
[1]定義 [2]NodeIterator [3]TreeWalker ...
前面的話
DOM遍歷模塊定義了用於輔助完成順序遍歷DOM結構的類型:Nodeiterator和TreeWalker,它們能夠基於給定的起點對DOM結構執行深度優先(depth-first)的遍歷操作。本文將詳細介紹DOM遍歷
[註意]IE8-瀏覽器不支持
定義
DOM遍歷是深度優先的DOM結構遍歷,遍歷以給定節點為根,不可能向上超出DOM樹的根節點。以下麵的HTML頁面為例
<!DOCTYPE html> <html> <head> <title>Example</title> </head> <body> <p><b>Hello</b> world!</p> </body> </html>
下圖展示了這個頁面的DOM樹
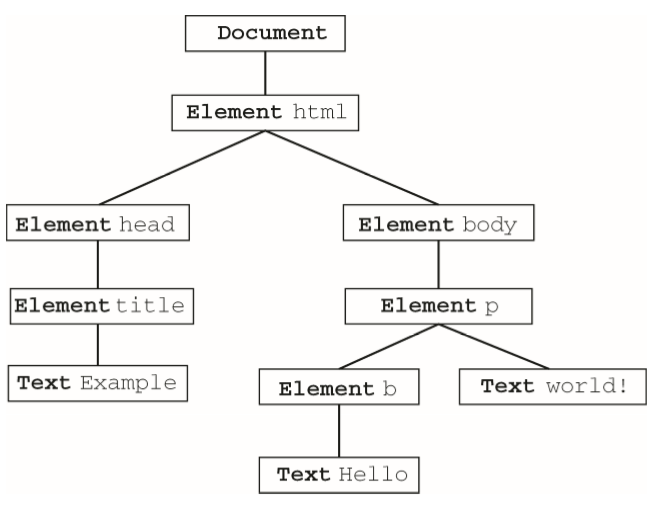
任何節點都可以作為遍歷的根節點,如果假設<body>元素為根節點,那麼遍歷的第一步就是訪問<p>元素,然後再訪問同為<body>元素後代的兩個文本節點。不過,這次遍歷永遠不會到達<html>、<head>元素,也不會到達不屬於<body>元素子樹的任何節點。而以document為根節點的遍歷則可以訪問到文檔中的全部節點
下圖展示了對以document為根節點的DOM樹進行深度優先遍歷的先後順序
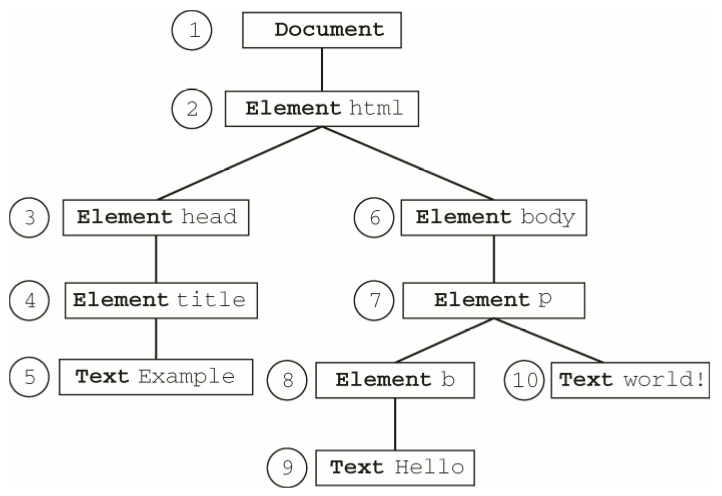
從document開始依序向前,訪問的第一個節點是document,訪問的最後一個節點是包含"world!"的文本節點。從文檔最後的文本節點開始,遍歷可以反向移動到DOM樹的頂端。此時,訪問的第一個節點是包含"Hello"的文本節點,訪問的最後一個節點是document節點。Nodeiterator和TreeWalker都以這種方式執行遍歷
NodeIterator
可以使用document.createNodeIterator()方法創建NodeIterator類型的新實例。這個方法接受下列4個參數
root:想要作為搜索起點的樹中的節點
whatToShow:表示要訪問哪些節點的數字代碼
filter:是一個NodeFilter對象,或者一個表示應該接受還是拒絕某種特定節點的函數
entityReferenceExpansion:布爾值,表示是否要擴展實體引用。這個參數在HTML頁面中沒有用,因為其中的實體引用不能擴展
whatToshow參數是一個位掩碼,通過應用一或多個過濾器(filter)來確定要訪問哪些節點。這個參數的值以常量形式在NodeFilter類型中定義,如下所示
NodeFilter.SHOW_ALL:顯示所有類型的節點
NodeFilter.SHOW_ELEMENT:顯示元素節點
NodeFilter.SHOW_ATTRIBUTE:顯示特性節點。由於DOM結構原因,實際上不能使用這個值
NodeFilter.SHOW_TEXT:顯示文本節點
NodeFilter.SHOW_CDATA_SECTION:顯示CDATA節點。對HTML頁面沒有用
NodeFilter.SHOW_ENTITY_REFERENCE:顯示實體引用節點。對HTML頁面沒有用
NodeFilter.SHOW_ENTITYE:顯示實體節點。對HTML頁面沒有用
NodeFilter.SH0W_PROCESSING_INSTRUCTION:顯示處理指令節點。對HTML頁面沒有用
NodeFi1ter.SHOW_COMMENT:顯示註釋節點
NodeFilter.SHOW_DOCUMENT:顯示文檔節點
NodeFilter.SHOW_DOCUMENT_TYPE:顯示文檔類型節點
NodeFilter.SHOW_DOCUMENT_FRAGMENT:顯示文檔片段節點。對HTML頁面沒有用
NodeFilter.SHOW_NOTATION:顯示符號節點。對HTML頁面沒有用
除了NodeFilter.SHOW_ALL之外,可以使用按位或操作符來組合多個選項,如下所示:
var whatToShow = NodeFilter.SHOW_ELEMENT | NodeFilter.SHOW_TEXT;
可以通過createNodeIterator()方法的filter參數來指定自定義的NodeFilter對象,或者指定一個功能類似節點過濾器(node filter)的函數。每個NodeFilter對象只有一個方法,即acceptNode();如果應該訪問給定的節點,該方法返回NodeFilter.FILTER_ACCEPT,如果不應該訪問給定的節點,該方法返回NodeFilter.FILTER_SKIP。由於NodeFilter是一個抽象的類型,因此不能直接創建它的實例。在必要時,只要創建一個包含acceptNode()方法的對象,然後將這個對象傳入createNodeIterator()中即可
