
當一切正常時,沒有必要特別留意什麼是事務日誌,它是如何工作的。你只要確保每個資料庫都有正確的備份。當出現問題時,事務日誌的理解對於採取修正操作是重要的,尤其在需要緊急恢複數據庫到指定點時。這系列文章會告訴你每個DBA應該知道的具體細節。對於在我們關註下的所有資料庫,在日誌維護方面,我們的首要目標是最...
當一切正常時,沒有必要特別留意什麼是事務日誌,它是如何工作的。你只要確保每個資料庫都有正確的備份。當出現問題時,事務日誌的理解對於採取修正操作是重要的,尤其在需要緊急恢複數據庫到指定點時。這系列文章會告訴你每個DBA應該知道的具體細節。
對於在我們關註下的所有資料庫,在日誌維護方面,我們的首要目標是最優化寫性能,為了支持SQL Server寫入日誌的所有活動,包括數據修改,數據讀取,索引維護等等。但是,留意下可能的日誌碎片也是重要的,如前面文章介紹的,它會影響需要讀取日誌的過程性能,例如日誌備份和故障恢復過程。
已經配置了合適的物理日誌架構和日誌文件大小,如第8篇所講的,這篇文章會介紹一些可以監控事務日誌大小、增長和活動的方法,為了即時收到異常警告或日誌暴漲,日誌碎片等等。
註意,我們把這篇文章作為全面覆蓋日誌監控的解決方案。例如,我們沒有提供使用擴展事件(Extend Events)進行日誌、SQL Server數據控制器/管理資料庫倉庫(自SQL Server 2008以後的版本即有)的監控。可以查看下這篇文章最後的擴展閱讀部分來看下這些話題的詳細信息。
不管怎樣,我們會討論最常見的監控工具和技術,包括:
- 監控工具——簡單介紹Windows Performance Monitor和Red Gate SQL Monitor
- 使用動態管理對象——在伺服器、文件、資料庫等級別上查看日誌活動
- 使用T-SQL或PowerShell腳本——在所有的伺服器上統計日誌特性和使用率
監控工具
有一些可用的工具,除了別的之外,允許我們在我們的資料庫文件監控活動,包括日誌文件。這裡,我們只簡單介紹兩個,內建的工具(Windows性能監視器)和第三方工具(Red Gate SQL Monitor)。
Windows性能監視器(Windows Perfmon)
對於監控SQL Server活動一個流行的“內建”工具是Windows性能監視器(Perfmon)。它是一個系統監控工具,對伺服器上的記憶體、硬碟I/O、網路使用的監控提供不同計數器,也包括SQL Server的計數器。通常,DBA或系統管理員會從不同的計數器里配置性能監視器,定期記錄統計信息,把數據存入文件,然後導入Excel或類似工具,進行分析。
在多個計數器中,它提供一個數字來衡量磁碟讀寫性能,也有對日誌監控的特定計數器。
在使用性能監視器上,有很多可用的教程,我們不會在這裡重覆這些細節。另外在TechNet上有個文檔,我們建議這個工具的新手來閱讀下列文章:
- Brent Ozar寫的《SQL Server Permon最佳實踐》,一篇這個工具使用的綜合教程,對於SQL Server的一些推薦計數器,如何分析和以Excel保存。
- BradMcGehee寫的《SQL Server Profile與性能監視器的結合》。性能監視器使用的一個快速上手教程,還有如何用監控數據結合Profile來跟蹤數據。
- Brent Ozar的《基線化和基準測試》。一個提供如何使用性能監視器、Profiler概括介紹的視頻教程,包括為什麼和如何進行基準測試。
談到如何對保存日誌(和數據)文件磁碟的常規測試,我們可以監控下列這些成對計數器:
- Physical Disk\Disk Reads/sec 和 Physical Disk\Disk Writes/sec——我們需要知道這些計數器的值,先建立基線,來看看哪些顯著上升,並調查原因。
- Physical Disk\Avg. Disk sec/Read 和 Physical Disk\Avg. Disk sec/Write——讀寫磁碟的平均時間(毫秒),這些計數器提供磁碟延遲統計信息,可以用來確定潛在的I/O瓶頸。
通常來說磁碟延遲計數器建議:低於10毫秒是優秀,20-30毫秒是好,如果超過50毫秒可以認為是個可能的I/O瓶頸。當然,這些指標取決於你環境里磁碟陣列的規格和配置。
我們簡單演示下Perfmon工具的使用,對一個正在頻繁寫的資料庫,設置下Physical Disk\Avg.Disk sec/Read 和 Physical Disk\Avg. Disk sec/Write counters 作為監控的計數器。
