
最近寫代碼,遇到一個問題,微軟基於List<T>自帶的方法是public bool Remove(T item);,可是有時候我們可能會用到諸如RemoveAll<IEnumerable<T>>的方法,坦白的說,就是傳入的參數是一個IEnumerable<T>,而不是一個T,這種情景是隨時可能用到的 ...
最近寫代碼,遇到一個問題,微軟基於List<T>自帶的方法是public bool Remove(T item);,可是有時候我們可能會用到諸如RemoveAll<IEnumerable<T>>的方法,坦白的說,就是傳入的參數是一個IEnumerable<T>,而不是一個T,這種情景是隨時可能用到的。當然我們會輕易的發現List<T>里本身就封裝了一個方法public int RemoveAll(Predicate<T> match),但是後面我們的測試性能上來說,真不敢恭維。被逼無耐,只能想辦法封裝一個IEnumerable<T>擴展方法。可是此時不要忘了寫這篇文章的宗旨,封裝的目的,就是‘性能’必須要好!
下麵我們一步一步講講我遇到的經歷分享給大家。
假設如下的數據:
1.Source IEnumerable Items:A B C D A E F G H
2.Remove IEnumerable Items:A B C D A E
3.Result IEnumerable Items:F G H
第1行是原有的IEnumerable數據
第2行是要刪除(remove)的數據
第3行是最終刪除結果的數據
從上面數據,我們分析下如何高效的得到第3行數據呢?記得,一定要‘高效’,失去高效的方法,我認為不是本節討論的內容,因為沒有任何意義,當然,高效是相對的,不是說,今天講的方法是最高效的,起碼很高效,恩~ 請不要罵我,確實是費話!
沒錯,很多程式員想必和我一樣,大多數會這樣做


for (int index = 0; index < source.Count; index++) { var item = source.ElementAt(i); if (remove.Contains(item)) { source.Remove(item); } }View Code
好吧,這樣做,目的是達到了,但是,接下來的測試,讓人糾心。
我們來摸擬下數據
新建一個Source IEnumerable 隨機產生10萬條數據 和Remove IEnumerable 隨機產生1萬條數據
List<string> source = new List<string>(); List<string> remove = new List<string>(); int i = 0; Random rad = new Random(); while (i < 100000) { source.Add(rad.Next(Int32.MaxValue).ToString()); i++; } i = 0; while (i < 10000) { remove.Add(rad.Next(Int32.MaxValue).ToString()); i++; } DateTime now = DateTime.Now; for (int index = 0; index < source.Count; index++) { var item = source.ElementAt(i); if (remove.Contains(item)) { source.Remove(item); } } Console.WriteLine("Remove Running time:" + (DateTime.Now - now).TotalSeconds); Console.ReadKey();View Code
上述代碼消耗的時間是 Remove Running time:16.6678431s
所以遇到這種情況,測試結果表明,消耗的時候太長,我們根本等不起,何況放在程式里就是一個炸彈。
當然,我們摸擬的數據可能太過於龐大,但不得不承一個從客觀事實,這個方法效率不是太好!
