
前面很多篇不管CPU、記憶體、磁碟、語句等等等都提到了索引的重要,我想剛剛開始學資料庫的在校學生都知道索引對語句性能的重要性。但他們可能不知道,對語句的重要性就是對系統的重要性! 開篇小測驗 開篇小測驗 下麵這樣一個小SQL 你該怎麼樣添加最優索引 你是否一眼就能看出來呢? 答案將在文章中逐步揭曉~~ ...
前面很多篇不管CPU、記憶體、磁碟、語句等等等都提到了索引的重要,我想剛剛開始學資料庫的在校學生都知道索引對語句性能的重要性。但他們可能不知道,對語句的重要性就是對系統的重要性!
-
開篇小測驗
下麵這樣一個小SQL 你該怎麼樣添加最優索引
兩個表上現在只有聚集索引
bigproduct 表上已經有聚集索引 ProductID
bigtransactionhistory 表上已經有聚集索引 TransactionID
select p.productnumber,p.reorderpoint,th.Quantity from bigproduct as p join bigtransactionhistory as th on th.productid=p.productid and th.TransactionDate > p.SellStartDate where p.name in ('LL Crankarm1000','ML Crankarm1000') and th.TransactionDate > '2010-01-01'
你是否一眼就能看出來呢?
答案將在文章中逐步揭曉~~~
-
簡單粗暴的添加索引
看過我前面文章的看官們一定會發現我很喜歡用“簡單粗暴”這個詞,一是因為辭彙量小文筆也差,真心用不出高大上的詞兒! 再一個,你們不喜歡簡單粗暴麽~~乾貨最重要,不是麽?
首先我們看一下沒有優化前的執行計劃
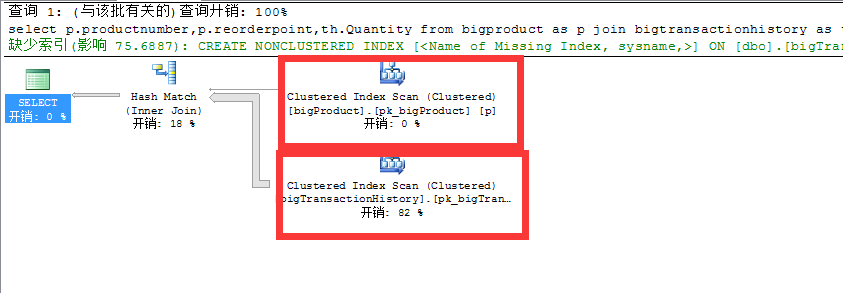

clustered index scan 這其實就是表掃描,不是table scan 只是因為表上有聚集索引
可以看出這個查詢倆表都使用了表掃描!
where 條件添加索引
首先大多數人都知道 where 條件中的欄位需要添加索引! 我們添加一下看看效果創建
在 bigproduct 表上創建 name 列索引 ,在bigtransactionhistory表上創建 TransactionDate 列索引。
再次執行語句看一下效果!
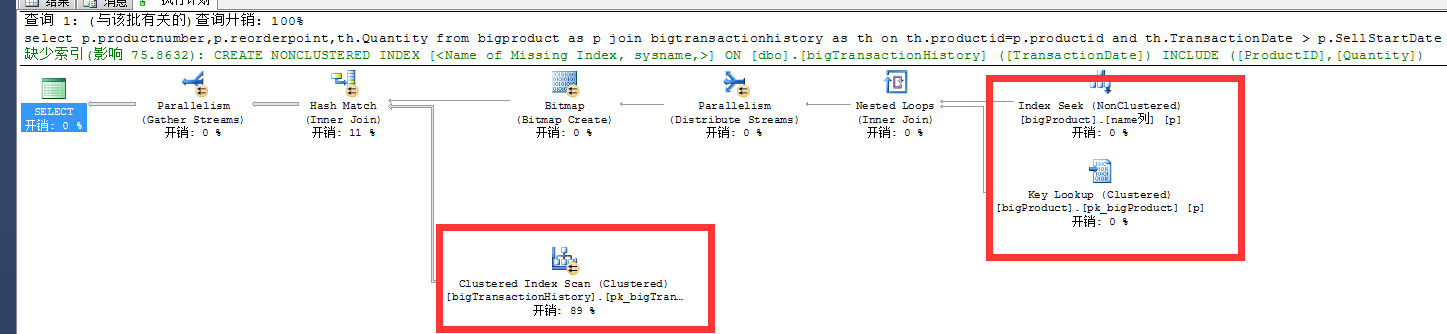

