
最經想改寫C用的配置讀取介面, 準備採用hash或二叉樹提到原先用的鏈表,提高查找效率. 就回顧一下二叉樹,這裡分享一下二叉查找樹,代碼很精簡的, 適合學習運用二叉樹查找.
前言
最經想改寫C用的配置讀取介面, 準備採用hash或二叉樹提到原先用的鏈表,提高查找效率.
就回顧一下二叉樹,這裡分享一下二叉查找樹,代碼很精簡的, 適合學習運用二叉樹查找.
需要基礎
1.具備C基礎知識
2.知道數據結構,最好知道一點二叉樹結構
能夠學到
1.穩固二叉查找樹
2.C良好編碼格式習慣
3.tree 數據結構幾種流行套路(設計)
參照
1.二叉查找樹簡單分析 http://www.cppblog.com/cxiaojia/archive/2012/08/09/186752.html
(上面那個博文, 圖形講解的恨透,但是那種tree數據結構,不要參照)
正文
1 直接奔主題 說二叉查找樹難點
1.1 簡單說一下二叉查找樹原理和突破
二叉樹也是個經典的數據結構,但是工作中用的場景不多,但是我們常用過,例如map,自帶排序的k-v結構.
二叉樹相比雙向鏈表在改變了插入和刪除方式,使查找代價變小.因而適用領域在快速查找的領域.對於那種快速刪除,
快速插入的領域並不適合.
我們今天主要回顧的是二叉查找(搜索)樹. 首先看看數據結構如下
/* * 這裡簡單的溫故一下 , 二叉查找樹 *一切從簡單的來吧 */ typedef int node_t; typedef struct tree { node_t v; //這裡簡單測試一下吧,從簡單做起 struct tree* lc; struct tree* rc; } *tree_t;
上面比較簡陋,不是很通用,方便瞭解原理設計,最後會帶大家設計一些通用的二叉樹結構. 這裡扯一點,
結構會影響演算法,演算法依賴特定的結構.蛋和雞的問題,先有一個不好的蛋,孵化一個不好的雞,後來雞下了很多蛋,其中一個蛋很好,
孵化了一個很好的雞,最後蛋雞良好迴圈出現了.
對於二叉查找樹,除了刪除比較複雜一點,其它的還是很大眾的代碼,這裡從如何找到一個結點的父節點出發.看下麵代碼
/* * 查找這個結點的父結點 * root : 頭結點 * v : 查找的結點 * : 返回這個v值的父親結點,找不見返回NULL,可以返回孩子結點 */ tree_t tree_parent(tree_t root, node_t v, tree_t* pn) { tree_t p = NULL; while (root) { if (root->v == v) break; p = root; if (root->v > v) root = root->lc; else root = root->rc; } if (pn) //返回它孩子結點 *pn = root; return p; }
本質思路是,構建一個指針p保存上一個結點.這個函數相比其它函數 tree_parent 這裡多返回當前的孩子結點.一個函數順帶做了兩件事.
這是一個突破.推薦學習,同等代價做的事多了,價值也就提升了.