例如,我們對第8篇里,重新創建新版本的Persons資料庫和表的操作進行監控。
點擊開始,運行,輸入Perfmon。在【數據收集器集】【用戶定義】,右擊【新建】【數據收集器集】,選擇【手動創建(高級)】,點擊【下一步】,選擇【創建數據日誌】,勾選【性能計數器】,點擊【下一步】,點擊【添加】,選擇剛纔說的計數器(選擇【PhysicalDisk】),註意定位自己資料庫文件的所在硬碟。
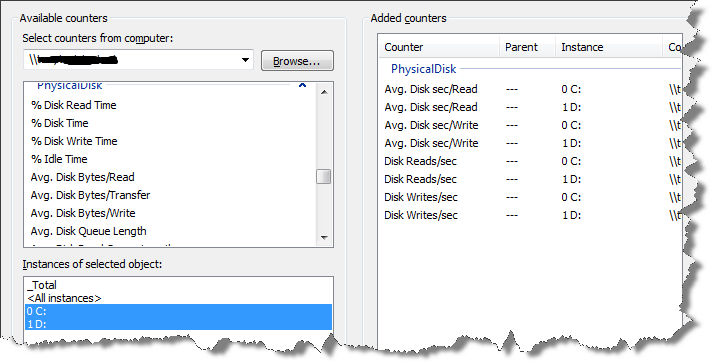
插圖9.1:配置性能監視器
點擊【確定】後,回到嚮導界面,點擊【完成】。
現在我們可以計劃執行這個新的數據採集集。當然,這裡我右擊,點擊【開始】(一會後,新建的數據數據收集器開始位置會有綠色播放標誌出現)。回到SSMS,我們運行如下所示的代碼9.1,創建一個在我們的Persons資料庫頻繁寫。
1 USE Persons 2 GO 3 DECLARE @cnt INT; 4 5 SET @cnt = 1; 6 -- may take several minutes; reduce the number of loops, if required 7 WHILE @cnt < 6 8 BEGIN; 9 SET @cnt = @cnt + 1; 10 UPDATE dbo.Persons 11 SET Email = LEFT(Email + Email, 7000) 12 END;
代碼9.1:更新Person表
一旦代碼執行完成,回到性能監視器,右鍵剛纔的資料庫收集集,點擊【結束】,回到【報告】【用戶定義】【新的數據收集器集】,定為到剛纔對應的報告,如插圖9.2所示:

插圖9.2:硬碟讀寫活動快照,使用PerfMon。
你可以選擇和取消選擇要顯示你要想要顯示的計數器,通過雙擊其中任何一代,在圖表下的計數器列表裡,你可以在圖上修改它們的樣子,拉伸等等。你可以通過點擊圖表放大圖表區域,拖拽到需要高亮顯示的區域,然後點擊頂部菜單的放大鏡工具(使用底部的滑條回到剛纔的區域)。
在圖上最活躍的部分是在D盤上的寫,那裡有我們的日誌文件。我們可以看到那個期間,延遲有近40毫秒,有頻繁的峰值。我們可以使用在頂部菜單的【更改圖形類型】來修改為【報表】方式,報表顯示在D盤上的平均延遲為55毫秒,這是一個需要考慮是時間段。當然,很多其他PhysicalDisk的計數器,可以提供你磁碟內部性能的內幕信息,在我們下結論前要好好仔細分析下。
另外,同樣的方式,我們也可以收集其他相關的計數器,例如在SQL Server:Databases。這個對象提供日誌活動的各種計數器,也包括其他。
- Log File(s) Size (KB) ——資料庫中所有事務日誌文件的累計大小 (KB)。
- Log File(s) Used Size (KB)——資料庫中所有日誌文件的累計已用大小。
Red Gate SQL Monitor
如果你使用第三方SQL Server監控工具,很有可能它會對計數器的很多值,收集、存儲並分析。插圖9.3在Red Gate SQL Monitor里展示了日誌文件大小值,對於Persons資料庫的日誌文件在快速增長,因為不正確的大小和配置的日誌。

插圖9.3:SQL Monitor報告的快速日誌增長
SQL Monitor的一個不錯的功能是,與Perfmon相比它更加簡單、容易,在不同期間之間比較同類型的活動。在下拉的時間段(Time range)里,我們可以修改時間段,設置自定義的段,從今天(或這個星期)與昨天(或上個星期)進行比較等等。
動態管理視圖和函數(DMV、DMF)
很多DMV(動態管理視圖或函數的縮寫(Dynamic Management Views and Functions))提供SQL Server引擎內部如何使用磁碟I/O子系統,子系統與I/O輸出能力及系統性能要求的工作量。例如:
- sys.dm_io_virtual_file_stats——提供所有資料庫數據和日誌文件的使用率統計信息。它是發現熱點的好資源,標識出在不同頻道傳播的機會。
- sys.dm_io_pending_io_requests——提供SQL Server所有等待完成的I/O操作的列表。
到操作系統級別,DMV的“sys.dm_os_”類型提供在SQL Server和操作系統之間交互的大量不同數據。這個提供了提交請求到操作系統里實際工作的具體工作量呈現。註意,sys.dm_os_wait_stats記錄了每次一個在完成它工作需要等待時間的長短,請求的資源。它是用來找出什麼引起回話等待的實用DMV,當然包括I/O等待。
