
畢業設計做了一個簡單的研究下驗證碼識別的問題,並沒有深入的研究,設計圖形圖像的東西,水很深,神經網路,機器學習,都很難。這次只是在傳統的方式下分析了一次。今年工作之後再也沒有整理過,前幾天一個家伙要這個demo看下,我把一堆東西收集,打包給他了,他閑太亂了,我就整理記錄下。這也是大學最後的一次...
畢業設計做了一個簡單的研究下驗證碼識別的問題,並沒有深入的研究,設計圖形圖像的東西,水很深,神經網路,機器學習,都很難。這次只是在傳統的方式下分析了一次。
今年工作之後再也沒有整理過,前幾天一個家伙要這個demo看下,我把一堆東西收集,打包給他了,他閑太亂了,我就整理記錄下。這也是大學最後的一次作業,裡面有很多記憶和懷念。
這個demo的初衷不是去識別驗證碼,是把驗證的圖像處理方式用到其他方面,車票,票據等。
這裡最後做了一個發票編號識別的的案例:
地址:http://v.youku.com/v_show/id_XMTI1MzUxNDY3Ng==.html
demo中包含一個驗證碼識別處理過程的演示程式,一個自動識別工具類庫,還有一個發票識別的演示程式

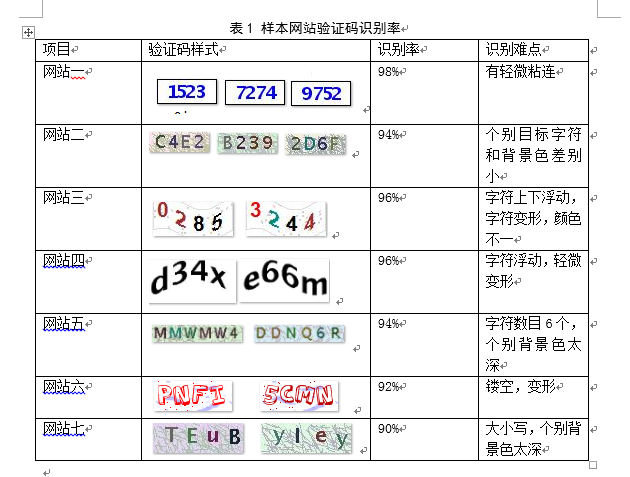
用了7個網站的圖形驗證碼做為案例,當然還是有針對性的,避開了粘連,扭曲太厲害的:







最終的識別率:
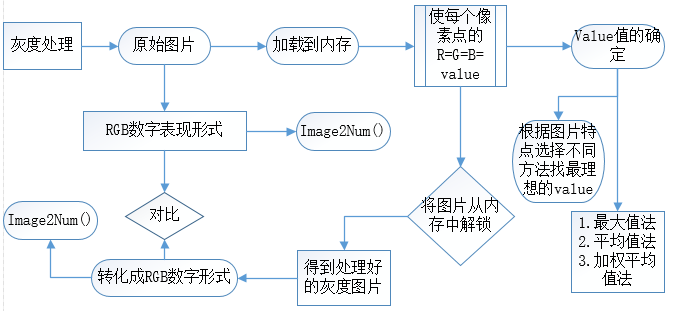
- 在驗證碼圖像的處理過程中,涉及驗證碼生成,灰度處理,背景色去除,噪點處理,二值化過程,圖片字元分割,圖片歸一化,圖片特征碼生成等步驟;
灰度處理方式主要有三種:
- 最大值法: 該過程就是找到每個像素點RGB三個值中最大的值,然後將該值作為該點的
- 平均值法:該方法選灰度值等於每個點RGB值相加去平均
- 加權平均值法:人眼對RGB顏色的感知並不相同,所以轉換的時候需要給予三種顏色不同的權重
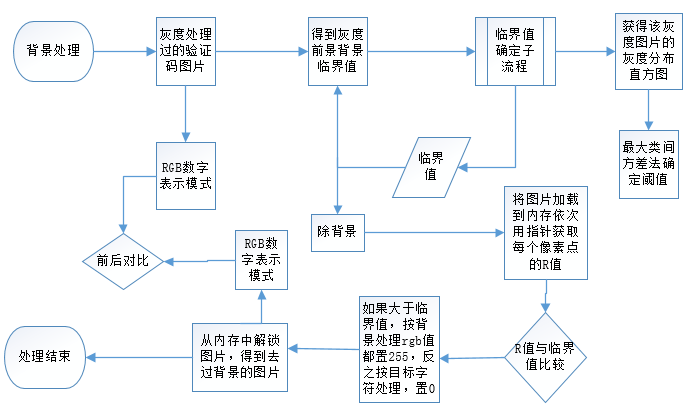
背景去除
