
Apache Spark是一個圍繞速度、易用性和複雜分析構建的大數據處理框架,最初在2009年由加州大學伯克利分校的AMPLab開發,並於2010年成為Apache的開源項目之一,與Hadoop和Storm等其他大數據和MapReduce技術相比,Spark有如下優勢: Spark提供了一個全面、統 ...
Apache Spark是一個圍繞速度、易用性和複雜分析構建的大數據處理框架,最初在2009年由加州大學伯克利分校的AMPLab開發,並於2010年成為Apache的開源項目之一,與Hadoop和Storm等其他大數據和MapReduce技術相比,Spark有如下優勢:
- Spark提供了一個全面、統一的框架用於管理各種有著不同性質(文本數據、圖表數據等)的數據集和數據源(批量數據或實時的流數據)的大數據處理的需求
- 官方資料介紹Spark可以將Hadoop集群中的應用在記憶體中的運行速度提升100倍,甚至能夠將應用在磁碟上的運行速度提升10倍
目標:
- 架構及生態
- spark 與 hadoop
- 運行流程及特點
- 常用術語
- standalone模式
- yarn集群
- RDD運行流程
架構及生態:
- 通常當需要處理的數據量超過了單機尺度(比如我們的電腦有4GB的記憶體,而我們需要處理100GB以上的數據)這時我們可以選擇spark集群進行計算,有時我們可能需要處理的數據量並不大,但是計算很複雜,需要大量的時間,這時我們也可以選擇利用spark集群強大的計算資源,並行化地計算,其架構示意圖如下:

- Spark Core:包含Spark的基本功能;尤其是定義RDD的API、操作以及這兩者上的動作。其他Spark的庫都是構建在RDD和Spark Core之上的
- Spark SQL:提供通過Apache Hive的SQL變體Hive查詢語言(HiveQL)與Spark進行交互的API。每個資料庫表被當做一個RDD,Spark SQL查詢被轉換為Spark操作。
- Spark Streaming:對實時數據流進行處理和控制。Spark Streaming允許程式能夠像普通RDD一樣處理實時數據
- MLlib:一個常用機器學習演算法庫,演算法被實現為對RDD的Spark操作。這個庫包含可擴展的學習演算法,比如分類、回歸等需要對大量數據集進行迭代的操作。
- GraphX:控製圖、並行圖操作和計算的一組演算法和工具的集合。GraphX擴展了RDD API,包含控製圖、創建子圖、訪問路徑上所有頂點的操作
- Spark架構的組成圖如下:
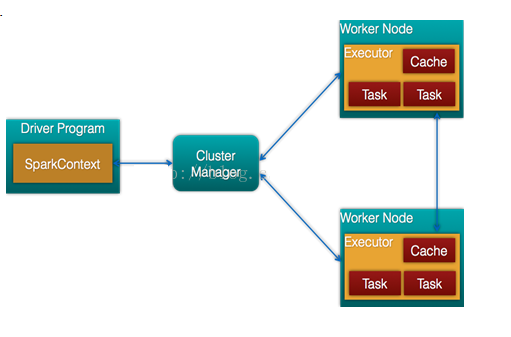
- Cluster Manager:在standalone模式中即為Master主節點,控制整個集群,監控worker。在YARN模式中為資源管理器
- Worker節點:從節點,負責控制計算節點,啟動Executor或者Driver。
- Driver: 運行Application 的main()函數
- Executor:執行器,是為某個Application運行在worker node上的一個進程
Spark與hadoop:
- Hadoop有兩個核心模塊,分散式存儲模塊HDFS和分散式計算模塊Mapreduce
- spark本身並沒有提供分散式文件系統,因此spark的分析大多依賴於Hadoop的分散式文件系統HDFS
- Hadoop的Mapreduce與spark都可以進行數據計算,而相比於Mapreduce,spark的速度更快並且提供的功能更加豐富
- 關係圖如下:

運行流程及特點:
- spark運行流程圖如下:

