
一直想抽個時間整理下最近的所學,斷斷續續接觸hive也有半個多月了,大體上瞭解了很多Hive相關的知識。那麼,一般對陌生事物的認知都會經歷下麵幾個階段: 為什麼會出現?解決了什麼問題? 如何搭建?如何使用? 如何精通? 我會在本篇粗略的介紹下前兩個問題,然後給一些相關的資料。第三個問題,就得慢慢靠實 ...
一直想抽個時間整理下最近的所學,斷斷續續接觸hive也有半個多月了,大體上瞭解了很多Hive相關的知識。那麼,一般對陌生事物的認知都會經歷下麵幾個階段:
- 為什麼會出現?解決了什麼問題?
- 如何搭建?如何使用?
- 如何精通?
我會在本篇粗略的介紹下前兩個問題,然後給一些相關的資料。第三個問題,就得慢慢靠實踐和時間積累了。
如果有什麼問題,可以直接留言!
為什麼出現?解決了什麼問題?
背景
說到這個問題,還得先說個小故事,在很久很久以前....
有一個叫facebook的賊有名的公司,他們內部搭建了數據倉庫(你可以理解成把一大堆數據放到一個地方,然後做報表給老闆看!),是基於mysql的。後來隨著數據量的不斷增加,這種傳統的資料庫扛不住了...於是經過一系列的折騰換到了hadoop上(hadoop是個大數據體系,用的是裡面的hdfs,做存儲的。你可以理解成搞一堆破爛機器湊成個集群,然後存儲超級多的數據)。
問題來了!
以前基於資料庫的數據倉庫用sql就能做查詢,現在換到hdfs上面,得跑Mapreduce任務去做分析,這樣以前做分析的人還得學mapreduce,好難呀!
於是...他們就開發了一套框架就是用sql來做hdfs的查詢(用戶輸入的是sql,框架內部把sql轉成mapreduce的任務,然後再去跑分析)。

於是,Hive誕生了...看看上面同樣是wordcount,mapreduce和hive的區別,能看到效果了吧。
解決的問題
Hive基於類似SQL的語言完成對hdfs數據的查詢分析。
那麼它到底做了什麼呢?
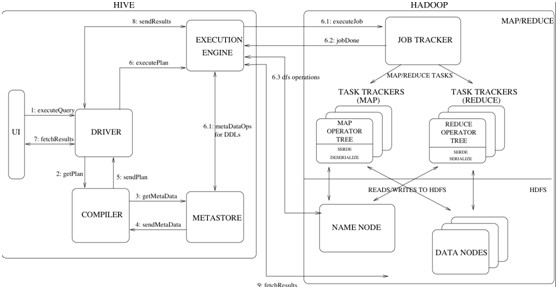
- 1 它支持各種命令,比如dfs的命令、腳本的執行
- 2 如果你輸入的是sql,它會交給一個叫做Driver的東東,去編譯解析。
- 3 把編譯出來的東西交給hadoop去跑...然後返回查詢結果。
說了這麼多,其實你就可以把hive理解成搭建在hadoop(hdfs和mapreduce)之上的語言殼子...
如何搭建?如何使用?
搭建的可以參考這篇,感覺已經寫的很詳細了。
學習如何使用Hive還是個很重要的部分的!這裡就不詳細的說了,都舉個小例子,具體的還是去擼官網吧!
創建
在Hive裡面創建表和在普通的資料庫中創建表示類似的,都是先創建(或者使用預設的)資料庫,然後創建表。
create database xxx; -- 創建資料庫
use xxx; --使用資料庫
create table student(id string,name string,age int); --創建表導入導出數據
數據的導入最常用的就是從hdfs的文件導入或者本地文件導入,也可以從某個查詢結果直接創建或者導入。
Hive還支持把查詢結果導出到文件...
