
mysql的索引是通過B+tree的方式的。B+tree是平衡二叉樹的變種,所以查詢的速度是非常快的。(B+tree :https://zh.wikipedia.org/zh-hans/B%2B%E6%A0%91) 索引主要分為聚集索引和輔助索引: 聚集索引:mysql中的數據是通過主鍵的聚集索引儲 ...
mysql的索引是通過B+tree的方式的。B+tree是平衡二叉樹的變種,所以查詢的速度是非常快的。(B+tree :https://zh.wikipedia.org/zh-hans/B%2B%E6%A0%91)
索引主要分為聚集索引和輔助索引:
聚集索引:mysql中的數據是通過主鍵的聚集索引儲存的,葉子節點中存放的就是每一行的數據,所以我們通過主鍵進行查詢速度
如初快的原因就是主鍵是聚集索引,而實際使用中只會構建一顆這樣的B+tree,所以這就可以解釋為什麼主鍵唯一了。
引用網上的圖:
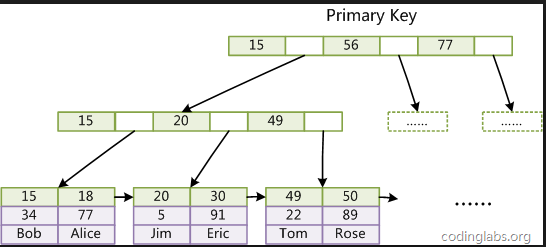
每一層的查找就是一次的IO操作,而一般B+tree層數都在2-4層 所以相當於最差的情況下,只需要做4次的IO操作。
輔助索引:輔助索引和聚集索引不同的地方在於葉子節點中儲存的不是全部的數據,儲存的是數據所在的位置。相當於我們使用了
輔助索引查找到數據之後,還需要在通過聚集索引的樹查找詳細的信息。
引用網上的圖:
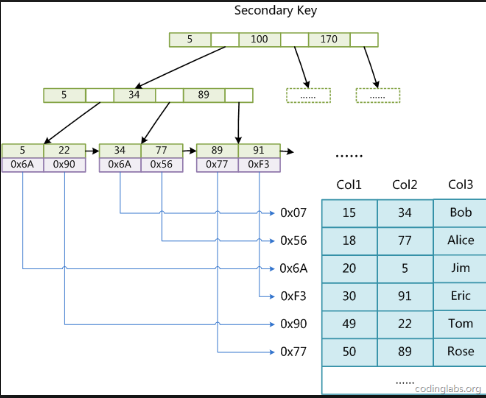
這個圖是一個邏輯上的圖,但是底層是通過葉子節點指向了所在的聚集索引,也就是說,接下麵還需要在走一遍第一種圖的
邏輯。
所以最終的是多個輔助索引樹指向一個聚集索引樹
(畫的真tm醜)
關於什麼時候應該創索引
因為這是一棵樹,通過二分查找的方式來進行檢索,所以適用在作為where後面的條件時,並且這個值是很大範圍內的,適合創建索引。對於那些範圍很小的的(is_delete,sex等等枚舉)是不適合的。
對於具體的情況,我們可以通過show index來進行分析:
show index from company_related_person
結果:

然後通過cardinality計算
select 105/(select count(*) from company_related_person) from DUAL
這裡得到的結果是0.913(這個數值和儲存量有關,最好有一定的數據量) 這個數值越接近1 索引的效率就越高,如果求出的值非常小,建議不要創建索引
我們可以同時可以通過explain查看索引的使用情況
EXPLAIN select * from company_related_person where company_id='2'
輸出

key表示的就是當前使用的索引列。最後的extra表示的就是使用何種方式,這裡是 Using index 表示的就是使用了索引,如果Using filesort 表示的就是直接讀磁碟了
對於那些查詢慢的sql複雜語句,可以通過這種方式進行分析。
SQL性能優化的目標:至少要達到 range 級別,要求是ref級別,如果可以是consts最好。
1)consts 單表中最多只有一個匹配行(主鍵或者唯一索引),在優化階段即可讀取到數據。
2)ref 指的是使用普通的索引(normal index)。
3)range 對索引進行範圍檢索
4) index 表示的是直接去磁碟中讀取
從上面的那種圖也可以看到我們使用的是ref
關於index和key的區別:
在我們創建索引的時候,經常會有這個疑問,index和key有什麼區別?。Key即鍵值,是關係模型理論中的一部份,比如有主鍵(Primary Key),外鍵(Foreign Key)等,用於數據完整性檢否與唯一性約束等。而Index則處於實現層面,比如可以對錶個的任意列建立索引,那麼當建立索引的列處於SQL語句中的Where條件中時,就可以得到快速的數據定位,從而快速檢索。至於Unique Index,則只是屬於Index中的一種而已,建立了Unique Index表示此列數據不可重覆