- 構建Spark Application的運行環境,啟動SparkContext
- SparkContext向資源管理器(可以是Standalone,Mesos,Yarn)申請運行Executor資源,並啟動StandaloneExecutorbackend,
- Executor向SparkContext申請Task
- SparkContext將應用程式分發給Executor
- SparkContext構建成DAG圖,將DAG圖分解成Stage、將Taskset發送給Task Scheduler,最後由Task Scheduler將Task發送給Executor運行
- Task在Executor上運行,運行完釋放所有資源
Spark運行特點:
- 每個Application獲取專屬的executor進程,該進程在Application期間一直駐留,並以多線程方式運行Task。這種Application隔離機制是有優勢的,無論是從調度角度看(每個Driver調度他自己的任務),還是從運行角度看(來自不同Application的Task運行在不同JVM中),當然這樣意味著Spark Application不能跨應用程式共用數據,除非將數據寫入外部存儲系統
- Spark與資源管理器無關,只要能夠獲取executor進程,並能保持相互通信就可以了
- 提交SparkContext的Client應該靠近Worker節點(運行Executor的節點),最好是在同一個Rack里,因為Spark Application運行過程中SparkContext和Executor之間有大量的信息交換
- Task採用了數據本地性和推測執行的優化機制
常用術語:
- Application: Appliction都是指用戶編寫的Spark應用程式,其中包括一個Driver功能的代碼和分佈在集群中多個節點上運行的Executor代碼
- Driver: Spark中的Driver即運行上述Application的main函數並創建SparkContext,創建SparkContext的目的是為了準備Spark應用程式的運行環境,在Spark中有SparkContext負責與ClusterManager通信,進行資源申請、任務的分配和監控等,當Executor部分運行完畢後,Driver同時負責將SparkContext關閉,通常用SparkContext代表Driver
- Executor: 某個Application運行在worker節點上的一個進程, 該進程負責運行某些Task, 並且負責將數據存到記憶體或磁碟上,每個Application都有各自獨立的一批Executor, 在Spark on Yarn模式下,其進程名稱為CoarseGrainedExecutor Backend。一個CoarseGrainedExecutor Backend有且僅有一個Executor對象, 負責將Task包裝成taskRunner,並從線程池中抽取一個空閑線程運行Task, 這個每一個oarseGrainedExecutor Backend能並行運行Task的數量取決與分配給它的cpu個數
- Cluter Manager:指的是在集群上獲取資源的外部服務。目前有三種類型
- Standalon : spark原生的資源管理,由Master負責資源的分配
- Apache Mesos:與hadoop MR相容性良好的一種資源調度框架
- Hadoop Yarn: 主要是指Yarn中的ResourceManager
- Worker: 集群中任何可以運行Application代碼的節點,在Standalone模式中指的是通過slave文件配置的Worker節點,在Spark on Yarn模式下就是NoteManager節點
- Task: 被送到某個Executor上的工作單元,但hadoopMR中的MapTask和ReduceTask概念一樣,是運行Application的基本單位,多個Task組成一個Stage,而Task的調度和管理等是由TaskScheduler負責
- Job: 包含多個Task組成的並行計算,往往由Spark Action觸發生成, 一個Application中往往會產生多個Job
- Stage: 每個Job會被拆分成多組Task, 作為一個TaskSet, 其名稱為Stage,Stage的劃分和調度是有DAGScheduler來負責的,Stage有非最終的Stage(Shuffle Map Stage)和最終的Stage(Result Stage)兩種,Stage的邊界就是發生shuffle的地方
- DAGScheduler: 根據Job構建基於Stage的DAG(Directed Acyclic Graph有向無環圖),並提交Stage給TASkScheduler。 其劃分Stage的依據是RDD之間的依賴的關係找出開銷最小的調度方法,如下圖

- TASKSedulter: 將TaskSET提交給worker運行,每個Executor運行什麼Task就是在此處分配的. TaskScheduler維護所有TaskSet,當Executor向Driver發生心跳時,TaskScheduler會根據資源剩餘情況分配相應的Task。另外TaskScheduler還維護著所有Task的運行標簽,重試失敗的Task。下圖展示了TaskScheduler的作用

- 在不同運行模式中任務調度器具體為:
- Spark on Standalone模式為TaskScheduler
- YARN-Client模式為YarnClientClusterScheduler
- YARN-Cluster模式為YarnClusterScheduler
- 將這些術語串起來的運行層次圖如下:

- Job=多個stage,Stage=多個同種task, Task分為ShuffleMapTask和ResultTask,Dependency分為ShuffleDependency和NarrowDependency
Spark運行模式:
- Spark的運行模式多種多樣,靈活多變,部署在單機上時,既可以用本地模式運行,也可以用偽分佈模式運行,而當以分散式集群的方式部署時,也有眾多的運行模式可供選擇,這取決於集群的實際情況,底層的資源調度即可以依賴外部資源調度框架,也可以使用Spark內建的Standalone模式。
- 對於外部資源調度框架的支持,目前的實現包括相對穩定的Mesos模式,以及hadoop YARN模式
- 本地模式:常用於本地開發測試,本地還分別 local 和 local cluster
standalone: 獨立集群運行模式
- Standalone模式使用Spark自帶的資源調度框架
- 採用Master/Slaves的典型架構,選用ZooKeeper來實現Master的HA
- 框架結構圖如下:

