
本文由博主原創,轉載請註明出處:我的博客-知乎爬蟲之爬蟲流程設計 git爬蟲項目地址(關註和star在哪裡~~):https://github.com/MatrixSeven/ZhihuSpider (已完結) 附贈之前爬取的數據一份(mysql): 鏈接:https://github.com/Ma ...
本文由博主原創,轉載請註明出處:我的博客-知乎爬蟲之爬蟲流程設計
git爬蟲項目地址(關註和star在哪裡~~):https://github.com/MatrixSeven/ZhihuSpider (已完結)
附贈之前爬取的數據一份(mysql): 鏈接:https://github.com/MatrixSeven/ZhihuSpider/README.MD 只下載不點贊,不star,差評差評~藍瘦香菇)
(Ps:這個思路有問題,實際上並不是這麼搞得代碼,後續補上)
說到爬蟲,其實寫起來很簡單,爬蟲無非就是將自己想要的內容在頁面上抽離出來,並且存儲。這個過程在今天已經變得非常輕鬆,在Java下有Jsoup,Python下有BS4,還有通吃的正則等等,然而真正難的卻是在於偽造請求,截獲分析請求參數,獲取正確的頁面.
首先來說,一個能混得過去的爬蟲,應該有一個優秀的流程,在明確自己的目標後,應該立馬去設計爬蟲工作流程,而不是去無腦的Coding。
那麼今天咱們就先研究下咱們這個爬蟲的目標和流程。
首先咱們是要獲取知乎頁面上的個人信息,關註和被關註信息,首先咱們會遇到第一個問題就是登陸,咱們這裡暫且不講,
其次咱們就是要給定一個初始化url,然後進行followers的和followees的獲取,然後迴圈爬起來,那麼其中一定會遇到數據重覆和人物關係建立的問題。
1.過濾重覆數據
這個相對而言比較簡單,有幾種常規方法:
1. 資料庫設置主鍵,鎖定人物ID
2. 存入數據時查詢資料庫數據
3. 使用緩存隊列,在緩存中查找數據判斷
首先來說第一種,資料庫設置主鍵,鎖定人物ID,這個方法可以使數據永遠不重覆,但是也會造成批量插入的時候造成出錯
第二種方法,存入數據時查詢資料庫數據,可行,但是多次訪問資料庫,造成效率低下
第三種方法,使用緩存隊列,在緩存中查找數據判斷,這種方法很好,而且速度相對較快,但是緩存太多容易出現OOM問題
在這裡咱們不選擇某一種方案,而是採用主鍵+優先緩存+資料庫查詢方式,後期自己實現一個LRU緩存隊列,提供命中率
2. 爬取時創建人物關係
這個問題思考了很久,也比較噁心,在人物不確定的情況下進行人物的獲取和關係的創建,怎麼處理好呢。我的想法是讓每一個人員信息攜帶一個上級信息,來判斷是否能夠構建人物關係,有點類似於尾遞歸的思想。
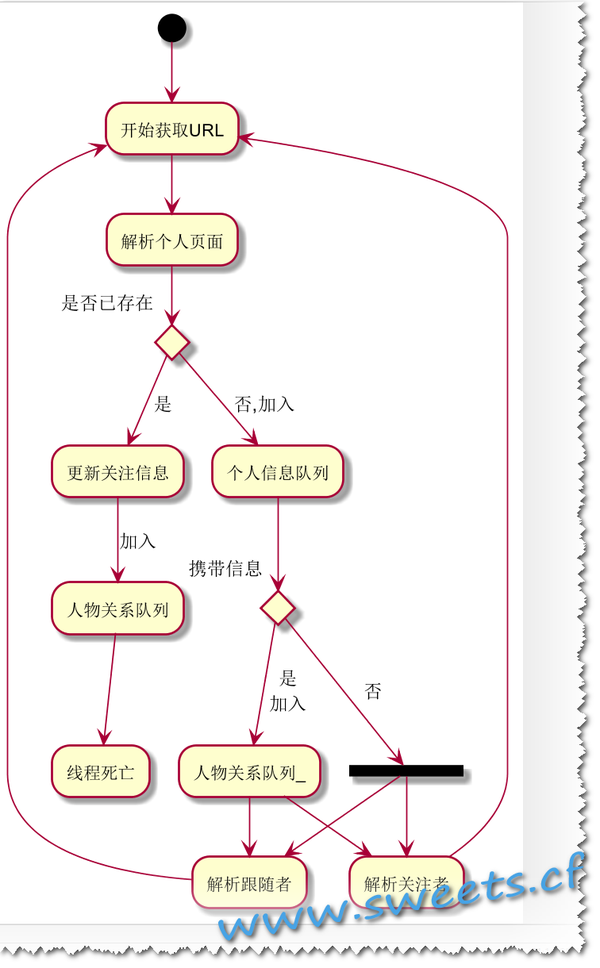
3. 繪製流程圖
那麼對於咱們的一個整體流程目前就有了(挑戰一下,還是放棄了、哈哈):
獲取URL-->解析頁面<--------
| |
| |
是否存在 |
/\ |
/ \ |
更新 攜帶 |
數據 信息 |
/\ |
/ \ |
跟隨 關註 |
信息 信息----
獲取URL–》解析—》判斷—》更新/攜帶信息?—》分析跟隨者/根系關註者–》解析頁面
最終畫出真正的流程圖
//吾愛Java(QQ群):170936712(點擊加入)