添加where索引以後可以看到以下幾個現象
- bigproduct 從原來的clustered index scan 變成 index seek
- 另外多出來個KEY Lookup(clustered)
- bigproduct 上添加的索引起了作用,邏輯讀bigproduct 由 601 變成 10。
- bigtransactionhistory 沒啥變化啊 還是clustered index scan
解釋一下出現的現象 : 首先一點bigproduct 邊添加的where 條件索引,起到了作用,執行的時候不是全表掃描了,邏輯讀有明顯的下降,出現的 KEY Lookup 是因為選擇(select)的列,在索引中沒有,而需要通過聚集索引再查找一次,再找一次也意味著多一部分開銷!
那麼同樣添加了where 條件索引的bigtransactionhistory 表為什麼沒起作用呢? 那是因為SQL優化器在選擇計劃的時候認為,不使用TransactionDate 列索引查找效率會更好!
真的麽? 我們來驗證一下,通過指定選擇索引,來讓優化器選擇索引查找!
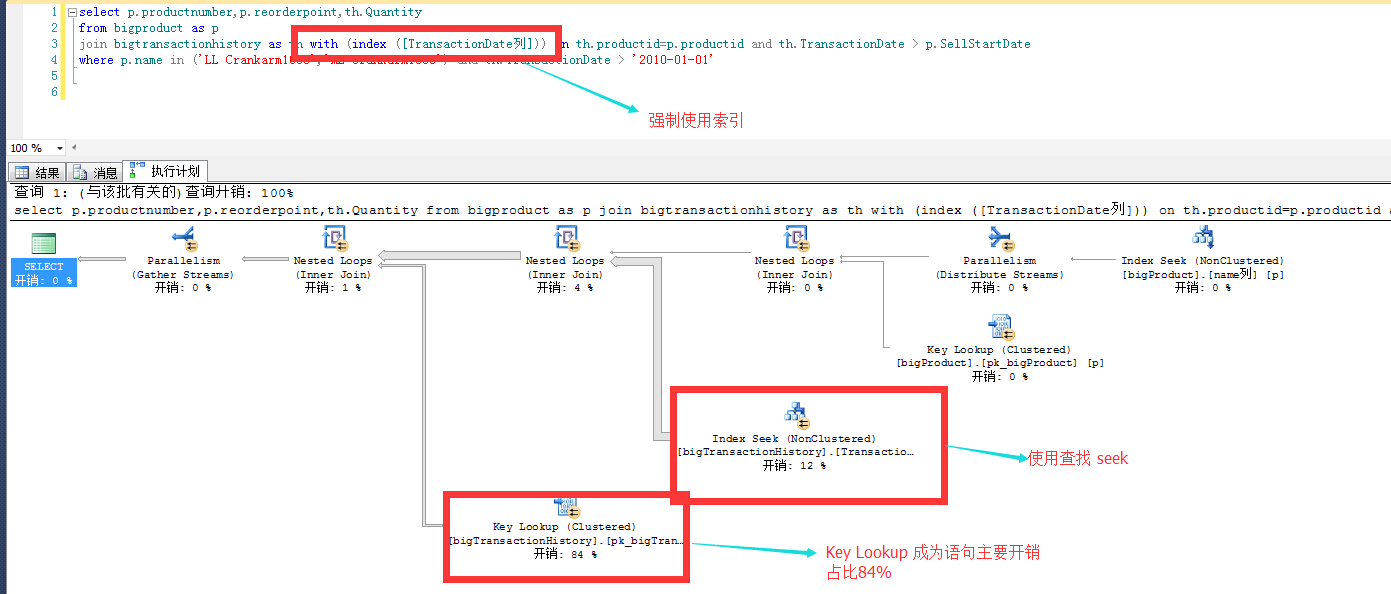

強制使用索引以後,可以看出邏輯讀由 14W 變成1961W,語句時間也變得很長,這就是優化器為什麼不選用你加的索引!優化器還是很智能的吧。
高能預警:優化器可不是什麼時候都這麼智能的...由於緩存計劃或優化器抽風等原因,也會出現優化器用了這種索引,導致你的語句奇慢,讀飆升直接影響到你的記憶體、磁碟、CPU資源!另外如果這樣一條語句是系統中一條很頻繁運行的語句,你的系統就掛了!沒錯就掛了!這就是開篇拋出的問題就是因為一條語句!
消滅Key Lookup 添加select 欄位
這就是傳說中的覆蓋索引!
看到執行計劃中存在Key Lookup 而且消耗占比很高,如上面強制索引的計劃,那麼我們就要想到的 在索引中包含那些SELECT 的列!如果消耗低,邏輯讀少,如上面bigproduct 表中的Key Lookup 就可以忽略(如果你追求完美,也一樣優化就可以了)。
包含列的圖形化創建 :
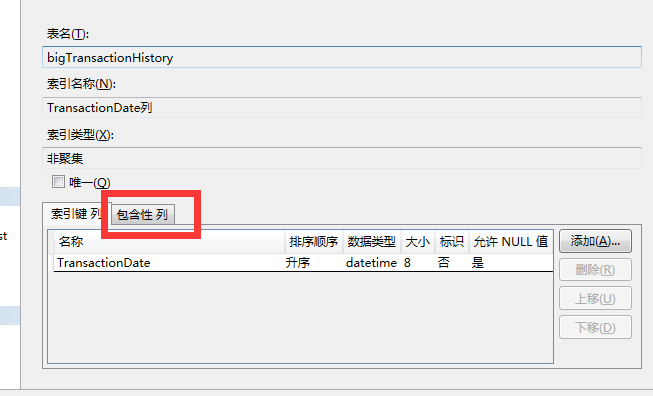
語句創建就是 :
CREATE NONCLUSTERED INDEX TransactionDate ON [dbo].[bigTransactionHistory] ([TransactionDate]) ------INCLUDE 就是包含列 INCLUDE ([ProductID],[Quantity]) GO
下麵我們添加一下看看效果 :