上面我們討論過 IEnumerable<T>.RemoveAll<IEnumerable<T>>(IEnumerable<T> Items)方法
費話不多說,直接上來測試下,看看如何。
代碼如下:很簡單,僅需一行:
List<string> source = new List<string>(); List<string> remove = new List<string>(); int i = 0; Random rad = new Random(); while (i < 100000) { source.Add(rad.Next(Int32.MaxValue).ToString()); i++; } i = 0; while (i < 10000) { remove.Add(rad.Next(Int32.MaxValue).ToString()); i++; } DateTime now = DateTime.Now; source.RemoveAll(m => remove.Contains(m)); Console.WriteLine("RemoveAll Running time:" + (DateTime.Now - now).TotalSeconds);View Code
測試結果所消耗時間是 RemoveAll Running time:16.1175443s
和第一種方法對比,消耗的時間並沒有太大提高,幾乎一致,唉,真是讓人失望。
這個時候,我們來看看linq to object 看看。
DateTime now = DateTime.Now; /**註冊這裡ToList()主要是讓查詢真正的執行,不然,只是生成語句 var r = (from item in source where !remove.Contains(item) select item).ToList(); **/ var r = source.Where(item => !remove.Contains(item)).ToList(); Console.WriteLine("RemoveAll Running time:" + (DateTime.Now - now).TotalSeconds); Console.ReadKey();View Code
測試結果所消耗時間是 RemoveAll Running time:16.1112403s
其實我們仔細的分析下代碼 m => remove.Contains(m) 本來還是一種遍歷,外層又一層遍歷。再回來過看看Linq To Object 實際上也是變相的雙層遍歷
從時間消耗來說,三種方法時間消耗幾乎一致 O(M*N);
到此為至,我們並沒有找到真正的高效的方法。‘辦法’嘛,總是想靠人想的,不能說,就這樣算了吧?
仔仔想想,List<T> 在遍歷上,是很慢的,而採用諸如字典Dictionary<T> 查找某個鍵(Key)值(Value),性能是非常高效的,因為它是基於'索引'(下麵會詳細的說明)的,理論上講在時間消耗是O(1)。即然這樣,我們回過頭來再看看我們的例子
1.Source IEnumerable Items:A B C D A E F G H
2.Remove IEnumerable Items:A B C D A E
3.Result IEnumerable Items:F G H
眾所周知,字典Key 是唯一的,如果我們把Remove IEnumverable Items 放入字典Dictionary<Remove Items>里,用一個Foreach遍歷所用項,在時間上理論上應該是O(N),然後再對Source IEnumberable Items遍歷對比Dictionary<Remove Items>IEnumverable Items ,如果兩者是相同的項那麼continue for遍歷,否則,把遍歷到的Source IEnumberable Items 項存入一個數組裡,那麼這個數組裡,即是我們需要的Result IEnumberable items結果項了。這個方式有點像‘裝腦袋’。哈哈~,不要高興的太早,由於Remove IEnumverable Items 是允許有重覆的項,那麼放在字典里,不是有點扯了嗎?不用怕,看來,我們直接玩字典得換個方式,把字典的Key放入 Remove Item,把Value存入一個計數器值作為標計,以此如果存在多項重覆的重置value=1,不重覆出現的項直接賦值1。仔仔想想,方法可行。

上面是一個示意圖,A B C D E 作為Key 其中Value值勻為1。
我們看到,A重覆了兩次,那麼在字典里value 標計勻重置為1,B出現了一次,標計為1,這樣做不是多此一舉嗎?
要知道字典是通過Key尋找鍵值的,速度遠遠超過foreach 遍歷List強的多。
好了,我們按照上面的思路寫出方法:
public static IEnumerable<T> RemoveAll<T>(this IEnumerable<T> source, IEnumerable<T> items) { var removingItemsDictionary = new Dictionary<T, int>(); var _count = source.Count(); T[] _items = new T[_count]; int j = 0; foreach (var item in items) { if (!removingItemsDictionary.ContainsKey(item)) { removingItemsDictionary[item] = 1; } } for (var i = 0; i < _count; i++) { var current = source.ElementAt(i); if (!removingItemsDictionary.ContainsKey(current)) { _items[j++] = current; } } return _items; }
方法很簡單吧,其實我們主要想利用字典的Key 快速匹配,至於值就沒那麼重要了。
字典的索引時間上是O(1),遍歷source時間是O(M) 總計時間理論上應該上O(M+N)而不是O(M*N)。
上面的代碼,我們為了讓調用方便,故去擴展IEnumerable<T>,下麵我們來測試下看看時間有沒有提高多少?