該過程就是將背景變成純白色,也就是儘可能的將目標字元之外的顏色變成白色。該階段最難的就是確定圖片的背景和前景的分割點,就是那個臨界值。因為要將這張圖片中每個像素點R值(灰度處理後的圖片RGB的值是相同的)大於臨界值的點RGB值都改成255(白色)。而這個臨界點在整個處理過程中是不變的。
能區分前景和背景,說明在該分割點下,前景和背景的分別最明顯,就像一層玻璃,將河水分成上下兩部分,下麵沉澱,相對渾濁,上面清澈,這樣,兩部分區別相當明顯。這個片玻璃的所在位置就是關鍵。
常用臨界點閾值確定演算法
- 雙峰法,這種演算法很簡單,假設該圖片只分為前景和背景兩部分,所以在灰度分佈直方圖上,這兩部分會都會形成高峰,而兩個高峰間的低谷就是圖片的前景背景閾值所在。這個演算法有局限性,如果該圖片的有三種或多種主要顏色,就會形成多個山峰,不好確定目標山谷的所在,尤其是驗證碼,多種顏色,灰度後也會呈現不同層次的灰度圖像。故本程式沒有採用這種演算法。
- 迭代法,該演算法是先算出圖片的最大灰度和最小灰度,取其平均值作為開始的閾值,然後用該閾值將圖片分為前景和背景兩部分,在計算這兩部分的平均灰度,取平均值作為第二次的閾值,迭代進行,直到本次求出的閾值和上一次的閾值相等,即得到了目標閾值。
- 最大類間方差法,簡稱OTSU,是一種自適應的閾值確定的方法,它是按圖像的灰度特性,將圖像分成背景和目標2部分。背景和目標之間的類間方差越大,說明構成圖像的2部分的差別越大,當部分目標錯分為背景或部分背景錯分為目標都會導致2部分差別變小。因此,使類間方差最大的分割意味著錯分概率最小。而該方法的目標就是找到最符合條件的分割背景和目標的閾值。本程式也是採用的該演算法進行背景分離的。
- 灰度拉伸演算法,這是OTSU的一種改進,因為在前景背景差別不大的時候,OTSU的分離效果就會下降,此時需要增加前景背景的差別,這是只要在原來的灰度級上同時乘以一個繫數,從而擴大灰度的級數。
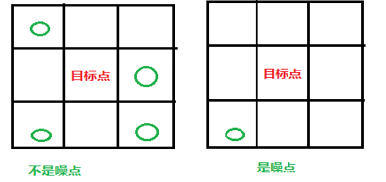
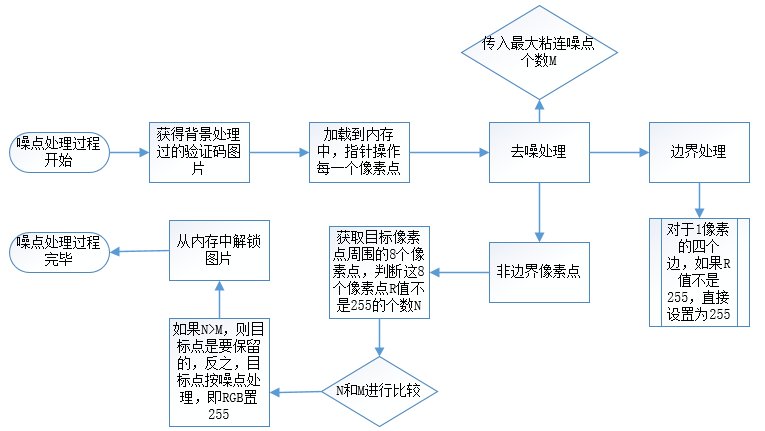
噪點判斷及去除