- 該模式主要的節點有Client節點、Master節點和Worker節點。其中Driver既可以運行在Master節點上中,也可以運行在本地Client端。當用spark-shell互動式工具提交Spark的Job時,Driver在Master節點上運行;當使用spark-submit工具提交Job或者在Eclips、IDEA等開發平臺上使用”new SparkConf.setManager(“spark://master:7077”)”方式運行Spark任務時,Driver是運行在本地Client端上的
- 運行過程如下圖:(參考至:http://blog.csdn.net/gamer_gyt/article/details/51833681)

- SparkContext連接到Master,向Master註冊並申請資源(CPU Core 和Memory)
- Master根據SparkContext的資源申請要求和Worker心跳周期內報告的信息決定在哪個Worker上分配資源,然後在該Worker上獲取資源,然後啟動StandaloneExecutorBackend;
- StandaloneExecutorBackend向SparkContext註冊;
- SparkContext將Applicaiton代碼發送給StandaloneExecutorBackend;並且SparkContext解析Applicaiton代碼,構建DAG圖,並提交給DAG Scheduler分解成Stage(當碰到Action操作時,就會催生Job;每個Job中含有1個或多個Stage,Stage一般在獲取外部數據和shuffle之前產生),然後以Stage(或者稱為TaskSet)提交給Task Scheduler,Task Scheduler負責將Task分配到相應的Worker,最後提交給StandaloneExecutorBackend執行;
- StandaloneExecutorBackend會建立Executor線程池,開始執行Task,並向SparkContext報告,直至Task完成
- 所有Task完成後,SparkContext向Master註銷,釋放資源
yarn: (參考:http://blog.csdn.net/gamer_gyt/article/details/51833681)
- Spark on YARN模式根據Driver在集群中的位置分為兩種模式:一種是YARN-Client模式,另一種是YARN-Cluster(或稱為YARN-Standalone模式)
- Yarn-Client模式中,Driver在客戶端本地運行,這種模式可以使得Spark Application和客戶端進行交互,因為Driver在客戶端,所以可以通過webUI訪問Driver的狀態,預設是http://hadoop1:4040訪問,而YARN通過http:// hadoop1:8088訪問
- YARN-client的工作流程步驟為:
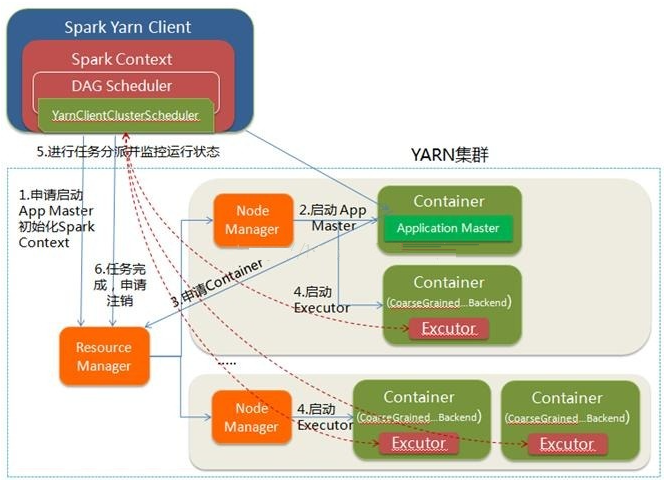
- Spark Yarn Client向YARN的ResourceManager申請啟動Application Master。同時在SparkContent初始化中將創建DAGScheduler和TASKScheduler等,由於我們選擇的是Yarn-Client模式,程式會選擇YarnClientClusterScheduler和YarnClientSchedulerBackend
- ResourceManager收到請求後,在集群中選擇一個NodeManager,為該應用程式分配第一個Container,要求它在這個Container中啟動應用程式的ApplicationMaster,與YARN-Cluster區別的是在該ApplicationMaster不運行SparkContext,只與SparkContext進行聯繫進行資源的分派
- Client中的SparkContext初始化完畢後,與ApplicationMaster建立通訊,向ResourceManager註冊,根據任務信息向ResourceManager申請資源(Container)
- 一旦ApplicationMaster申請到資源(也就是Container)後,便與對應的NodeManager通信,要求它在獲得的Container中啟動CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend啟動後會向Client中的SparkContext註冊並申請Task
- client中的SparkContext分配Task給CoarseGrainedExecutorBackend執行,CoarseGrainedExecutorBackend運行Task並向Driver彙報運行的狀態和進度,以讓Client隨時掌握各個任務的運行狀態,從而可以在任務失敗時重新啟動任務
- 應用程式運行完成後,Client的SparkContext向ResourceManager申請註銷並關閉自己
Spark Cluster模式:
- 在YARN-Cluster模式中,當用戶向YARN中提交一個應用程式後,YARN將分兩個階段運行該應用程式:
- 第一個階段是把Spark的Driver作為一個ApplicationMaster在YARN集群中先啟動;
- 第二個階段是由ApplicationMaster創建應用程式,然後為它向ResourceManager申請資源,並啟動Executor來運行Task,同時監控它的整個運行過程,直到運行完成
- YARN-cluster的工作流程分為以下幾個步驟