下列代碼展示瞭如何創建一個只顯示<p>元素的節點迭代器
var filter = {
acceptNode:function(node){
return node.tagName.toLowerCase() == "p" ? NodeFilter.FILTER_ACCEPT : NodeFilter.FILTER_SKIP;
}
}
var iterator = document.createNodeIterator(root, NodeFilter.SHOW_ELEMENT, filter, false);
第三個參數也可以是一個與acceptNode()方法類似的函數,如下所示
var filter = function(node){
return node.tagName.toLowerCase() == "p" ? NodeFilter.FILTER_ACCEPT : NodeFilter.FILTER_SKIP;
}
var iterator = document.createNodeIterator(root, NodeFilter.SHOW_ELEMENT, filter, false);
一般來說,這就是在javascript中使用這個方法的形式,這種形式比較簡單,而且也跟其他的javascript代碼很相似。如果不指定過濾器,那麼應該在第三個參數的位置上傳入null
下麵的代碼創建了一個能夠訪問所有類型節點的簡單的NodeIterator
var iterator = document.createNodeIterator(document, NodeFilter.SHOW_ALL, null, false);
NodeIterator類型的兩個主要方法是nextNode()和previousNode()。顧名思義,在深度優先的DOM子樹遍歷中,nextNode()方法用於向前前進一步,而previousNode()用於向後後退一步
在剛剛創建的NodeIterator對象中,有一個內部指針指向根節點,因此第一次調用nextNode()會返回根節點。當遍歷到DOM子樹的最後一個節點時,nextNode()返回null。previousNode()方法的工作機制類似。當遍歷到DOM子樹的最後一個節點,且previousNode()返冋根節點之後,再次調用它就會返回null
以下麵的HTML片段為例
<div id="div1"> <p><b>Hello</b> world!</p> <ul> <li>List item 1</li> <li>List item 2</li> <li>List item 3</li> </ul> </div>
假設我們想要遍歷<div>元素中的所有元素,那麼可以使用下列代碼
var div = document.getElementById("div1");
var iterator = document.createNodeIterator(div, NodeFilter.SHOW_ELEMENT, null, false);
var node = iterator.nextNode();
while(node !== null) {
console.log(node.tagName); //輸出標簽名
node = iterator.nextNode();
}
在這個例子中,第一次調用nextNode()返回<p>元素。因為在到達DOM子樹末端時nextNode()返回null,所以這裡使用了while語句在每次迴圈時檢查對nextNode()的調用是否返回了null
如果只想返回遍歷中遇到的<li>元素。只要使用一個過濾器即可,如下所示
var div = document.getElementById("div1");
var filter = function(node){
return node.tagName.toLowerCaee() == "li" ? NodeFilter.FILTER_ACCEPT : NodeFilter.FILTER_SKIP;
};
var iterator = document.createNodeIterator(div, NodeFilter.SHOW_ELEMENT, filter, false);
var node = iterator.nextNode();
while(node !== null) {
console.log(node.tagName);//輸出標簽名
node = iterator.nextNode();
}
在上面這個例子中,迭代器只會返回<li>元素
由於nextNode()和previousNode()方法都基於NodeIterator在DOM結構中的內部指針工作,所以DOM結構的變化會反映在遍歷的結果中
TreeWalker
TreeWalker是NodeIterator的一個更高級的版本。除了包括nextNode()和previousNode()在內的相同的功能之外,這個類型還提供了下列用於在不同方向上遍歷DOM結構的方法