首先是去除邊框,有的驗證碼在圖片邊界畫了一個黑色邊框,根據去背景的原理這個邊框是沒有被去掉的。去除這個邊框很簡單,對載入到二維數組中每個像素點進行判斷,如果該點的橫坐標等於0或者圖片寬度減一,或者總坐標等於0或者縱坐標等於圖片高度減一,它的位置就是邊框位置。直接RGB置0去除邊框。
對於非邊框點,判斷該目標像素點是不是噪點不是直接最目標點進行判斷的,是觀察它周圍的點。以這個點為中心的九宮格,即目標點周圍有8個像素點,計算這8個點中不是背景點(即白色)點的個數,如果大於給定的界定值(該值和沒中驗證碼圖片噪點數目,噪點粘連都有關,不能動態獲取,只能根據處理結果對比找到效果好的值),則說明目標點是字元內某個像素點的幾率大些,古改點不能作為噪點,否則作為噪點處理掉。假設此次的界定值是2,則:
二值化
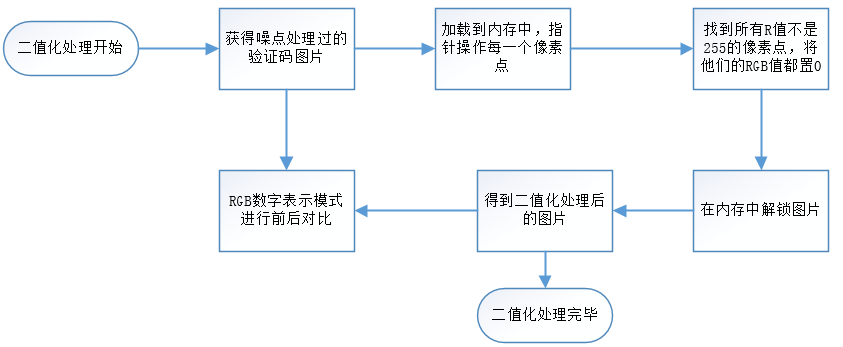
二值化區別於灰度化,灰度化處理過的圖片,每個像素點的RGB值是一樣的,在0-255之間,但是二值化要求每個像素點的RGB值不是0就是255.將圖片徹底的黑白化。
二值化過程就是對去噪後的驗證碼圖片的每個像素點進行處理,如果該點的R值不是255,那麼就將該點的RGB值都改成0(純黑色),這樣整個過程下來,這正圖片就變成真正意義上的黑白圖片了。
圖片分割
圖片分割的主要演算法
圖片分割技術在圖形圖像的處理中占有非常重要的地位,圖片是一個複雜的信息傳遞媒介,相應的,不是每個圖片上的所有信息都是預期想要的,因次,在圖片上”篩選“出目標區域圖像就顯得很重要,這就用到了圖片分割技術。
圖片字元的分割是驗證碼識別過程中最難的一步,也是決定識別結果的一步。不管多麼複雜的驗證碼只要能準確的切割出來,就都能被識別出來。分割的方式有多種多樣,對分割後的精細處理也複雜多樣。
下麵介紹幾種成熟的分割演算法:
- 基於閾值的分割,這種分割方式在背景處理中已經用到,通過某種方式找到目標圖片區域和非目標圖片區域間的分界值,進而達到將兩個區域分離的目的,這種方式達不到區分每個字元的效果,所以在分割階段沒有採用。
- 投影分割,也叫做基於區域的分割,這種分割演算法也很簡單,就是將二值化後的圖片在X軸方向做一次像素點分佈的投影,在峰谷的變化中就能定位到每個目標區域了,然後對單個區域進行Y軸投影,進而確定區域位置。該方式對輕微粘連有一定的處理效果,但是,對與噪點會也會產生過分的分割,還有對‘7’,‘T’,‘L’等會產生分割誤差,所以,程式中沒有採用這種演算法。