添加select 索引欄位後可以看出的現象:
- 優化器自己選擇了index seek
- bigtransactionhistory占比最高的Key Lookup消失了
- 邏輯讀由原來無索引的14W變成1W
- bigtransactionhistory表還提示缺少索引?
通過優化索引添加select 欄位,我們看出語句又一次得到了提升 bigtransactionhistory 從表掃描變成索引查找,邏輯讀由14W變成 1W!這是一個質的飛躍啊!
那為什麼還提示缺少索引呢? 創建一下試試吧!
索引再優化加入表關聯列
按照提示我們創建索引 : 和上一個索引的不同 ProductID 列由包含列變成了索引列!
USE [AdventureWorks2012] GO CREATE NONCLUSTERED INDEX ProductID_TransactionDate ON [dbo].[bigTransactionHistory] ([ProductID],[TransactionDate]) INCLUDE ([Quantity])
我們看一下效果:
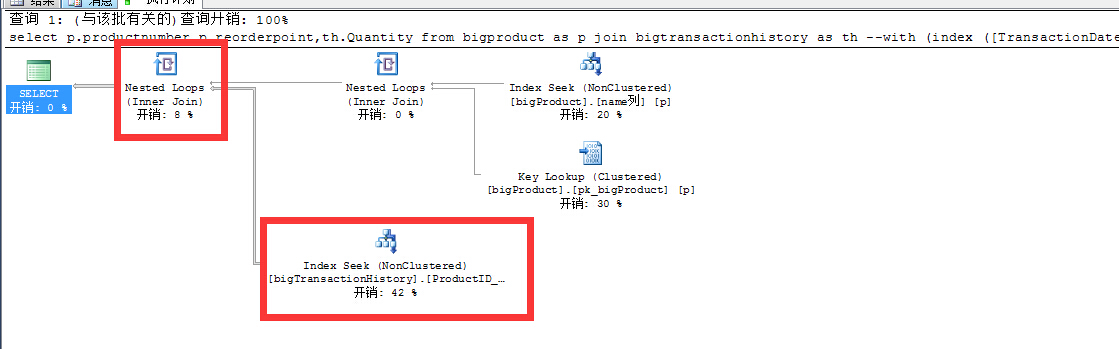

再次優化索引以後可以看到以下幾個現象
- bigtransactionhistory表還是索引查找index seek
- bigtransactionhistory依然沒有了Key Lookup
- 兩表關聯的hash join 變成了nested loops
- 並行計劃變成了串列
- 邏輯讀又從1W 變成18
又一次質的飛躍!讀從原來的14W 變成1W 又變成18,這樣大大減少了記憶體和IO的消耗,另外並行計劃也變成了串列,無疑又減少了大量CPU的消耗!語句時間,我想這裡就不用多說了吧?
高能預警:這裡所說的hash join,並行變串列,不懂的朋友可以在百度自行學習,這裡只是針對當前語句的情況,不能一概而論!
精簡你的索引
大家都知道,索引會導致update、insert、delete操作變慢!那麼儘量精簡你的索引就是一個很重要的話題了!
上面的優化過程中我們創建了幾個索引,以bigTransactionHistory為例來看一下:

腳本這裡就不貼了,其實我們最後創建的索引 ProductID_TransactionDate包含Quantity 已經包含了前兩個索引,而且可以說無論任何類似語句都使用ProductID_TransactionDate包含Quantity 就可以了!
那麼我們就可以清除前兩個索引!
至此語句的優化算是結束了,留下的就是bigproduct 依然有一個Key Lookup可以優化,可以仿照上面的繼續優化,這裡就不細說了。語句只是經過了簡單的索引優化就從一輛2手QQ變成了法拉利,是不是很神奇?
這就是索引的重要性!
開篇小測試你做對了麽?如果沒做對那麼這麼請你自行模擬一個場景再現本篇的話題吧!
-----------------------------------------------------------------------------------------------------
總結 : 往往一個系統的整體緩慢都是因為索引問題導致的,優化索引是對你系統最簡單的保養!
不要小看一條語句的威力,一條語句足可以讓你的系統徹底無法工作!
一個問題隨之而來語句一條一條漫無目的的優化麽?我怎麼找出系統的問題語句?怎麼樣的一個優先順序?