parentNode():遍歷到當前節點的父節點
firstChild():遍歷到當前節點的第一個子節點
lastChild():遍歷到當前節點的最後一個子節點
nextSibling():遍歷到當前節點的下一個同輩節點
previousSibling():遍歷到當前節點的上一個同輩節點
創建TreeWalker對象要使用document.createTreeWalker()方法,這個方法接受的4個參數與document.createNodelterator()方法相同:作為遍歷起點的根節點、要顯示的節點類型、過濾器和一個表示是否擴展實體引用的布爾值。由於這兩個創建方法很相似,所以很容易用TreeWalker來代替NodeIterator,如下所示
var div = document.getElementById("div1");
var filter = function(node){
return node.tagName.toLowerCase() == "li"? NodeFilter.FILTER_ACCEPT : NodeFilter.FILTER_SKIP;
}
var walker = document.createTreeWalker(div,NodeFilter.SHOW_ELEMENT, filter, false);
var node = walker.nextNode();
while(node !== null) {
console.log(node.tagName);//輸出標簽名
node = walker.nextNode();
}
在這裡,filter可以返回的值有所不同。除了NodeFilter.FILTER_ACCEPT和NodeFilter.FILTER_SKIP之外,還可以使用NodeFilter.FILTER_REJECT。在使用NodeIterator對象時,NodeFilter.FILTER_SKIP與NodeFilter.FILTER_REJECT的作用相同:跳過指定的節點。但在使用TreeWalker對象時,NodeFilter.FILTER_SKIP會跳過相應節點繼續前進到子樹中的下一個節點,而NodeFilter.FILTER_REJECT則會跳過相應節點及該節點的整個子樹。例如,將前面例子中的NodeFilter.FILTER_SKIP修改成NodeFilter.FILTER_REJECT,結果就是不會訪問任何節點。這是因為第一個返回的節點是<div>,它的標簽名不是"li",於是就會返回NodeFilter.FILTER_REJECT,這意味著遍歷會跳過整個子樹。在這個例子中,<div>元素是遍歷的根節點,於是結果就會停止遍歷
當然,TreeWalker真正強大的地方在於能夠在DOM結構中沿任何方向移動。使用TreeWalker遍歷DOM樹,即使不定義過濾器,也可以取得所有<li>元素,如下所示
var div = document.getElementById("div1"); var walker = document.createTreeWalker(div, NodeFilter.SHOW_ELEMENT, null, false); walker.firstChild();//轉到<p> walker.nextSibling();//轉到<ul> var node = walker.firstChild(); //轉到第一個<li> while(node !== null){ console.log(node.tagName); node = walker.nextSibling(); }
因為我們知道<li>元素在文擋結構中的位置,所以可以直接定位到那裡,即使用firstChild()轉到<p>元素,使用nextSibling()轉到<ul>元素,然後再使用firstchild()轉到第一個<li>元素
[註意]此處TreeWalker只返回元素(由傳入到createTreeWalker()的第二個參數決定)。因此,可以放心地使用nextSibling()訪問每一個<li>元素,直至這個方法最後返回null
TreeWalker類型還有一個屬性,名叫currentNode,表示任何遍歷方法在上一次遍歷中返回的節點。通過設置這個屬性也可以修改遍歷繼續進行的起點,如下所示
var node = walker.nextNode();
console.log(node === walker.currentNode);//true
walker.currentNode = document.body; //修改起點
與NodeIterator相比,TreeWalker類型在遍歷DOM時擁有更大的靈活性。由於IE8-瀏覽器中沒有對應的類型和方法,所以使用遍歷的跨瀏覽器解決方案非常少見