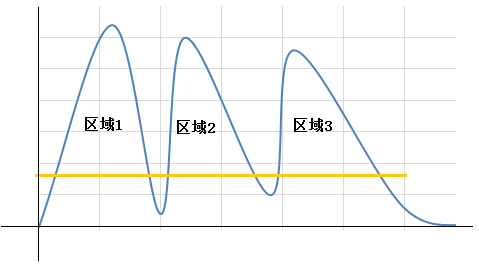
圖3-7投影法
- 邊緣檢測分割,也叫做點掃描法,這種分割方式能一定程度滿足程式的要求,因此,本程式也是採用了這種分割演算法,後面會詳細介紹。
- 聚類,聚類法進行圖像分割是將圖像空間中的像素用對應的特征空間點表示,根據它們在特征空間的聚集對特征空間進行分割,然後將它們映射回原圖像空間,得到分割結果。這種方式處理複雜,但是對粘連,變形等複雜圖像處理有良好的效果。由於時間有限,本次課題並沒有對該方式進行深入分析實現。
3.6.2邊緣檢測分割演算法
程式採用的是邊緣檢測的方式確定每個字元邊界的。該演算法的步驟如下:
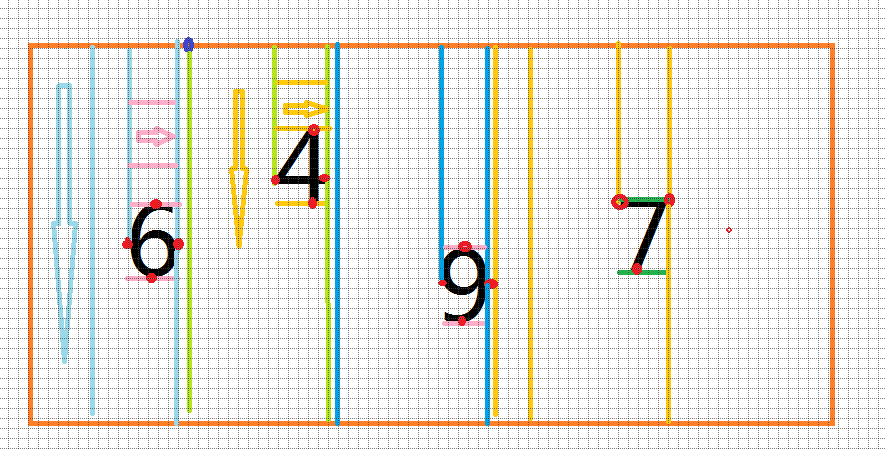
圖3-8圖片分割示意圖
從圖中可以看到,當程式判斷”6“這個字元的邊界時:
- 從掃描指針從圖片最左邊像素點X軸坐標為0開始,向下掃描,掃描寬度為1px,如果碰到了像素點R值是0的,記下此時X坐標A ,如果掃描到底部都沒有遇到,則從指針向右移動一位,繼續縱向掃描直到得到A。
- 掃描指針從A+1開始,縱向掃描每個像素點,遇到R值是255的,變數K(初始值0)自增一,掃描到底部判斷K的值,如果K值等於圖片高度,則停止後續掃描,記下此時X軸坐標B,否則指針向右移動一位,繼續掃描直到得到B。
- 在X區間(A,B-1)中,指針從Y坐標是0點橫向掃描,判斷每個點的R值,如果R值等於0,則停止掃描,記下此時Y軸坐標C。否則,指著下移一個單位,繼續橫向掃描
- 在X區間(A,B-1),指針從C+1處開始橫向掃描,判斷每個像素點的R值,如果R值等於255,使N(初始值0)自增一,這行掃描結束後判斷N的值,如果該值等於B-A,則停止掃描記下此時的Y軸坐標D,否則指針向下移動以為,繼續橫向掃描,知道得到D。
“4“這個字元邊界的獲取也是一樣的,只是步驟一中掃描開始的位置X坐標0變成了B+1.