IEnumerable<string> dd = source.RemoveAll(remove);
這次,哈哈,既然僅僅只用了0.016001...s,上面幾個例子用了16s 相差太大了,足足提高了1000倍之多,果然採用字典方式,性能上來了,這樣的代碼,放在項目才具有實際意義!
其實仔細分析上面代碼還是有問題的
T[] _items = new T[_count]; //這裡只是粗略的一次性定義了一個_count大小的數組,這樣的數據遠遠超出真正使用的數組
通過上面的分析,產生了很多項NULL的多餘項,如果要是能夠自動擴展大小,那就更好不過了。
這個時候,想起了鏈表形式的東西。
為了在進更一步的提高下性能,眾所周知,hashcode為標誌一個數據的'指標',如果我們能夠判斷hashcode是否相等,也許可以提高一點性能,如果看到字典的源碼,很多人會很快想起,是如何構造了一個類似Set<T>的'數據組'。
試想下,如果我們現在有一個‘特殊字典’,特殊在,我們添加相同的key的時候,返回的是false,而只有不重覆的項才可以成功的添加進來,這樣我們所得的‘數組’就是我們想要的。
可能我說的有點抽像,就像下麵這樣
public static IEnumerable<TSource> Iterator<TSource>(this IEnumerable<TSource> first, IEnumerable<TSource> second, IEqualityComparer<TSource> comparer) { Set<TSource> iteratorVariable = new Set<TSource>(comparer); foreach (TSource local in second) { iteratorVariable.Add(local); } foreach (TSource iteratorVariable1 in first) { if (!iteratorVariable.Add(iteratorVariable1))//這兒是過濾性添加,如果添加失敗,說明此項已添加 return false { continue; } yield return iteratorVariable1;//yield語句為我們有機會創造枚舉數組 } }
其中yield iteratorVariable1 產生的即是我們想要的‘數組’,這裡只所以那麼強悍,歸功於Set<TSource>
我先把所有的代碼貼出來,然後一點一點的講解,不至於片面的頭暈
Set<T>構造器:Slots
internal class Set<TElement> { private IEqualityComparer<TElement> comparer; private int count; private int freeList; private Slot<TElement>[] slots; private int[] buckets; public Set() : this(null) { } public Set(IEqualityComparer<TElement> comparer) { if (comparer == null) { comparer = EqualityComparer<TElement>.Default; } this.comparer = comparer; this.slots = new Slot<TElement>[7]; this.buckets = new int[7]; this.freeList = -1; } private bool Find(TElement value, bool add) { int hashCode = this.InternalGetHashCode(value); for (int i = this.buckets[hashCode % this.buckets.Length] - 1; i >= 0; i = this.slots[i].next) { if ((this.slots[i].hashCode == hashCode) && this.comparer.Equals(this.slots[i].value, value)) { return true; } } if (add) { int freeList; if (this.freeList >= 0) { freeList = this.freeList; this.freeList = this.slots[freeList].next; } else { if (this.count == this.slots.Length) { this.Resize(); } freeList = this.count; this.count++; } int index = hashCode % this.buckets.Length; this.slots[freeList].hashCode = hashCode; this.slots[freeList].value = value; this.slots[freeList].next = this.buckets[index] - 1; this.buckets[index] = freeList + 1; } return false; } private void Resize() { int num = (this.count * 2) + 1; int[] numArray = new int[num]; Slot<TElement>[] destinationArray = new Slot<TElement>[num]; Array.Copy(this.slots, 0, destinationArray, 0, this.count); for (int i = 0; i < this.count; i++) { int index = destinationArray[i].hashCode % num; destinationArray[i].next = numArray[index] - 1; numArray[index] = i + 1; } this.buckets = numArray; this.slots = destinationArray; } public bool Add(TElement value) { return !this.Find(value, true); } internal int InternalGetHashCode(TElement value) { if (value != null) { return (this.comparer.GetHashCode(value)); } return 0; } } internal struct Slot<TElement> { internal int hashCode; internal TElement value; internal int next; }
當數組不夠時進行擴容(在當前的基礎上*2的最小質數(+1)),然後進行重新hashcode碰撞形成鏈表關係:
private void Resize() { int num = (this.count * 2) + 1; int[] numArray = new int[num]; Slot<TElement>[] destinationArray = new Slot<TElement>[num]; Array.Copy(this.slots, 0, destinationArray, 0, this.count); for (int i = 0; i < this.count; i++) { int index = destinationArray[i].hashCode % num; destinationArray[i].next = numArray[index] - 1; numArray[index] = i + 1; } this.buckets = numArray; this.slots = destinationArray; }
估計看到上面的代碼,能暈倒一大片,哈哈~暈倒我不負責哦。
下麵我們來分析一些原理,然後再回過頭看上面的代碼,就很清淅了,必竟寫代碼是建立在一種思想基礎上而來的嘛!