查詢
最普通的查詢,就是select from句式了,Hive還是做得比較通用的
--普通查詢
select * from xxx;
--帶條件的查詢
select * from xxx where age>30;
--限制返回列
select name,age from xxx;
--內連接
select a.*,b.* from tablea a join tableb b on a.id=b.sid;
--左連接
select * from a left outer join b on a.id=b.sid;
--右連接
select * from a right outer join b on a.id=b.sid;函數
Hive支持一大堆的函數,比如普通的函數UDF:
floor、ceil、rand、cast等等還支持聚合類型的函數UDAF:
count、avg、min、max、sum還支持生成多行的函數。
更厲害的是,支持自定義擴展~~ 比如你們公司有個mapreduce的專家,可以封裝很多的函數,然後別的會sql的分析人員,就可以使用這些函數做數據倉庫的分析了。
存儲
首先需要說明的是,Hive在存儲的時候是不做任何處理的。不像是資料庫,存進去的數據要先進行特定的解析,比如解析成一個一個的欄位,然後挨個存儲。每個資料庫的存儲引擎不同,解析的方式就不太一樣。
在Hive中的數據都是存儲在hdfs中的,如果沒有特殊的聲明,會以文本的形式存儲,即不會再存儲前做任何操作。簡直就相當於是原封不動的拷貝。當你執行查詢的時候,會按照預先指定的解析規則解析,然後返回。
舉個例子更好理解點:
你的文件:
1,a
2,b
3,c
那麼創建表的時候會這樣:
create table xxx(a string,b string) row format delimited fields terminated by ',';
這個fields terminated by ','就聲明瞭欄位按照逗號進行分割。
那麼當hive執行查詢的時候,就會遍歷文件,遇到逗號就分隔成一個欄位~最後把結果返回。畢竟hdfs還是按照塊來存儲數據的....這也是為什麼Hive不支持局部的修改和刪除,只能整體的覆蓋、刪除。
除了前面說的文本格式(TextFile),Hive還支持SequenceFile、RCFile,各有各的優勢。sequenceFile相當於把數據切分了,然後可以局部的記錄或者塊進行壓縮。RCFile則是列式存儲,這樣可以提高壓縮比;還可以在查詢的時候跳過不必要的列。
分區
在Hive中資料庫和表其實都是hdfs中的一個目錄,比如你的a資料庫下的表b,存儲的路徑是這樣的:
/user/hive/warehouse/a.db/b
後面兩個部分a.db/b是很關鍵的,即“資料庫名.db/表名”在Hive還支持分區的概念。即按照某個特定的欄位,對錶進行劃分。通常這個欄位都是虛擬的,比如時間....
create table aa(a string,b string) partitioned by(c string);這樣就創建了分區表,如果c欄位有"aaa"和"bbb"兩個值,最終的目錄就是醬嬸的!
/user/hive/warehouse/a.db/b/c=aaa
/user/hive/warehouse/a.db/b/c=bbb註意都是目錄哦!真正的文件在這些目錄下麵。
由於都是目錄,就很好理解,為什麼分區查詢會快了!因為在hive中所有的查詢,基本都相當於是全表的掃描,因此要是能通過分區欄位進行過濾,那麼可以跳過很多不必要的文件了。
在Hive中支持靜態分區(即你導數據的時候指定分區欄位的值)、動態分區(按照欄位的值來定分區的名稱)。需要註意的是,動態分區會有很多潛在的風險,比如太多了!所以一定要合理規劃你的表存儲的設計。
索引
在hive0.7.0+的版本中,也是支持索引的。比如:
CREATE INDEX table02_index ON TABLE table02 (column3) AS 'COMPACT' WITH DEFERRED REBUILD;
CREATE INDEX table03_index ON TABLE table03 (column4) AS 'BITMAP' WITH DEFERRED REBUILD;你也可以自定義索引的實現類,只要替換AS ''裡面的東西,變成自己的包名類名就行。
不過一樣的,添加索引雖然會加快索引。可是也意味著增加了存儲的負擔...所以自己衡量吧!
資源共用
安利個論壇,自願傳播的東西才是好東西——about雲,加裡面的群,每天都有精華分享。
無論是學習什麼,官方文檔總是最好的材料。

另外推薦一本書,反正也沒其他的書可以看——《Hive編程指南》