每次判斷一下B-A,如果他的值小於你驗證碼字元中寬度最小的那個,(假設這裡定的是4),則停止找邊界把坐標加到集合中就可以了。
如學校的驗證碼字元中,寬度最窄的是1,但它的寬度是大於4的所以該設定沒有問題,根據情況來定,一般寬度小於4的,驗證碼就很小了,不利於人看。
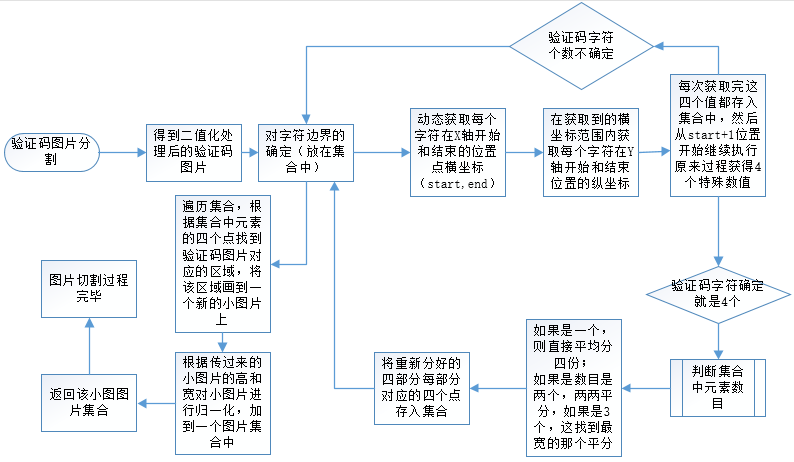
上述過程走完之後,就得到了左右,上下四個邊界點的橫坐標,縱坐標,即(A,B-1,C ,D-1);把這四個點確定的區域對應的原驗證碼所在的區域畫到一張小圖片上。然後把這張小圖片按照設定的高寬進行歸一化處理,把處理好的圖片放入集合中返回。等待下一步處理。
分割前: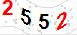 分割後的四張效果:
分割後的四張效果:
分割後的特殊處理
在這一過程中,由於圖像的部分粘連,往往分割的結果都不會達到預期的效果,分割出的小圖片也是千奇百怪。但是,考慮到現在大多數網站的驗證碼字元都是4個,意味著切割出來的小圖片也得是四個,針對這種情況,我就做了進一步處理,首先看下切割後可能出現的情況:
這張驗證碼是二值化處理過的驗證碼,很明顯,第一個和第二個字元是相互粘連的,利用程式的切割方式切出來的圖片應該是3個小圖片,類似這樣:
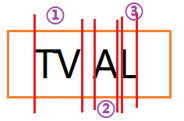
顯然,①不是程式想要的情況,對於這種情況,即第一次切完是3部分的,就找到最寬的一個,然後從中間剁開。得到4部分圖片。
相應的,還有2部分的時候:

這也不是我們理想的情況,也是同樣的道理,把兩部分中中間剁開,得到4個小圖片。
還有這種情況,第一次切割完全是一張的:

我們只需把它均分4分就可以了。
當然上述處理會造成相應的誤差,但是只要後面字模數量足夠大,這樣切割處理效果還是可以的。
此次只對4個字元的情況做了特殊的處理,其他個數的沒有做,具體做法會在總結中介紹。
字模製作
這個過程是將切割好的圖片轉化成特征矩陣,把圖片切割過程中返回的小圖片集合進行特征值獲取。在圖片切割過程,程式已經將切割好的小圖片進行了歸一化處理,即長寬都相同,遍歷每一個像素,如果該點R值是255,則就記錄一個0,如果該點的R值是255,則記錄一個1,這樣按著順序,記錄好的0,1拼成字元串,這個字元串就是該圖片的特征碼。然後前面拼上該圖片對應的字元,用‘--’連接。這樣,一個圖片就有一個特征值字元串對應了,把這個特征值字元串寫入文本或資料庫中,基本的字模庫就建立好了。由於圖片歸一化的時候小圖規格是20*30,所以,每個字模數據就是20*30+3+2(回車換行)=605個字元。