public Set(IEqualityComparer<TElement> comparer) { if (comparer == null) { comparer = EqualityComparer<TElement>.Default; } this.comparer = comparer; this.slots = new Slot<TElement>[7]; this.buckets = new int[7]; this.freeList = -1; }
我們看到,Dictionary在構造的時候做了以下幾件事:
- 初始化一個this.buckets = new int[7]
- 初始化一個this.slots= new slots<T>[7]
- count=0和freeList=-1
- comparer = EqualityComparer<TElement>.Default 作為比較兩個T是否相等的比較器
首先,我們構造一個:
Set<TSource> iteratorVariable = new Set<TSource>(NULL);

添加項時候的變化
Add(4,”4″)後:
根據Hash演算法: 4.GetHashCode()%7= 4,因此碰撞到buckets中下標為4的槽上,此時由於Count為0,因此元素放在slots中第0個元素上,添加後Count變為1

Add(11,”11″)
根據Hash演算法 11.GetHashCode()%7=4,因此再次碰撞到Buckets中下標為4的槽上,由於此槽上的值已經不為-1,此時Count=1,因此把這個新加的元素放到slots中下標為1的數組中,並且讓Buckets槽指向下標為1的slots中,下標為1的slots之下下標為0的slots。

Add(18,”18″)
我們添加18,讓HashCode再次碰撞到Buckets中下標為4的槽上,這個時候新元素添加到count+1的位置,並且Bucket槽指向新元素,新元素的Next指向slots中下標為1的元素。此時你會發現所有hashcode相同的元素都形成了一個鏈表,如果元素碰撞次數越多,鏈表越長。所花費的時間也相對較多。