下麵說一下 二叉查找樹 刪除原理(從上面參照文中截得,這個比較詳細,但是代碼寫的水)
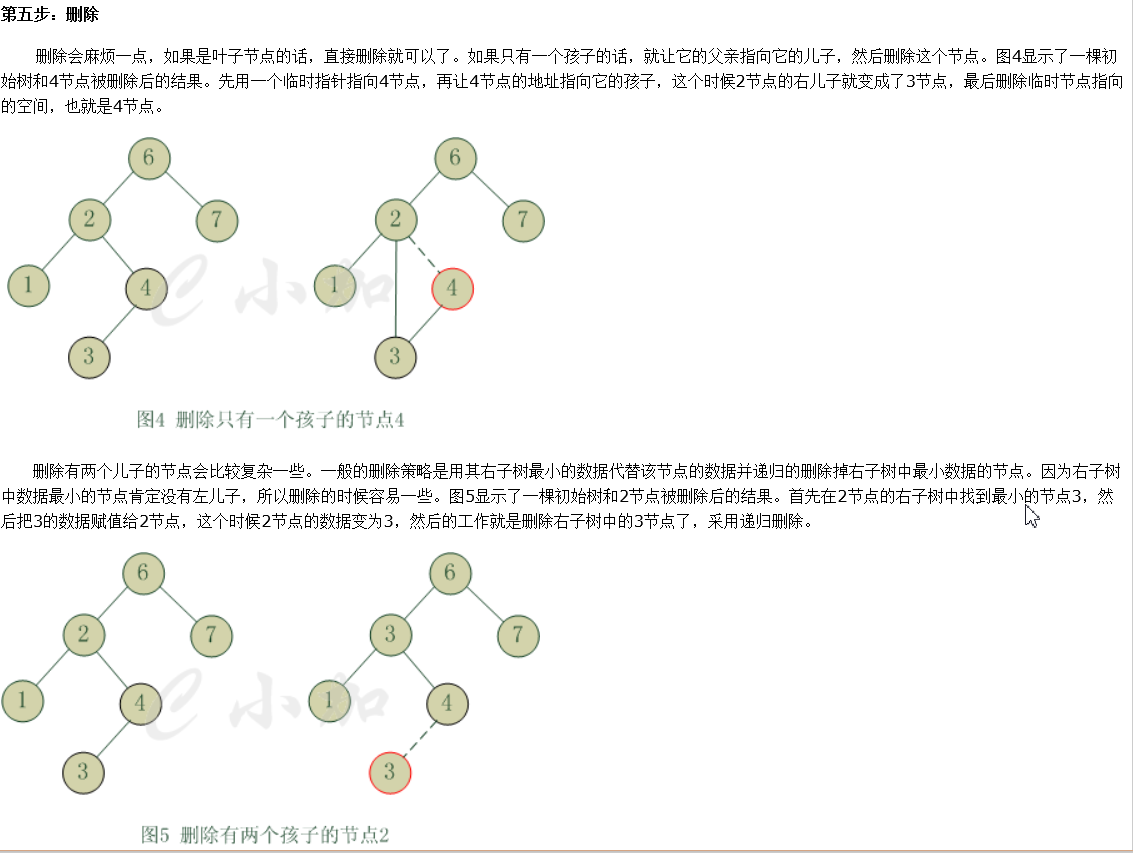
代碼實現如下,有點精簡,多看幾遍,或者調試幾遍理解更容易寫.
/* * 刪除結點 * proot : 指向頭結點的結點 * v : 待刪除的值 */ void tree_delete(tree_t* proot, node_t v) { tree_t root, n, p, t;//n表示v結點,p表示父親結點 if ((!proot) || !(root = *proot)) return; //這裡就找見 v結點 n和它的父親結點p p = tree_parent(root, v, &n); if (!n) //第零情況 沒有找見這個結點直接返回 return; //第一種情況,刪除葉子結點,直接刪除就可以此時t=NULL; 第二情況 只有一個葉子結點 if (!n->lc || !n->rc) { if (!(t = n->lc)) //找見當前結點n的唯一孩子結點 t = n->rc; if (!p) *proot = NULL; else { if (p->lc == n) //讓當前結點的父親收養這個它唯一的孩子 p->lc = t; else p->rc = t; } //刪除當前結點並返回,C要是支持 return void; 語法就好了 free(n); return; } //第三種情況, 刪除的結點有兩個孩子 //將當前結點 右子樹中最小值替代為它,繼承王位,它沒有左兒子 for (t = n->rc; t->lc; t = t->lc) ; n->v = t->v;//用nr替代n了,高效,並讓n指向找到t的唯一右子樹, tree_delete(&n->rc, t->v);//遞歸刪除n右子樹中最小值, 從t開始,很高效 }
第一步找見這個結點和它父親結點,沒找見它直接返回,父親結點為了重新配置繼承關係.
對於 要刪除 葉子結點或只有孩子的結點, 刪除 走 if(!n->lc || !n->rc) 分支不同是t
當只為葉子結點 t = NULL, 當有一個孩子結點, t = 後繼結點,將其二和一了,是一個突破.