DMV的“sys.dm_os_”類型也提供sys.dm_os_performance_counters,它展示了性能計數器,還有在我們系統里的隊列。通過不同資源衡量,例如每秒磁碟讀寫,處理器隊列長度,可用記憶體等等。它幫助我們找出請求給定資源的地方,還有過多要求的理由。
到資料庫級別,SQL Sever 2012添加了sys.dm_db_log_space_usage的DMV,提供了一個獲得基本事務日誌大小和空間使用率數據的非常簡單的方式,和通過DBCC SQLPERF(LOGSPACE)返回的類似。
這裡,我們只演示3個例子,首先是sys.dm_db_log_space_usage,然後是sys.dm_io_virtual_file_stats,最後是ys.dm_os_performance_counters,顯示日誌活動和增長的詳細信息。
使用sys.dm_db_log_space_usage(僅SQL Server 2012)
如果你已經使用SQL Server 2012,那麼獲取基本日誌大小和空間信息非常簡單,如代碼9.2所示。我們在Persons2012資料庫上運行這個代碼,和Persons資料庫一樣,除了名稱。
1 SELECT DB_NAME(database_id) AS DatabaseName , 2 database_id , 3 CAST(( total_log_size_in_bytes / 1048576.0 ) AS DECIMAL(10, 1)) 4 AS TotalLogSizeMB , 5 CAST(( used_log_space_in_bytes / 1048576.0 ) AS DECIMAL(10, 1)) 6 AS LogSpaceUsedMB , 7 CAST(used_log_space_in_percent AS DECIMAL(10, 1)) AS LogSpaceUsedPercent 8 FROM sys.dm_db_log_space_usage;

代碼9.2:日誌大小和空間使用
使用sys.dm_io_virtual_file_stats
對於每個SQL Server使用的資料庫文件,數據文件和日誌文件,sys.dm_io_virtual_file_stats 提供了累計的物理I/O統計信息,表明自上一次伺服器重啟後,用作被資料庫讀寫的文件的使用頻率。它也提供了在"I/O停滯"時間形式里一個非常有用的維度,表明用戶處理需要等待完成的I/O總時間,在文件問題里。註意這個DMV只衡量物理I/O。從緩存讀取的邏輯I/O操作不會在這裡顯示。這個函數接受資料庫ID(database_id)和文件ID(file_id),我們可以用來調查特定文件或資料庫,或者我們可以直接返回伺服器上的所有資料庫。
為了從一張白紙開始,重新運行Persons腳本來刪除和重建Persons資料庫和表,並插入100萬條記錄,然後運行代碼9.3忘臨時表裡插入伺服器的一些基線數據。
1 SELECT DB_NAME(mf.database_id) AS databaseName , 2 mf.physical_name , 3 divfs.num_of_reads , 4 divfs.num_of_bytes_read , 5 divfs.io_stall_read_ms , 6 divfs.num_of_writes , 7 divfs.num_of_bytes_written , 8 divfs.io_stall_write_ms , 9 divfs.io_stall , 10 size_on_disk_bytes , 11 GETDATE() AS baselineDate 12 INTO #baseline 13 FROM sys.dm_io_virtual_file_stats(NULL, NULL) AS divfs 14 JOIN sys.master_files AS mf ON mf.database_id = divfs.database_id 15 AND mf.file_id = divfs.file_id
代碼9.3:在臨時表裡從sys.dm_io_virtual_file_stats捕獲磁碟I/O基線
代碼9.4展示對 #baseline表的查詢,對Person資料庫返回一些讀寫統計信息。