Add(19,”19″)
再次添加元素19,此時Hash碰撞到另外一個槽上,但是元素仍然添加到count+1的位置。
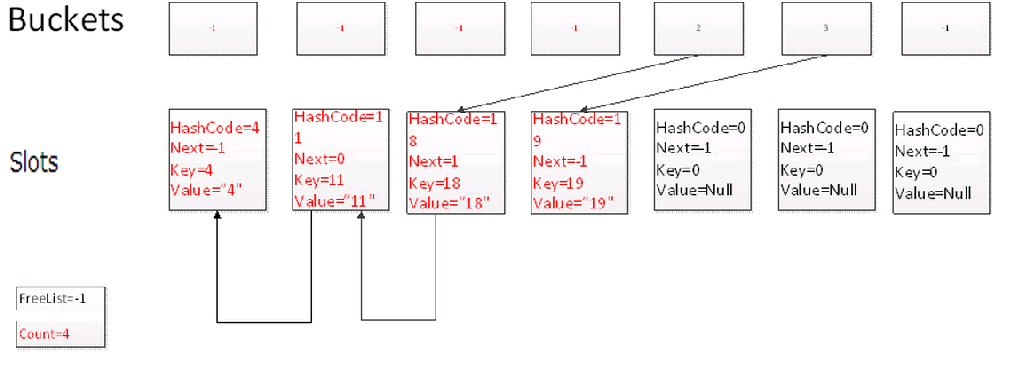
刪除項時的變化:
Remove(4)
我們刪除元素時,通過一次碰撞,並且沿著鏈表尋找3次,找到key為4的元素所在的位置,刪除當前元素。並且把FreeList的位置指向當前刪除元素的位置
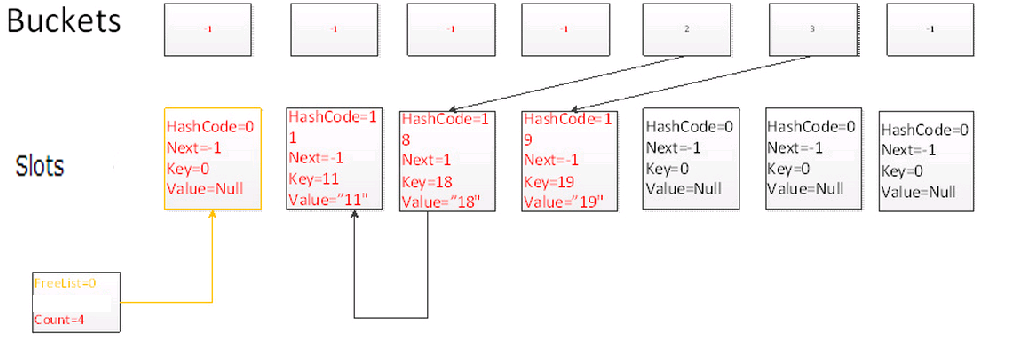
Remove(18)
刪除Key為18的元素,仍然通過一次碰撞,並且沿著鏈表尋找2次,找到當前元素,刪除當前元素,並且讓FreeList指向當前元素,當前元素的Next指向上一個FreeList元素。
此時你會發現FreeList指向了一個鏈表,鏈表裡面不包含任何元素,FreeCount表示不包含元素的鏈表的長度。
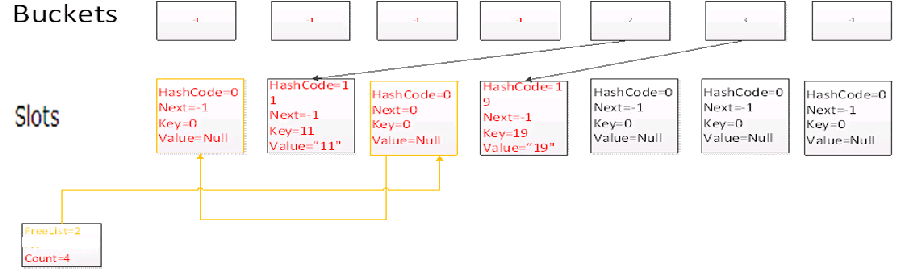
Add(20,”20″)
再添加一個元素,此時由於FreeList鏈表不為空,因此字典會優先添加到FreeList鏈表所指向的位置,添加後,FreeList鏈表長度變為1

部分圖片參考自互聯網,哈哈,然後重畫,寫文章真心不容易,太耗時間,此時四個小時已過去。
通過以上,我們可以發現Set<T>在添加,刪除元素按照如下方法進行:
- 通過Hash演算法來碰撞到指定的Bucket上,碰撞到同一個Bucket槽上所有數據形成一個單鏈表
- 預設情況slots槽中的數據按照添加順序排列
- 刪除的數據會形成一個FreeList的鏈表,添加數據的時候,優先向FreeList鏈表中添加數據,FreeList為空則按照count依次排列
- 字典查詢及其的效率取決於碰撞的次數,這也解釋了為什麼Set<T>的查找會很快。
簡單來說就是其內部有兩個數組:buckets數組和slots數組,slots有一個next用來模擬鏈表,該欄位存儲一個int值,指向下一個存儲地址(實際就是bukets數組的索引),當沒有發生碰撞時,該欄位為-1,發生了碰撞則存儲一個int值,該值指向bukets數組.