字模庫的量越大,後面的識別正確率也就越高,但是,並不是越大越好,字模數據越多,比對消耗的時間就越多,相比來說效率就會下降。下麵是一張字模庫的部分圖樣:


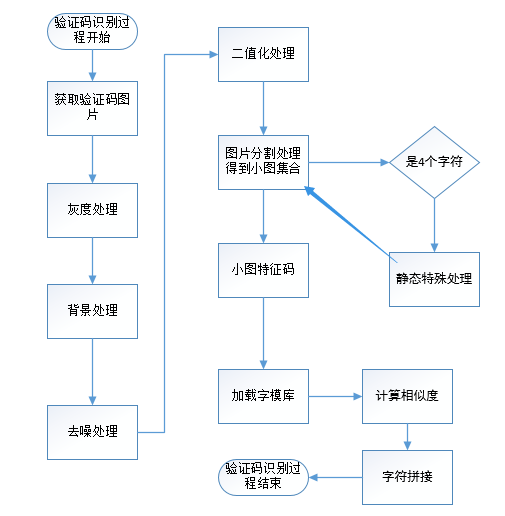
驗證碼識別
要想識別驗證碼,必須要有製作好的字模資料庫,然後一次進行下麵過程:
- 驗證碼圖片的獲取,該步驟驗證碼的來源可以是從網路流中獲取驗證碼, 也可以從磁碟中載入圖片。
- 圖片處理,包括灰度,去噪,去背景,二值化,字元分割,圖片歸一化,圖片特征碼獲取。
3.計算相似度,讀取字模資料庫中的字模數據,用歸一化後的小圖的特征碼和字模數據進行對比,並計算相似度,記錄相似度最高的字模數據項所對應的字元C。
4.識別結果,依次將所得到的字元C拼接起來,得到的字元串就是該驗證碼的識別結果。
下麵是驗證碼識別的具體流程:
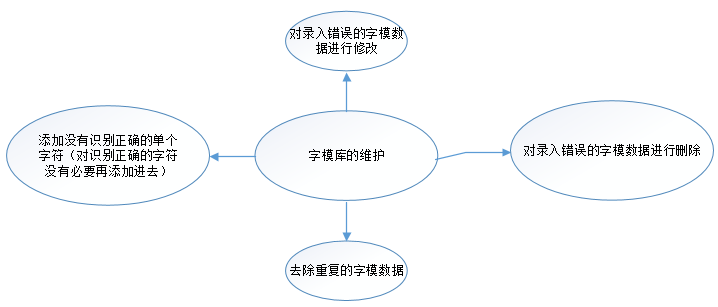
字模庫維護
驗證碼的識別過程已經詳細的分析,識別關鍵點一個在切割,一個在字模庫的質量。字模庫涉及兩個問題,一個就是重覆的問題,一個就是字模數據。這個階段主要實現:
- 重覆字模數據的過濾剔除。
- 對於插入錯誤的字模可以進行修改。
- 可以刪除不需要的字模數據
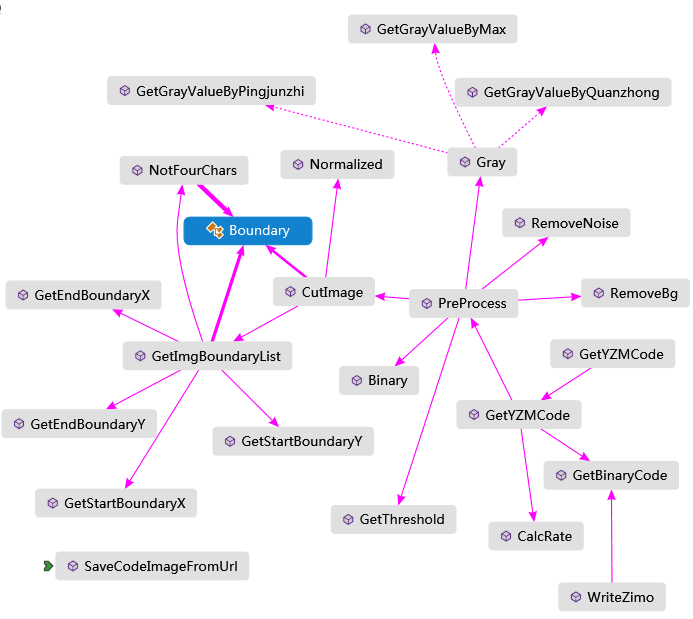
圖片處理類的設計
圖像處理類是遵循面向對象的思想設計的,將圖像處理過程中用到的方法進行封裝,對常用參數值進行參數預設值和可變參數設置,方法重載。該類是靜態類,方便開發人員調用,其中Boundry是存儲小圖片邊界信息的類,裡面有四個邊界值屬性。
開發人員可以直接調用GetYZMCode()方法進行驗證碼的識別處理,這是一個重載方法,其餘的方法會在下麵具體實現中介紹具體方法的設計,下麵是這個類圖表示了ImageProcess類中主要的處理方法和之間的關係:
發票編號識別
這個是基於aforge.net實現的,參考國外一位撲克牌識別的代碼。
過程是先確定發票的位置,然後定位到發票編號,切出發票編號,調用自動識別類庫識別數字,然後再將識別數據寫到屏幕上。當然也要實現訓練字模;
完成這個demo過程還是比較有趣,感謝活躍在博客園,csdn,github,開源中國strackoverflow等社區的前輩,他們對開源社區分享,奉獻讓更多的開發者收益,在他們的肩膀上,我們這些菜鳥才能走的更遠。
最後附上源碼:
https://github.com/ccccccmd/ReCapcha
具體案例都在源代碼中。