1 SELECT physical_name , 2 num_of_reads , 3 num_of_bytes_read , 4 io_stall_read_ms , 5 num_of_writes , 6 num_of_bytes_written , 7 io_stall_write_ms 8 FROM #baseline 9 WHERE databaseName = 'Persons'

代碼9.4:查詢#baseline臨時表。
已經提過,這個函數提供的數據是從伺服器上一次重啟後累積的,換句話說,數據列的值是不斷增長的,從上一次伺服器重啟的時間點。這樣的話,數據的單個“快照”並無用處,就本身來說。我們要做的是,建立一個“基線”標準,等待一定的時間,或許當一系列操作完成後,然後建立第二個“基線”並減掉,這樣的話,你會看到哪裡的I/O是增長的。
重新運行代碼9.1來更新我們的Persons表,並運行代碼9.5來收集第2批數據,減掉基線數據值(這裡我們從輸出忽略了一些列,為了可以更直觀的看結果)。
1 WITH currentLine 2 AS ( SELECT DB_NAME(mf.database_id) AS databaseName , 3 mf.physical_name , 4 num_of_reads , 5 num_of_bytes_read , 6 io_stall_read_ms , 7 num_of_writes , 8 num_of_bytes_written , 9 io_stall_write_ms , 10 io_stall , 11 size_on_disk_bytes , 12 GETDATE() AS currentlineDate 13 FROM sys.dm_io_virtual_file_stats(NULL, NULL) AS divfs 14 JOIN sys.master_files AS mf 15 ON mf.database_id = divfs.database_id 16 AND mf.file_id = divfs.file_id 17 ) 18 SELECT currentLine.databaseName , 19 LEFT(currentLine.physical_name, 1) AS drive , 20 currentLine.physical_name , 21 DATEDIFF(millisecond,baseLineDate,currentLineDate) AS elapsed_ms, 22 currentLine.io_stall - #baseline.io_stall AS io_stall_ms , 23 currentLine.io_stall_read_ms - #baseline.io_stall_read_ms 24 AS io_stall_read_ms , 25 currentLine.io_stall_write_ms - #baseline.io_stall_write_ms 26 AS io_stall_write_ms , 27 currentLine.num_of_reads - #baseline.num_of_reads AS num_of_reads , 28 currentLine.num_of_bytes_read - #baseline.num_of_bytes_read 29 AS num_of_bytes_read , 30 currentLine.num_of_writes - #baseline.num_of_writes AS num_of_writes , 31 currentLine.num_of_bytes_written - #baseline.num_of_bytes_written 32 AS num_of_bytes_written 33 FROM currentLine 34 INNER JOIN #baseline ON #baseLine.databaseName = currentLine.databaseName 35 AND #baseLine.physical_name = currentLine.physical_name 36 WHERE #baseline.databaseName = 'Persons' ;

代碼9.5:自基線衡量後,捕獲磁碟I/O統計信息。
