
Hive是一個基於Hadoop的數據倉庫,最初由Facebook提供,使用HQL作為查詢介面、HDFS作為存儲底層、mapReduce作為執行層,設計目的是讓SQL技能良好,但Java技能較弱的分析師可以查詢海量數據,2008年facebook把Hive項目貢獻給Apache。Hive提供了比較完整 ...
Hive是一個基於Hadoop的數據倉庫,最初由Facebook提供,使用HQL作為查詢介面、HDFS作為存儲底層、mapReduce作為執行層,設計目的是讓SQL技能良好,但Java技能較弱的分析師可以查詢海量數據,2008年facebook把Hive項目貢獻給Apache。Hive提供了比較完整的SQL功能(本質是將SQL轉換為MapReduce),自身最大的缺點就是執行速度慢。Hive有自身的元數據結構描述,可以使用MySql\ProstgreSql\oracle 等關係型資料庫來進行存儲,但請註意Hive中的所有數據都存儲在HDFS中。雖然 hive 可能存在這樣那樣的問題,但它作為後續研究 sparkSql 的基礎,值得重點研究。
解釋一下經常遇到的 hiveServer1、hiveServer2 ? 早期版本的 hiveServer(即 hiveServer1)因使用Thrift介面的限制,不能處理多於一個客戶端的併發請求,在hive-0.11.0版本中重寫了hiveServer代碼(即 hiveServer2),支持了多客戶端的併發和認證,並且為開放API客戶端如JDBC、ODBC提供了更好的支持。
目錄:
- hive 架構
- 知識體系
- 數據類型
- Beeline
hive架構:

- 用戶介面主要有三個:CLI(command line interface)命令行,Client 和 Web UI, CLI是開發過程中常用的介面,在 hive Server2提供新的命令beeline,使用sqlline語法,會有單獨的章節來介紹
- metaStore: hive 的元數據結構描述信息庫,可選用不同的關係型資料庫來存儲,通過配置文件修改、查看資料庫配置信息,如下圖(/etc/hive/2.4.2.0-258/0/hive-siet.xml)

- Driver: 解釋器、編譯器、優化器完成HQL查詢語句從詞法分析、語法分析、編譯、優化以及查詢計劃的生成。生成的查詢計劃存儲在HDFS中,併在隨後由MapReduce調用執行
- Hive的數據存儲在HDFS中,大部分的查詢、計算由MapReduce完成
知識體系:
- 包含shell命令語法、HiveQl語法、訪問方式等,如下圖:

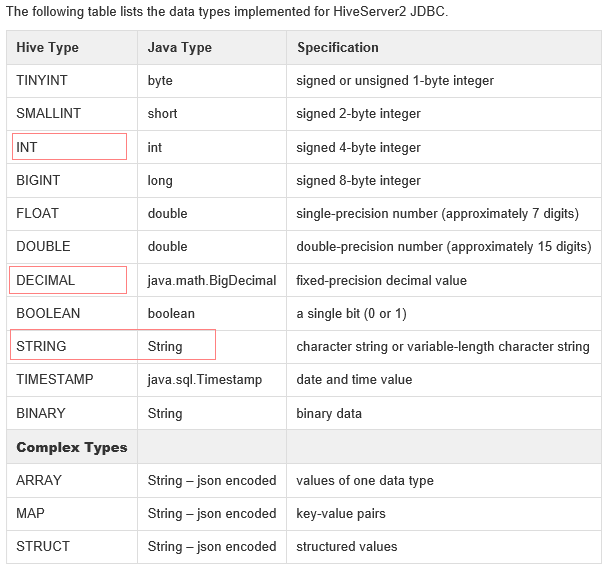
數據類型:
- hiveServer2支持以下數據類型,圖片來至 (https://cwiki.apache.org/confluence/display/Hive/HiveServer2+Clients)
Beeline:
- HiveServer2提供了一個新的命令行工具Beeline,它是基於SQLLine CLI的JDBC客戶端。
- 命令: cd /usr/hdp/2.4.2.0-258/hive/bin (切換至hive安裝bin目錄), 通過 beeline 命令進入beeline shell
- beeline 啟動常用參數說明:
- -u<database URL>: 通過 JDBC 訪問資料庫的 Url 地址
- -n <username>: 訪問資料庫的用戶名
- -p <password> : 訪問資料庫密碼
- -e <query>:Sql 語句執行參數 beeline -e "query_string"
- -f <file>: sql文件執行參數, beeline -f filepath
- --color=[true/false]:Control whether color is used for display. Default is false
- --help:幫助
- 命令: beeline
- 進入 beeline 命令行後,連接資料庫 : !connect jdbc:hive2://localhost:10000/default
- 輸入用戶名和密碼,進入 beeline shell
- sqlline 語法: !quit 退出beeline (不要帶分號)
- 多行命令用 ";" 分隔, 註釋: “ -- ” (在裡面執行的sql語句要帶分號)

