
在使用系統時,我們或多或少的有一些搜索、查找的需求,必須要在文本中搜索某個關鍵字,或者過濾出文本中某些特定的行。grep 命令就為我們提供了這樣一個功能,同時,grep 還可以使用正則表達式進行匹配,這是一個強大的功能,有必要好好掌握。 1.grep 初體驗 grep PATTERN [OPTION ...
在使用系統時,我們或多或少的有一些搜索、查找的需求,必須要在文本中搜索某個關鍵字,或者過濾出文本中某些特定的行。grep 命令就為我們提供了這樣一個功能,同時,grep 還可以使用正則表達式進行匹配,這是一個強大的功能,有必要好好掌握。
1.grep 初體驗
grep PATTERN [OPTIONS] FILE:在文件中按照模式進行查找。FILE 是我們要查找的目標文件,如果不指定目標文件,grep 將會從標準輸入中讀取輸入的內容,然後進行匹配。為了方便起見,本文的所有演示都在命令行中通過標準輸入進行。
- grep PATTERN:最基本的用法,根據 PATTERN 進行查找
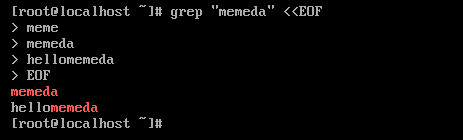
如果沒有高亮顯示匹配到的內容,可以手動指定:grep --color PATTER 進行匹配,更可以使用命令別名,減少我們的輸入時間:alias grep="grep --color"。
- grep PATTERN -i:忽略大小寫匹配
- grep PATTERN -v:反轉輸出。匹配到的內容不輸出,只輸出沒被匹配到的內容。

- grep PATTERN -o:只顯示匹配到的字串(PATTERN)。預設顯示匹配到的字串所在的整行文本。
2.grep 和正則表達式
正則表達式(Regular Expression 或 REGEXP)分為基礎正則表達式(Basic REGEXP)和擴展正則表達式(Extended REGEXP)。grep 預設採用基礎正則表達式,如需使用擴展正則表達式需要附加選項。
由於介紹正則表達式實在太過複雜,我想了很久也無法很好的組織語言,因此這裡就不再對正則中的元字元進行一一的介紹了。需要瞭解這方面的同學,可以去看一下三十分鐘入門正則表達式系列的教程,應該很快就能學會。
- 使用 grep 進行簡單的正則匹配
"[]" 表示匹配 [] 中出現的任意一個字元,[a-zA-Z] 表示匹配所有的英文字母。

"[^]" 表示匹配出去 [] 中出現的字元之外的任意字元。

在正則表達式中,'*' 號不再表示任意字元,而表示其前的字元可以出現任意次。有時候我們在命令中使用 '*' 進行通配符匹配文件,要註意它在正則表達式中的不同用法。在正則表示中使用 '.' 點號來匹配任意字元。
在正則中,'.' 點號表示不為空的任意字元。

".*" 表示匹配出現任意次數的任意字元。正則表達式預設處於貪婪模式,因此在第一次匹配到結果後,還會進行多次匹配,知道沒有匹配為止。

"\?" 表示匹配前面的字元出現 0 次 或者 1 次,註意這個問號需要被轉義。

"\{m,n\}" 表示前面的字元出現最少 m 次,最大 n 次。"\{m,\}" 表示前面的字元至少出現 m 次,"\{,n\}" 表示前面的字元至多出現 n 次。

'^' 和 '$' 是正則表達式中的兩個位置錨定。'^' 表示其後的字元必須出現在行首,而 '$' 表示其前的字元必須出現在行尾,"^$" 表示匹配空白字元。

"\<" 和 "\>" 用來錨定單詞,二者不一定要成對出現,也可以使用 "\b" 進行錨定。"\bWORD" (或者 "\<WORD\>") 表示匹配以 WORD 開頭的單詞,"WORD\b" 表示匹配以 WORD 結尾的單詞,"\bWORD\b" 表示完完全全匹配 WORD 單詞。