在這個例子里,顯然我們強制了一些在日誌文件上,非常頻繁的寫活動!通常,找出高I/O積累的原因,並解決問題,是一個比較複雜的過程。如果你懷疑I/O積累率引起的問題,那麼行動的第一步是嘗試減少全局的I/O到可接受的級別。例如,我們可以從執行的或索引相關的DMV來使用數據,通過調優和索引優化來降低全局I/O。我們也可以增加記憶體量,這樣的話更多的資料庫會被緩存,這樣的話會減少物理文件都的併發。使用I/O停滯率和數據讀寫量,我們也可以使用分區,或者把表放到不同的文件組。
最終,不管怎樣,高的I/O停滯率直接意味著硬碟I/O子系統不足以處理需要的I/O輸出。如果不能把全局的I/O載入降到接受的級別,那麼只能嘗試增加更多或更快的硬碟,更多或更快的I/O路徑,或者調查下I/O子系統配置的潛在問題。
最後,記住這個DMV反饋的數據只是硬碟I/O的SQL Server角度的數據。如果磁碟子系統是共用的,在伺服器級別,有其他的應用,另一個應用可能會是拖垮硬碟性能的原因,而不是SQL Server。進一步說,SAN的使用,虛擬軟體等等,在SQL Server和具體的硬碟存儲之間常會有很多“中介”層。
簡答來說,在做出行動前,仔細分析從這個DMV獲得的數據,結合考慮下從系統計數器、Profile和其他DMV獲得的數據。
使用sys.dm_os_performance_counters
一般來說,如剛纔談到的,使用性能監視器(PerfMon)收集性能計數器最簡單。然而,如果你更喜歡在資料庫表裡保存統計信息,並用SQL在查詢的話,sys.dm_os_performance_counters這個DMV是個非常有用的工具。只要寫從這個DMV獲取數據的查詢,增加INSERT INTO CounterTrendingTableName...你就有了初步的監控系統!另外,你總不能直接訪問PerfMon,從不同的機器訪問它會很慢。
遺憾的時候,使用這個DMV並不一帆風順,它繁瑣的詳細介紹不是我們的討論範圍。不過,你可以看下這本可以免費下載電子書《使用DMV進行性能調優》來做參考。
代碼9.6簡單提供瞭如何在日誌增長或收縮事件上做報表的一個例子。
1 SET @object_name = CASE WHEN @@servicename = 'MSSQLSERVER' THEN 'SQLServer' 2 ELSE 'MSSQL$' + @@serviceName 3 END + ':Databases' 4 5 DECLARE @PERF_COUNTER_LARGE_RAWCOUNT INT 6 SELECT @PERF_COUNTER_LARGE_RAWCOUNT = 65792 7 8 SELECT object_name , 9 counter_name , 10 instance_name , 11 cntr_value 12 FROM sys.dm_os_performance_counters 13 WHERE cntr_type = @PERF_COUNTER_LARGE_RAWCOUNT 14 AND object_name = @object_name 15 AND counter_name IN ( 'Log Growths', 'Log Shrinks' ) 16 AND cntr_value > 0 17 ORDER BY object_name , 18 counter_name , 19 instance_name

代碼9.6:捕獲日誌增長和收縮事件
輸出結果表明Persons資料庫(初始日誌2MB日誌大小,自動增長率2MB)正遭受大量日誌增長事件,由於100萬條記錄的插入和在代碼9.2里的更新操作。這顯然是引起關註的原因,DBA需要調查下日誌大小和增長設置,很可能進行一次性的收縮,並調整為合適的大小,如第8篇所介紹的。
T-SQL和PowerShell腳本
對於SQL Server實例,你資料庫文件的大小和屬性,包括其他東西有很多腳本的方法來監控。這篇文章不會覆蓋所有的方法來收集這些信息,我們只談談我們需要知道的最好的。
T-SQL和SSIS
在Rodney Landrum的《SQL Server的釣魚盒》里,他提供了收集伺服器行為和資料庫信息的各種T-SQL腳本,包括日誌和數據文件增長。
- 伺服器信息——SQL Server名稱,SQL Server版本,排序信息等等。
- 資料庫管理——主要做到數據和日誌文件增長監控
- 資料庫備份——備份運行成功了麽?哪些資料庫在完整、簡單和大容量日誌模式?我們在進行完整恢複數據庫的日誌常規備份麽?