最後 刪除 有兩個孩子的結點, 我們的做法,將 它 右子樹中最小值找到,讓其替代自己, 後面在右子樹中刪除 那個結點.
1.2 簡單擴展一下 遞歸的潛規則
遞歸大多數流程如下
//數據列印函數,全部輸出,不會列印回車,中序遞歸 void tree_print(tree_t root) { if (root) { //簡單中序找到最左結點,列印 tree_print(root->lc); printf("%d ", root->v); tree_print(root->rc); } }
這樣的遞歸的方式 是
tree_print_0 => tree_print_1 => tree_print_2 => tree_print_3 => tree_print_2 => tree_print_1 => tree_print_0
先入函數棧後出函數棧,遞歸深度太長會爆棧.上面就是大多數遞歸的方式.
遞歸中有一種特殊的尾遞歸.不需要依賴遞歸返回結果.一般遞歸代碼在函數最尾端.例如上 刪除代碼,結構如下
tree_delete_0 => tree_delete_0 => tree_delete_1 => tree_delete_1 => tree_delete_2 => tree_delete_2 => tree_delete_3 =>
這裡代碼就是入棧出棧,跳轉到新的遞歸中.屬於編譯器關於遞歸的優化,不依賴遞歸返回的結果,最後一行,一般都優化為尾遞歸很安全.
入不同行開發,潛規則還是比較多的.扯一點, 一天晚上計程車回來和司機瞎扯淡, 他說有一天帶一個導演,那個導演打電話給一個女孩父親,
告訴他,他女兒今天晚上來他房間,痛斥一頓讓她走了,後面就聯繫女孩父親,女孩父親神回覆,導演你該潛你就潛. 估計當時那個導演心裡就有
一萬個草泥馬奔過,怎麼就有這麼一對活寶父女.
人生活寶多才歡樂,快樂才會笑著帶著'class'.
1.3 說一下介面和測試代碼
一般良好安全的編程喜歡是,先寫介面,再寫總的測試代碼,後面代碼介面打樁挨個測試. 這裡總的介面和測試代碼如下
/* * 在二叉查找樹中插入結點 * proot : 頭結點的指針 * v : 待插入變數值,會自動分配記憶體 */ void tree_insert(tree_t* proot, node_t v); //數據列印函數,全部輸出,不會列印回車,中序遞歸 void tree_print(tree_t root); /* * 在這個二叉查找樹中查找 值為v的結點,找不見返回NULL * root : 頭結點 * v : 查找結點值 * : 返回值為查找到的結點,找不見返回NULL */ tree_t tree_search(tree_t root, node_t v); /* * 查找這個結點的父結點 * root : 頭結點 * v : 查找的結點 * : 返回這個v值的父親結點,找不見返回NULL,可以返回孩子結點 */ tree_t tree_parent(tree_t root, node_t v, tree_t* pn); /* * 刪除結點 * proot : 指向頭結點的結點 * v : 待刪除的值 */ void tree_delete(tree_t* proot, node_t v); /* * 刪除這個二叉查找樹,並把根結點置空 * proot : 指向根結點的指針 */ void tree_destroy(tree_t* proot); //簡單輸出幫助巨集 #define TREE_PRINT(root) \ puts("當前二叉查找樹的中序數據如下:"), tree_print(root), putchar('\n') //簡單的主函數邏輯 int main(int argc, char* argv[]) { tree_t root = NULL; //先創建一個二叉樹 試試 node_t a[] = { 8,4,5,11,2,3,7,-1,9,0,1,13,12,10 }; //中間臨時變數 tree_t tmp; node_t n; int i = -1; //插入數據 while (++i<sizeof(a) / sizeof(*a)) tree_insert(&root, a[i]); //簡單輸出數據 TREE_PRINT(root); //這裡查找數據,刪除數據列印數據 n = 5; tmp = tree_search(root, n); if (tmp == NULL) printf("root is no find %d!\n", n); else printf("root is find %d, is %p,%d!\n", n, tmp, tmp->v); //查找父親結點 n = 12; tmp = tree_parent(root, n, NULL); if (tmp == NULL) printf("root is no find %d!\n", n); else printf("root is find parent %d, is %p,%d!\n", n, tmp, tmp->v); //刪除測試 n = 8; tree_delete(&root, n); TREE_PRINT(root); n = 9; tree_delete(&root, n); TREE_PRINT(root); //釋放資源 tree_destroy(&root); system("pause"); return 0; }
測試代碼就是把聲明的介面挨個測試一遍.對於代碼打樁意思就是簡單的實現介面,讓其能編譯通過.如下
/* * 在這個二叉查找樹中查找 值為v的結點,找不見返回NULL * root : 頭結點 * v : 查找結點值 * : 返回值為查找到的結點,找不見返回NULL */ tree_t tree_search(tree_t root, node_t v) { return NULL; }
就是打樁. 到這裡基本都萬事具備了.設計思路有了,原理也明白了,下麵上一個完整案例看結果.
