瓜安裝:
py -3 -m pip install jieba/pip install jiba(windows下推薦第一種,可以分別安裝python2和3對應jieba) - pypi下載地址
分詞
3種模式
- 精確模式:試圖將句子最精確地切開,適合文本分析
- 全模式:把句子中所有的可以成詞的詞語都掃描出來(速度快)
- 搜索引擎模式:在精確模式的基礎上,對長詞再次切分,提高召回率,適合用於搜索引擎分詞
實現方式
- 精確模式:
jieba.cut(sen) - 全模式:
jieba.cut(sen,cut_all=True) - 搜索引擎模式:
jieba.cut_for_search(sen)
import jieba
sen = "我愛深圳大學"
sen_list = jieba.cut(sen)
sen_list_all = jieba.cut(sen,cut_all=True)
sen_list_search = jieba.cut_for_search(sen)
for i in sen_list:
print(i,end=" ")
print()
for i in sen_list_all:
print(i,end=" ")
print()
for i in sen_list_search:
print(i,end=" ")
print()結果:附截圖

自定義詞典
創建方式
- 尾碼:txt
- 格式:詞語( 權重 詞性 )
- 註意事項:
- windows下txt不能用自帶的編輯器,否則會亂碼。可以用VSCODE,或者其他編輯器
- 可以只有詞語
- 在沒有權重的情況下,只有比預設詞典長的詞語才可以載入進去。附截圖

載入字典
jieba.load_userdict(txtFile)
調整字典
添加詞:jieba.add_word(word,freq=None,tag=None)
刪除詞:jieba.del_word(word)
import jieba
sen = "膠州市市長江大橋"
sen_list = jieba.cut(sen)
for i in sen_list:
print(i,end=" ")
print()膠州市 市 長江大橋jieba.add_word('江大橋',freq=20000)
sen_list = jieba.cut(sen)
for i in sen_list:
print(i,end=" ")
print()結果附截圖

改變主字典
- 占用記憶體較小的詞典文件
- 支持繁體分詞更好的詞典文件
- 載入方法:
jieba.set_dictionary('data/dict.txt.big')
延遲載入
之前發現,詞典不是一次性載入的,說明它採用的是延遲載入。即:當遇到應用的時候才會載入。有點類似於python高級特性中的
yield(節省記憶體)
效果圖如下:
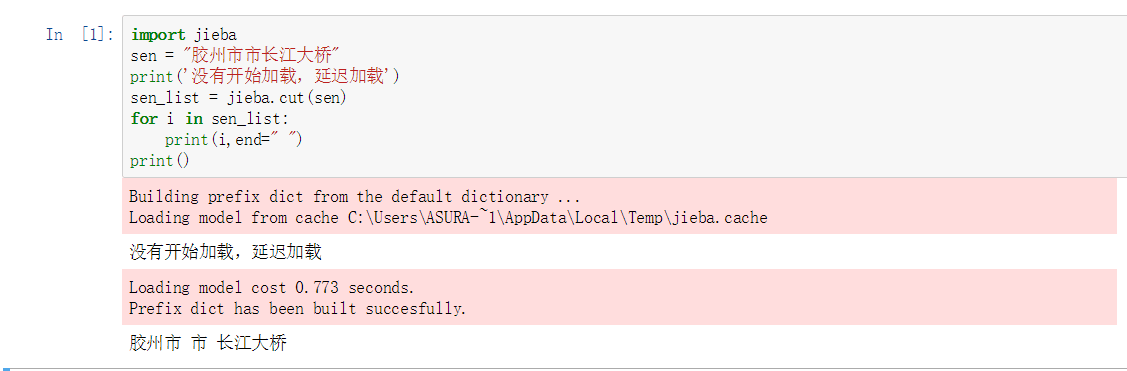
- 手動載入的方法:
jieba.initialize()
關鍵詞提取
jieba.analyse.extract_tags(sentence,topK=20):返回topK個TF/IDF權重最大的詞語
import jieba.analyse
sen_ana = jieba.analyse.extract_tags(sen,3)
for i in sen_ana:
print(i)江大橋
膠州市
市長詞性標註
jieba.posseg.cut(sen):返回的每個迭代對象有兩個屬性-> word 詞語 + flag 詞性
import jieba.posseg
words = jieba.posseg.cut(sen)
for word in words:
print(word.flag," ",word.word)ns 膠州市
n 市長
x 江大橋詞語定位
jieba.tokenize(sen,mode):mode可以設置為search,開啟搜索模式
index= jieba.tokenize(sen)
for i in index:
print(i[0],"from",i[1],"to",i[2])膠州市 from 0 to 3
市長 from 3 to 5
江大橋 from 5 to 8內部演算法
- 基於Trie樹結構實現高效的詞圖掃描,生成句子中漢字所有可能成詞情況所構成的有向無環圖(DAG)
- 採用了動態規劃查找最大概率路徑, 找出基於詞頻的最大切分組合
- 對於未登錄詞,採用了基於漢字成詞能力的HMM模型,使用了Viterbi演算法。