- 安全性——誰訪問了並做了什麼?
- SQL代理作業——哪個會包含這些運行你資料庫備份
然後他演示瞭如何自動化收集這些信息,在所有的伺服器間,使用SSIS,把它們保存到DBA專屬的資料庫里,用來檢查和分析。
如果這聽起來像你需要的方法,下載這個電子書,連同代碼,並使用它。
PowerShell
PowerShell,和伺服器管理對象,構成了一個管理和文檔化SQL Server資料庫的強大的自動化工具。對於DBA來說,學習T-SQL和可視化界面的管理工具,學習梯度很陡峭,但幾個短的腳本就可以在你的所有的伺服器和所有的資料庫版本間收集數據的所有行為。
接下來的2個腳本來自Phil Factor的《PowerShell伺服器管理對象:只寫一次》。
代碼9.7的PowerShell會列出SQL Server實例清單,在這些伺服器實例里檢查所有的資料庫,通過SMO(伺服器管理對象)列出:
- 日誌文件和路徑名稱
- 自動增長設置(KB或百分比)
- 當前文件大小(MB),已使用空間量(MB)和最大文件大小(MB)
- 硬碟讀數,硬碟寫數
- 從磁碟讀的位元組數,寫到磁碟的位元組數
直接修改腳本為你的伺服器實例名,從系統里的PowerShell里運行它。
1 #Load SMO assemblies 2 $MS='Microsoft.SQLServer' 3 @('.SMO') | 4 foreach-object { 5 if ([System.Reflection.Assembly]::LoadWithPartialName("$MS$_") -eq $null) 6 {"missing SMO component $MS$_"} 7 } 8 set-psdebug -strict 9 $ErrorActionPreference = "stop" # you can opt to stagger on, bleeding 10 # if an error occurs 11 12 $My="$MS.Management.Smo" 13 @("YourServerPath\InstanceName","MySecondServer") | 14 foreach-object {new-object ("$My.Server") $_ } | # create an SMO server object 15 Where-Object {$_.ServerType -ne $null} | # did you positively get the server? 16 Foreach-object {$_.Databases } | #for every server successfully reached 17 Where-Object {$_.IsSystemObject -ne $true} | #not the system objects 18 foreach-object{$_.Logfiles} | 19 Select-object @{Name="Server"; Expression={$_.parent.parent.name}}, 20 @{Name="Database"; Expression={$_.parent.name}}, 21 Name, Filename, 22 @{Name="Growth"; Expression={"$($_.Growth) 23 $($_.GrowthType)"}}, 24 @{Name="size(mb)"; Expression={"{0:n2}" –f 25 ($_.size/1MB)}}, 26 @{Name="MaxSize(mb)"; Expression={"{0:n2}" –f 27 ($_.MaxSize/1MB)}}, 28 NumberOfDiskReads,NumberOfDiskWrites, 29 BytesReadFromDisk,BytesWrittenToDisk | 30 Out-GridView

代碼9.7:使用PowerShell和SMO調查日誌文件大小,位置和活動。
我們在網格視圖裡顯示我們的輸出,並過濾了只顯示“persons”。如果你想輸出到Excel,把Out-GridView替換為:
1 Convertto-csv –useculture > Export.csv
如果你在SSMS里運行這個腳本,右擊伺服器或資料庫選擇【啟動PowerShell】。如果你使用的伺服器版本不止2012,那麼首先你要下載,導入並安裝sqlps模塊,這樣可以訪問Out-GridView和Convertto-csv cmdlets。可以參考下Michael Sorens的文章 ,2個選擇1個,替換掉最後行的FormatTable。
代碼9.8展示了第2個腳本,調查日誌文件碎片。同樣,在所有指定的資料庫實例上使用SMO來查詢每個資料庫。它通過T-SQL查詢了DBCC LogInfo來獲得每個日誌文件的VLF數。對於每個資料庫,它分組了虛擬日誌文件的結果個數,最大的VLF大小單位是MB,最小的VLF單位是MB,所有VLF的平均和總大小。這次我們使用FormatTable來作為輸出格式。