2.彙總代碼, 看運行結果
首先看運行結果截圖

查找,刪除,列印都來了一遍, 具體的實現代碼如下
#include <stdio.h> #include <stdlib.h> #include <errno.h> #include <string.h> //控制台列印錯誤信息, fmt必須是雙引號括起來的巨集 #ifndef CERR #define CERR(fmt, ...) \ fprintf(stderr,"[%s:%s:%d][error %d:%s]" fmt "\r\n",\ __FILE__, __func__, __LINE__, errno, strerror(errno), ##__VA_ARGS__) //檢測並退出的巨集 #define CERR_EXIT(fmt, ...) \ CERR(fmt, ##__VA_ARGS__), exit(EXIT_FAILURE) #endif/* !CERR */ /* * 這裡簡單的溫故一下 , 二叉查找樹 *一切從簡單的來吧 */ typedef int node_t; typedef struct tree { node_t v; //這裡簡單測試一下吧,從簡單做起 struct tree* lc; struct tree* rc; } *tree_t; /* * 在二叉查找樹中插入結點 * proot : 頭結點的指針 * v : 待插入變數值,會自動分配記憶體 */ void tree_insert(tree_t* proot, node_t v); //數據列印函數,全部輸出,不會列印回車,中序遞歸 void tree_print(tree_t root); /* * 在這個二叉查找樹中查找 值為v的結點,找不見返回NULL * root : 頭結點 * v : 查找結點值 * : 返回值為查找到的結點,找不見返回NULL */ tree_t tree_search(tree_t root, node_t v); /* * 查找這個結點的父結點 * root : 頭結點 * v : 查找的結點 * : 返回這個v值的父親結點,找不見返回NULL,可以返回孩子結點 */ tree_t tree_parent(tree_t root, node_t v, tree_t* pn); /* * 刪除結點 * proot : 指向頭結點的結點 * v : 待刪除的值 */ void tree_delete(tree_t* proot, node_t v); /* * 刪除這個二叉查找樹,並把根結點置空 * proot : 指向根結點的指針 */ void tree_destroy(tree_t* proot); //簡單輸出幫助巨集 #define TREE_PRINT(root) \ puts("當前二叉查找樹的中序數據如下:"), tree_print(root), putchar('\n') //簡單的主函數邏輯 int main(int argc, char* argv[]) { tree_t root = NULL; //先創建一個二叉樹 試試 node_t a[] = { 8,4,5,11,2,3,7,-1,9,0,1,13,12,10 }; //中間臨時變數 tree_t tmp; node_t n; int i = -1; //插入數據 while (++i<sizeof(a) / sizeof(*a)) tree_insert(&root, a[i]); //簡單輸出數據 TREE_PRINT(root); //這裡查找數據,刪除數據列印數據 n = 5; tmp = tree_search(root, n); if (tmp == NULL) printf("root is no find %d!\n", n); else printf("root is find %d, is %p,%d!\n", n, tmp, tmp->v); //查找父親結點 n = 12; tmp = tree_parent(root, n, NULL); if (tmp == NULL) printf("root is no find %d!\n", n); else printf("root is find parent %d, is %p,%d!\n", n, tmp, tmp->v); //刪除測試 n = 8; tree_delete(&root, n); TREE_PRINT(root); n = 9; tree_delete(&root, n); TREE_PRINT(root); //釋放資源 tree_destroy(&root); system("pause"); return 0; } /* * 在二叉查找樹中插入結點 * proot : 頭結點的指針 * v : 待插入變數值,會自動分配記憶體 */ void tree_insert(tree_t* proot, node_t v) { tree_t n, p = NULL, t = *proot; while (t) { if (t->v == v) //不讓它插入重覆數據 return; p = t; //記錄上一個結點 t = t->v > v ? t->lc : t->rc; } //這裡創建結點,創建失敗直接退出C++都是這種做法 n = calloc(sizeof(struct tree), 1); if (NULL == n) CERR_EXIT("calloc struct tree error!"); n->v = v; //這裡插入了,開始第一個是頭結點 if (NULL == p) { *proot = n; return; } if (p->v > v) p->lc = n; else p->rc = n; } //數據列印函數,全部輸出,不會列印回車,中序遞歸 void tree_print(tree_t root) { if (root) { //簡單中序找到最左結點,列印 tree_print(root->lc); printf("%d ", root->v); tree_print(root->rc); } } /* * 在這個二叉查找樹中查找 值為v的結點,找不見返回NULL * root : 頭結點 * v : 查找結點值 * : 返回值為查找到的結點,找不見返回NULL */ tree_t tree_search(tree_t root, node_t v) { while (root) { if (root->v == v) return root; if (root->v > v) root = root->lc; else root = root->rc; } return NULL; } /* * 查找這個結點的父結點 * root : 頭結點 * v : 查找的結點 * : 返回這個v值的父親結點,找不見返回NULL,可以返回孩子結點 */ tree_t tree_parent(tree_t root, node_t v, tree_t* pn) { tree_t p = NULL; while (root) { if (root->v == v) break; p = root; if (root->v > v) root = root->lc; else root = root->rc; } if (pn) //返回它孩子結點 *pn = root; return p; } /* * 刪除結點 * proot : 指向頭結點的結點 * v : 待刪除的值 */ void tree_delete(tree_t* proot, node_t v) { tree_t root, n, p, t;//n表示v結點,p表示父親結點 if ((!proot) || !(root = *proot)) return; //這裡就找見 v結點 n和它的父親結點p p = tree_parent(root, v, &n); if (!n) //第零情況 沒有找見這個結點直接返回 return; //第一種情況,刪除葉子結點,直接刪除就可以此時t=NULL; 第二情況 只有一個葉子結點 if (!n->lc || !n->rc) { if (!(t = n->lc)) //找見當前結點n的唯一孩子結點 t = n->rc; if (!p) *proot = NULL; else { if (p->lc == n) //讓當前結點的父親收養這個它唯一的孩子 p->lc = t; else p->rc = t; } //刪除當前結點並返回,C要是支持 return void; 語法就好了 free(n); return; } //第三種情況, 刪除的結點有兩個孩子 //將當前結點 右子樹中最小值替代為它,繼承王位,它沒有左兒子 for (t = n->rc; t->lc; t = t->lc) ; n->v = t->v;//用nr替代n了,高效,並讓n指向找到t的唯一右子樹, tree_delete(&n->rc, t->v);//遞歸刪除n右子樹中最小值, 從t開始,很高效 } //採用後序刪除 static void __tree_destroy(tree_t root) { if (root) { __tree_destroy(root->lc); __tree_destroy(root->rc); free(root); } } /* * 刪除這個二叉查找樹,並把根結點置空 * proot : 指向根結點的指針 */ void tree_destroy(tree_t* proot) { if (proot) __tree_destroy(*proot); *proot = NULL; }
大家自己聯繫一下,代碼不多,容易學習順帶回顧一下數據結構中二叉樹結構,關於其中 tree_destroy 編碼方式,是個人的編程習慣.
在C中變數聲明後沒有預設初始化, 所以習慣有這樣的代碼
struct sockaddr_in sddr; memset(&sddr, 0, sizeof sddr);
我覺得這樣麻煩,我習慣的寫法是
struct sockaddr_in saddr = { AF_INET };
利用了一個C聲明初始化潛規則,上面和下麵代碼轉成彙編後也許都相似.後面寫法,預設編譯器幫我們把它後面沒初始化部分置成0.