"\(\)" 表示對 PATTERN 進行分組,分組還支持後向引用,使用 "\1","\2" 等引用前面的分組。後向引用只匹配和前面相同的內容。

'|' 表示或,匹配其前或者其後的單詞,註意並不是匹配字元,如需匹配字元,需要使用分組進行限定。我這裡使用的是擴展正則,如需使用基本正則,需要將 '|' 換為 "\|"。
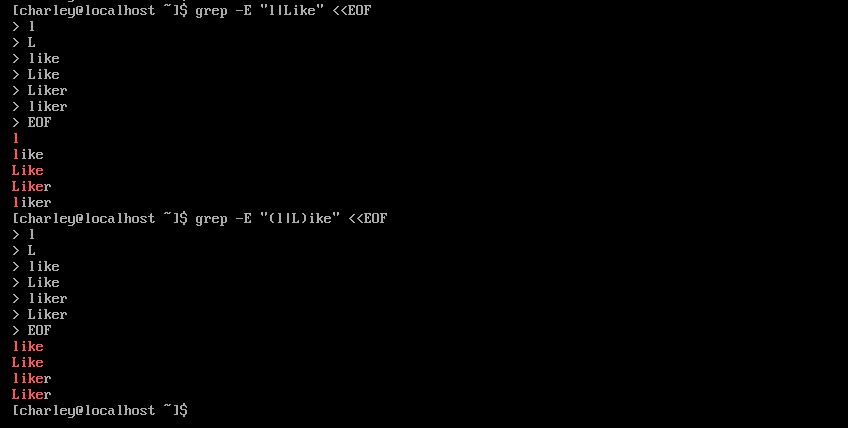
3.擴展正則表達式
grep 同時還支持擴展正則表達式,在使用擴展正則表達式是,需要使用 -E 選項。基礎正則表達式和擴展正則表達式中的一些區別:
- 基礎正則中使用 \?,擴展正則中使用 ?
- 基礎正則中使用 \(\),擴展正則中使用 ()
- 基礎正則中使用 \{\},擴展正則中使用 {}
在基礎正則表達式中匹配 ?,(),{} ,不需要進行轉移,而在擴展正則表達式中則需要加上轉義符號 \。
擴展正則表達式中的其他選項:
- \s:匹配空白字元
- \S:匹配非空白字元
- \w:匹配字母,數字,相當於 [0-9a-zA-Z]
- \W:不匹配字母和數字,相當於 [^0-9a-zA-Z]
4.grep 的其他選項
- grep PATTERN FILE -A NUM:使用 grep 進行匹配之後,顯示匹配的行,同時向後顯示指定的行
- grep PATTERN FILE -B NUM:和上面相反,向後顯示指定行
- grep PATTERN FILE -C NUM:進行匹配之後,分別向前和向後顯示指定的行,相當於 -AB NUM
- grep PATTERN FILE -c:顯示被匹配到的行數
- grep PATTERN FILE -F:相當於 fgrep
- grep PATTERN FILE -P:使用 Perl 風格的正則表達式
- \d:匹配任意十進位數字,相當於 [0-9]
- \D:匹配任意非數字字元,相當於 [^0-9]
5.egrep 和 fgrep
在使用 grep 時,如果想要開啟擴展正則表達式,需要指定 -E 選項,而 egrep 命令則是預設支持擴展正則表達式。因此在需要使用擴展正則表達式時推薦使用 egrep 代替 grep -E。
fgrep 表示快速匹配,不支持正則表達式,沒有轉義的概念,會對 PATTERN 中的所有字元進行匹配。
6.總結
本篇我們介紹了 grep 命令和正則表達式的基本使用,grep 是 Linux 下的一個文本處理命令,配合正則表達式使用,其功能非常強大。grep 主要用來查找操作,如果想使用替換等更加強大的功能,就需要使用 sed 或者 awk 命令。grep,sed,awk 被稱為 Linux 下的三個文本處理殺器,等學到相應的章節再繼續介紹 :)
作者:Charleylla 轉載請註明出處:http://www.cnblogs.com/charleylla/p/5988885.html