- Spark Yarn Client向YARN中提交應用程式,包括ApplicationMaster程式、啟動ApplicationMaster的命令、需要在Executor中運行的程式等
- ResourceManager收到請求後,在集群中選擇一個NodeManager,為該應用程式分配第一個Container,要求它在這個Container中啟動應用程式的ApplicationMaster,其中ApplicationMaster進行SparkContext等的初始化
- ApplicationMaster向ResourceManager註冊,這樣用戶可以直接通過ResourceManage查看應用程式的運行狀態,然後它將採用輪詢的方式通過RPC協議為各個任務申請資源,並監控它們的運行狀態直到運行結束
- 一旦ApplicationMaster申請到資源(也就是Container)後,便與對應的NodeManager通信,要求它在獲得的Container中啟動CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend啟動後會向ApplicationMaster中的SparkContext註冊並申請Task。這一點和Standalone模式一樣,只不過SparkContext在Spark Application中初始化時,使用CoarseGrainedSchedulerBackend配合YarnClusterScheduler進行任務的調度,其中YarnClusterScheduler只是對TaskSchedulerImpl的一個簡單包裝,增加了對Executor的等待邏輯等
- ApplicationMaster中的SparkContext分配Task給CoarseGrainedExecutorBackend執行,CoarseGrainedExecutorBackend運行Task並向ApplicationMaster彙報運行的狀態和進度,以讓ApplicationMaster隨時掌握各個任務的運行狀態,從而可以在任務失敗時重新啟動任務
- 應用程式運行完成後,ApplicationMaster向ResourceManager申請註銷並關閉自己
Spark Client 和 Spark Cluster的區別:
- 理解YARN-Client和YARN-Cluster深層次的區別之前先清楚一個概念:Application Master。在YARN中,每個Application實例都有一個ApplicationMaster進程,它是Application啟動的第一個容器。它負責和ResourceManager打交道並請求資源,獲取資源之後告訴NodeManager為其啟動Container。從深層次的含義講YARN-Cluster和YARN-Client模式的區別其實就是ApplicationMaster進程的區別
- YARN-Cluster模式下,Driver運行在AM(Application Master)中,它負責向YARN申請資源,並監督作業的運行狀況。當用戶提交了作業之後,就可以關掉Client,作業會繼續在YARN上運行,因而YARN-Cluster模式不適合運行交互類型的作業
- YARN-Client模式下,Application Master僅僅向YARN請求Executor,Client會和請求的Container通信來調度他們工作,也就是說Client不能離開
思考: 我們在使用Spark提交job時使用的哪種模式?
RDD運行流程:
- RDD在Spark中運行大概分為以下三步:
- 創建RDD對象
- DAGScheduler模塊介入運算,計算RDD之間的依賴關係,RDD之間的依賴關係就形成了DAG
- 每一個Job被分為多個Stage。劃分Stage的一個主要依據是當前計算因數的輸入是否是確定的,如果是則將其分在同一個Stage,避免多個Stage之間的消息傳遞開銷
- 示例圖如下:

- 以下麵一個按 A-Z 首字母分類,查找相同首字母下不同姓名總個數的例子來看一下 RDD 是如何運行起來的

- 創建 RDD 上面的例子除去最後一個 collect 是個動作,不會創建 RDD 之外,前面四個轉換都會創建出新的 RDD 。因此第一步就是創建好所有 RDD( 內部的五項信息 )?
- 創建執行計劃 Spark 會儘可能地管道化,並基於是否要重新組織數據來劃分 階段 (stage) ,例如本例中的 groupBy() 轉換就會將整個執行計劃劃分成兩階段執行。最終會產生一個 DAG(directed acyclic graph ,有向無環圖 ) 作為邏輯執行計劃
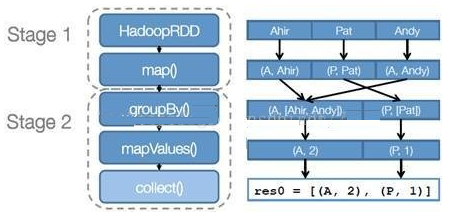
- 調度任務 將各階段劃分成不同的 任務 (task) ,每個任務都是數據和計算的合體。在進行下一階段前,當前階段的所有任務都要執行完成。因為下一階段的第一個轉換一定是重新組織數據的,所以必須等當前階段所有結果數據都計算出來了才能繼續