1 #Load SMO assemblies 2 $MS='Microsoft.SQLServer' 3 @('.SMO') | 4 foreach-object { 5 if ([System.Reflection.Assembly]::LoadWithPartialName("$MS$_") -eq $null) 6 {"missing SMO component $MS$_"} 7 } 8 set-psdebug -strict 9 $ErrorActionPreference = "stop" # 10 11 $My="$MS.Management.Smo" # 12 @("YourServerPath\InstanceName","MySecondServer") | 13 foreach-object {new-object ("$My.Server") $_ } | # create an SMO server object 14 Where-Object {$_.ServerType -ne $null} | # did you positively get the server? 15 Foreach-object {$_.Databases } | #for every server successfully reached 16 Foreach-object { #at this point you have reached the database 17 $Db=$_ 18 $_.ExecuteWithResults(‘dbcc loginfo’).Tables[0] | #make the DBCC query 19 Measure-Object -minimum -maximum -average -sum FileSize | 20 #group the results by filesize 21 Select-object @{Name="Server"; Expression={$Db.parent.name}}, 22 @{Name="Database"; Expression={$Db.name}}, 23 @{Name="No.VLFs"; Expression={$_.Count}}, 24 @{Name="MaxVLFSize(mb)"; Expression={"{0:n2}" –f 25 ($_.Maximum/1MB)}}, 26 @{Name="MinVLFSize(mb)"; Expression={"{0:n2}" –f 27 ($_.Minimum/1MB)}}, 28 @{Name="AverageVLF(mb)"; Expression={"{0:n2}" –f 29 ($_.Average/1MB)}}, 30 @{Name="SumVLF(mb)"; Expression={"{0:n2}" –f 31 ($_.Sum/1MB)}} 32 } | Format-Table * -AutoSize
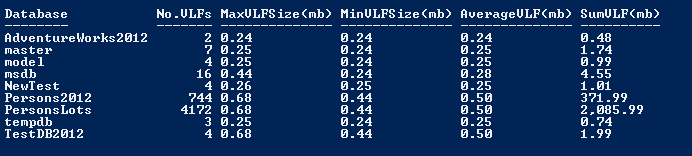
代碼9.8:使用PowerShell和SMO調查日誌碎片(從輸出已經忽略伺服器名稱)
小結
這個系列的最後一篇文章就回顧了對於日誌增長和性能監控,DBA可用的幾個工具,包括Windows的性能監視器,第三方工具,動態管理視圖(DMV),PowerShell和T-SQL腳本。我們努力提供了每個工具可用做的合理感覺,這樣的話,如果這個工具符合你需要的話,你可用進一步深入研究。
維持一個健康的事務日誌是每個DBA的基本職責。理想的,這會包括單個日誌文件,在特定的RAID 1+0的陣列(或接近你能獲得的最理想狀態),為了支持最大的寫性能和吞吐量。我們必須捕獲在典型工作負荷下,描述日誌寫性能的“基線”統計信息,然後多次監控這些數據,檢查不正常的活動,或性能里的突然惡化。
同樣,我們也要按當前和預見的數據量定義大小,而不是讓SQL Server”通過自動增長事件來管理日誌增長。我們應該啟用SQL Server的自動增長的便利性,但只作為一個保護措施,當日誌增長時,DBA應該收到一個警告,並去調查。通過仔細監控日誌增長,我們可以避免日誌滿的情形,或大量日誌碎片,它會降低日誌讀取的操作性能,例如日誌備份和故障恢復過程。
擴展閱讀
- 存儲測試和監控(視頻)
- 基線和基準測試(視頻)
- 回歸基本:在生產SQL Server上捕獲基線
- 診斷事務日誌性能問題和日誌管理器限制
- 監控SQL Server虛擬日誌文件(VLF)碎片
- 監控SQL Server資料庫事務日誌空間
- 系統數據收集集
- 未來——fn_dblog()不再?在Denali里跟蹤事務日誌活動
感謝
我們將感謝:
- Louis Davidson,為本文提供了DMO部分內容,讓我們可以參考他書里的材料來寫,他和Tim Ford一起寫了本書《使用SQL Server動態管理視圖進行性能調優》
- Phi Factor,為本文提供了PowerShell腳本