一,實例化一個Set<string> iteratorVariable = new Set<string>(null);
a,調用Set預設無參構造函數。
b,初始化Set<T>內部數組容器:buckets int[]和slots<TElement>[],分別分配長度7;
二,向Set<T>添加一個值,Set.add("a","abc");
a,計算"a"的哈希值,
b,然後與bucket數組長度(7)進行取模計算,假如結果為:2
c,因為a是第一次寫入,則自動將a的值賦值到slots[0]的key,同理將"abc"賦值給slots[0].value,將上面b步驟的哈希值賦值給slots[0].hashCode,
slots[0].next 賦值為-1,hashCode賦值b步驟計算出來的哈希值。
d,在bucket[2]存儲0。
三,通過key獲取對應的value, var v=Set["a"];
a, 先計算"a"的哈希值,假如結果為2,
b,根據上一步驟結果,找到buckets數組索引為2上的值,假如該值為0.
c, 找到到slots數組上索引為0的key,
1),如果該key值和輸入的的“a”字元相同,則對應的value值就是需要查找的值。
2) ,如果該key值和輸入的"a"字元不相同,說明發生了碰撞,這時獲取對應的next值,根據next值定位buckets數組(buckets[next]),然後獲取對應buckets上存儲的值在定位到slots數組上,......,一直到找到為止。
3),如果該key值和輸入的"a"字元不相同並且對應的next值為-1,則說明Set<T>不包含字元“a”。
至此,我們再回過頭來,看看代碼,我想不攻自破!不明白的請多多想想,不要老問!
再次測試下看下結果(這些方法我用擴展方法,沒事的朋友可以自已寫下,代碼在上面已經貼出,這裡主要看的比較直觀些)
DateTime now = DateTime.Now; Set<string> iteratorVariable = new Set<string>(null); foreach (var local in remove) { iteratorVariable.Add(local); } foreach (var local in source) { if (!iteratorVariable.Add(local)) { continue; } } Console.WriteLine("Running time:" + (DateTime.Now - now).TotalSeconds); Console.ReadKey();
想來想去,還是把它改成擴張方法吧,不然有人會問我,如何改?
var r = source.Iterator(remove, null);
僅僅還是一句話,實現了上述等同的方法!
所消耗時間Running time:0.0112076..s
看到沒,與上面的例子性能上相差不大。但是也遠遠超過了前面三個例子。而且也是自動擴容的,引入了hashcode碰撞,這是一種思想,很多.net字典也是基於這種原理實現的。沒事的同學可以看看.net 相關源碼。
最後我想說的一件事,在個方法其它等同於Except<IEnumerable<T>>(),在Linq .net 3.5+微軟已經給我們實現。
請不要罵我,剛開始我也不知道這個方法,寫著寫著想起來了。微軟的進步,正悄悄的把我們省了很多事。然後,依據微軟的方法進行改進而來。
到這裡,不知不覺的你已經學會了一種‘演算法’。即使微軟提供了我們現成的方法,也不足為奇!必竟思想的提練是我們最終的目標!
參考資料
1. MSDN, IEquatable<T>, http://msdn.microsoft.com/en-us/library/ms131187.aspx;
2. MSDN IEqualityComparer, http://msdn.microsoft.com/en-us/library/ms132151.aspx;
3.MSDN IEqualityComparer,https://msdn.microsoft.com/en-us/library/ms132072(v=vs.110).aspx
4.Enumerable.Except<TSource> Method(IEnumerable<TSource>, IEnumerable<TSource>),https://msdn.microsoft.com/en-us/library/bb300779(v=vs.110).aspx
作者:谷歌's(谷歌's博客園)
出處:http://www.cnblogs.com/laogu2/ 歡迎轉載,但任何轉載必須保留完整文章,在顯要地方顯示署名以及原文鏈接。如您有任何疑問或者授權方面的協商,請給我留言。