還有一個習慣,可以允許一個爛的開始,必須要有一個perfect結束,參照老C++版本的智能指針,也叫破壞指針. 做法就是
char* p = malloc(1); free(p); p = NULL;
防止野指針.一種粗暴的做法,所以個人習慣在結束的時候多'浪費'一點時間回顧一下以前,再將其徹底抹除,等同於亞洲飛人直接刪除所有回憶的做法.
編程的實現.最後再吐槽一下,為什麼C++很爛,因為看了無數的書,還是不知道它要鬧哪樣.它就是一本易筋經,左練右練上練下練都可以,終於練成了
恭喜你,這張一張殘廢證收下.
再扯一點, 為什麼C++中叫模板,上層語言中叫泛型? 哈哈,可以參照全特化和偏(範)特化.這裡賣一個關子,但是本文中最後會有案例解決.
3.繼往開來,瞭解一些數據結構設計的模式
上面基本都扯的差不多了,這裡分享C中幾種的數據結構設計模式.
第一種 一切解'對象'
/* * C中如何封裝一個 tree '結構'(結構決定演算法) */ /* * 第一種思路是 一切皆'對象' */ struct otree { void* obj; struct otree* lc; struct otree* rc; }; struct onode { int id; char* name; }; // obj => &struct onde的思路,浪費了4位元組,方便管理
大家看到那個 void*應該就明白了吧等同於上層語言中Object對象.
第二種 萬物皆'泛型'
/* * 第二種思路是 萬物皆'泛型' */ struct tree_node { struct tree_node *lc; struct tree_node *rc; }; #define TREE_NODE \ struct tree_node *__tn struct ttree { TREE_NODE; //必須在第一行,不在第一行需要計算偏移量 offset //後面就是結構了 int id; char* name; };
下麵這種相比上面這種節約4位元組.缺點調試難.還有好多種例如模板流,特定寫死流. 這裡擴展一下另一個技巧
關於C中巨集簡化結構的代碼
/* IPv6 address */ struct in6_addr { union { uint8_t __u6_addr8[16]; #if defined __USE_MISC || defined __USE_GNU uint16_t __u6_addr16[8]; uint32_t __u6_addr32[4]; #endif } __in6_u; #define s6_addr __in6_u.__u6_addr8 #if defined __USE_MISC || defined __USE_GNU # define s6_addr16 __in6_u.__u6_addr16 # define s6_addr32 __in6_u.__u6_addr32 #endif };
是不是很新奇,但是這樣的代碼,上層包塊庫都不推薦用,這些都是內核層的定義.用的越多越容易出錯.
到這裡基本就快結束了,上面介紹的幾種結構設計思路,大家需要自己揣摩. 特別有價值.搞明白.
再扯一點,很久以前對這樣的結構不明白
struct mem_storage{ union { int again; void* str; } mem; ..... };
上面again 是乾什麼的,後來才明白了,主要作用是設定記憶體對齊的位元組數.方便移植.使其結構體記憶體結構是一樣,也方便CPU讀取.
思考了很多但是還不明白, 那就對了,說明你還有追求!
這裡再擴展一下, 有時候
/*
常遇見下麵代碼
*/
void ss_free(void* arg)
{
if(....){
.....
free(arg);
return;
}
....
}
真心 希望 C中提供 return void; 語法,
這樣就可以寫成
return free(arg); //或者 return (void)check(arg);
這樣代碼會更精簡, 更好看. 這裡也可以通過巨集設計處理
#define return_func(f, ...) \ f(##__VA_ARGS__); \ return
屬於偽造吧,希望C委員會提供 return void; 語法!!
後記
錯誤是難免的,有問題提示馬上改. 下次有機會將二叉樹講透,關於設計開發庫中用的二叉樹結構都來一遍,最後分享一下,實際運用的
庫案例.拜~,
有時候在想如果不以經濟建設為中心,是不是人會更有意思一點? 有一款小網游叫中國, 挖了無數坑,就希望大R去充值,diao絲去陪練.哈哈


